What is Apache Drill?
Apache Drill is an open-source SQL query engine for Big Data exploration that delivers fast services with security. Apache Drill is an upgraded version of the Apache Scoop.
Apache Drill is designed from the basic level to support high-performance analysis on the semi-structured and continuously evolving data coming from modern Big Data applications. A Drill is providing plug-and-play integration with existing Apache Hive and Apache HBase deployments.
Apache Drill has a low latency schema-free query engine for big data. The Drill uses a JSON document model internally which allows it for query data of any structure. The Drill works with a variety of non-relational data storage like Hadoop, NoSQL databases (MongoDB and HBase) and cloud storage like Azure Blob Storage, Amazon S3, etc. Users can query the data using standard SQL and BI Tools, which is not required to create and manage schemas.
Advantages of Apache Drill
There are some most important benefits of the Apache Drill:-
- Apache Drill can scale data from a single node to thousands of nodes and query computing of data within seconds.
- Apache Drill supports the user-defined functions.
- Apache Drill has the symmetrical architecture, and simple installation that's makes it easy to operate a very large cluster.
- Apache Drill has a flexible data model and extensible architecture.
- Apache Drill resemble execution model performs SQL process on complex data without admiring rows.
- Apache Drill Support large data sets.
Key Features of Apache Drill
There are some most significant key features of Apache Drill:-
- Apache Drill is suitable for being plugged architecture that enables connectivity to the multiple data stores.
- Apache Drill is a distributed execution engine for processing queries. Users can submit requests to any node in the cluster.
- Apache Drill supports complex and multi-structured data types.
- Apache Drill is used for self-describing data where a schema is specified as a part of the data itself, so there is no need for centralized schema management or definitions.
- Flexible deployment options, either cluster or local node.
- We have specialized memory management that reduces the amount of main memory, which is used by the program while running. It eliminates garbage collections.
- Apache Drill provides Decentralized data management.
Need of Apache Drill
Apache Drill has a flexible data model, and it does not need to transform either at the design time or at the run time, which provides high performance for queries. Apache Drill is used to scale big data, and there is no restriction on the availability of memory for the cluster of nodes.
Architecture of Apache Drill
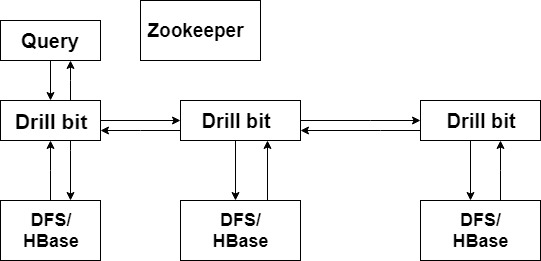
The above diagram consists of different components.
Let’see all the components in brief
- Query: Any Drill client issues the query.
- Drill bit: It is accepting the request from the client and processing the query and returns the result to the client.
- Zookeeper: It gets the Drill bit nodes from the cluster zookeeper.
- DFS/HBase: It provides real-time random read and writes access.
Apache Drill Query Execution
When we submit a Drill query, a client sends the query in the form of an SQL statement to the Drillbit in the Drill cluster. A Drillbit is a process that running on each active Drill node which coordinates, plans, and executes queries, as well as distributes the work of query between the clusters to maximize data locality.
The below diagram represents the communication between clients, applications, and Drill bits:-
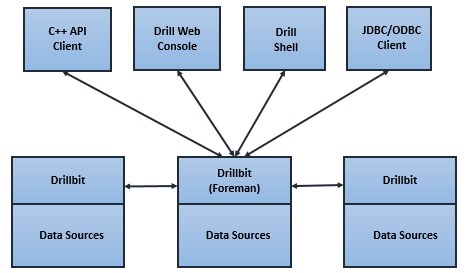
The
Drillbit receive the query from the client becomes the foreman and it run this entire query. The SQL applying the custom rules to convert specific SQL operators into a specific logical operator this syntax is Drill understandable. This collection of logical operators creates a logical plan.
The
logical plan describes the necessary work to generate query results and defines which data sources and operations to be applied.
The
Foreman sends the logical plan to the cost-based optimizer to optimize the order of SQL operators to read the logical plan. The optimizer applies various types of rules for rearrange functions and operators into an optimal plan. The optimizer converts the logical plan into the physical plan that describes how to execute the query.

A
parallelize in the Foreman transforms the physical plan into multiple phases. This is called a major fragment and minor fragment.These fragments create a multi-level execution tree that executes and rewrites the query in parallel.
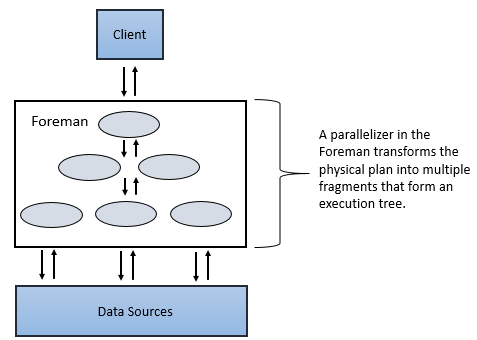
Major Fragment
Major fragments consist of one or multiple operations that Drill must perform to execute the query. The Drill is assigned to each major fragment a Major Fragment ID.
For example:
when we perform a hash aggregation of two files, Drill creates a plan with two major fragments where the first fragment is dedicated to scanning the two files and the second fragment is dedicated for aggregation of the data.

Drill uses an exchange operator to separate major fragment. An exchange allows moving the data between nodes.
The major fragment does not perform any query task. Each major fragment is divided into one or more minor fragments, and that performs the query task and returns the result to the Drill client.
Minor Fragment
Each major fragment is divided into minor fragment; a minor fragment is a logical unit of work that runs inside the thread. A logical unit of work is also called a slice. The execution plan that Drill creates is under the control of the minor fragments. Drill assigns each minor fragment a MinorFragmentID.
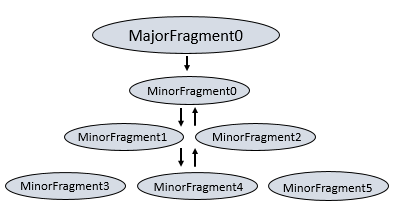
Drill executes each minor fragment in its thread based on its data requirements.
Minor fragments contain one or multiple relational operators. An operator performs a relational operation like scan, filter, join, group by.
A minor fragment is run as root, intermediate or leaf fragment. An execution tree contains only one root fragment. That coordinates of the execution tree are numbered from the root. Data flows downstream from the leaf fragments to the root fragment.
For example:
when we perform hash aggregation of two files,Drill breaks it into two phases the first phase dedicated to scanning into two minor fragments. Each minor fragment contains scan operators that scan the data. Drill breaks the second phase dedicated to aggregation into four minor fragments. Each of the four minor fragments contains hash aggregate operators that perform the hash aggregation operations on the data.
How to install Apache Drill
This tutorial helps you to download, install, and start working with Drill.You can install Drill to run in embedded mode on a machine running
Mac OS X, Linux or Windows. The Drill can introduce by using either an
embedded method or
distributed manner.
Let’s move step by step:
Installing Drill in embedded mode
If we want to use Drill on a single node, then we use embedded mode. Installing Drill by using the embedded method does not require the installation of Zookeeper.
There are some prerequisites for using the Drill in embedded mode:-
- Mac OS X, Linux, and Windows: - Oracle or Open JDK 8.
- For windows only-
- A JAVA_HOME environment variable that points to the JDK installation.
- A PATH environment variable that includes a pointer to the JDK installation.
- A utility for unzipping a tar.gz file.
Installation of Drill on Window
Drill supports 62-bit window only.
Tools Required
- Download and install JDK.
- Download and install a utility for unzipping a tar.gz file.
Setting up windows environment
Before downloading the Drill on the windows system, complete the following procedures:
Set the JAVA_HOME and PATH in environment variables
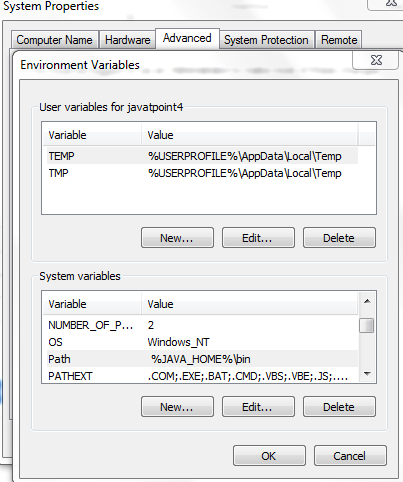
- Go to control panel.
- Go to system properties.
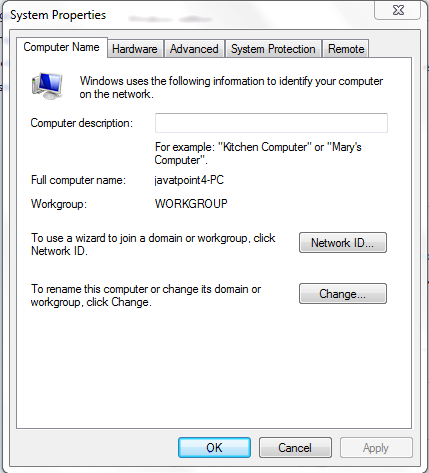
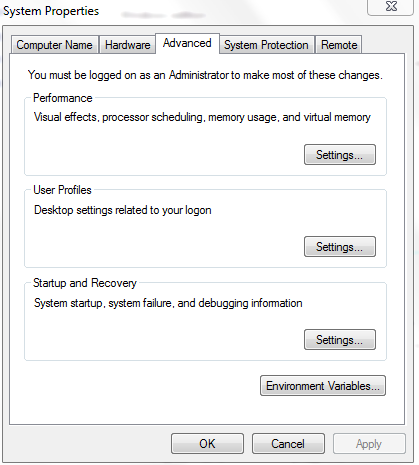
- Click on the advanced tab and then click on environment variables.
- Click New, and enter JAVA_HOME as the variable name. And join the path of JDK installation as the variable values.
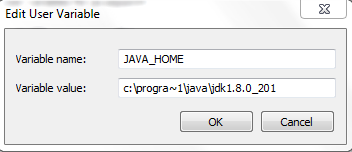
- Click OK to continue.
- In System Variables section, select Path and then click Edit.
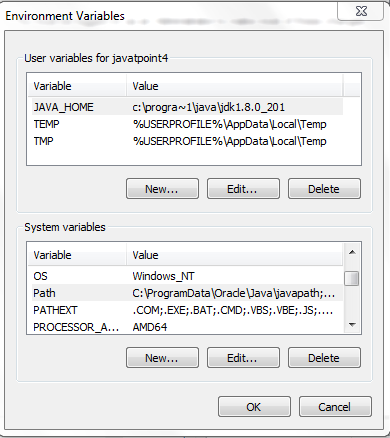
- In the Edit Environment Variable window, click New and enter %JAVA_HOME%\bin.
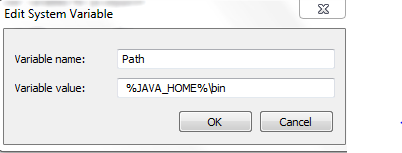
- Click OK to continue and exit.
Create Drilldirectories
- Run the command prompt as administrator, and write the following commands
mkdir "%userprofile%\drill"
mkdir "%userprofile%\drill\udf"
mkdir "%userprofile%\drill\udf\registry"
mkdir "%userprofile%\drill\udf\tmp"
mkdir "%userprofile%\drill\udf\staging"
takeown /R /F "%userprofile%\drill"
To verify that you will run Drill owns the directories, go to the "%userprofile%\drill"directory, right-click on it, and select Properties from this list.
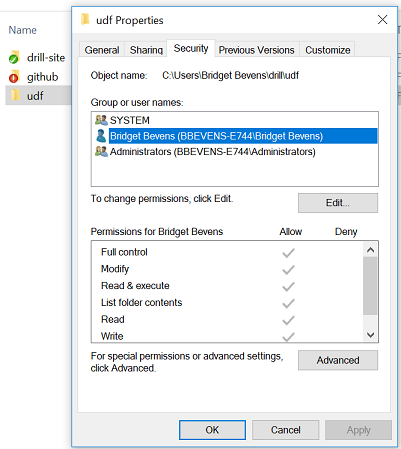
- Verify to you that you are the owner of all directories.
Download and install Apache Drill
- Download the Apache Drill with http://www-us.apache.org/dist/drill/drill-1.16.0/apache-drill-1.16.0.tar.gz
- Move the downloaded file to the directory.
- Unzip the GZ file using a third-party tool.
- Start Drill.
Installing Drill in distributed mode
If we want to use Drill on single or multiple nodes, then we use a distributed method to run in a cluster environment as well.
There are some prerequisites for using the Drill in distributed mode:-
- Running Oracle or OpenJDK 8.
- Running a Zookeeper.
- Running a Hadoop cluster.
- Using DNS.