What is Apache Flink?
Apache Flink is a distributed processing system for stateful computations over bounded and unbounded data streams. It is an open source framework developed by the Apache Software Foundation (ASF).
Flink is a German word which means Swift or Agile, and it is a platform which is used in big data applications, mainly involving analysis of data stored in Hadoop clusters. Flink is designed to run in all common cluster environments, performs computations at in-memory speed and at any scale. Apache Flink is written
in Java and
Scala.
Apache Flink streaming applications are programmed via DataStream API using either Java or Scala. Python is also used to program against a complementary Dataset API for processing static data.
Flink is a true streaming engine, as it does not cut the streams into micro batches like Spark, but it processes the data as soon as it receives the data.
Apache Flink is designed as an alternative to MapReduce. It is the batch-only processing engine which is paired with HDFS (Hadoop Distributed File System) in Hadoop’s initial incarnation. The latest version of Flink is
v1.8.0, which is released on April 9, 2019.
Process Unbound and Bound Data
Any type of data is produced as a stream of events, such as Sensor measurement, Credit card transactions, user interactions on the website or mobile application, or machine logs. All of these data are generated as a stream.
Data can be processed into two forms, which are:
- Unbounded streams
- Bounded streams.
- Unbounded streams
Unbounded streams have a start but no definite end. Unbounded streams do not terminate and provide the data as it is generated. It must be continuously processed, i.e., events must be immediately handled after they have been taken. Input is unbounded and will not be complete at any point of time, so it is not possible to wait for all input data to arrive.
- Bounded streams
Bounded data have defined start and end. It can be processed by ingesting all the data before performing any computation. To process bounded stream ordered ingestion is not required because bounded data set is always be sorted. Processing of bounded streams is also called as
batch processing.
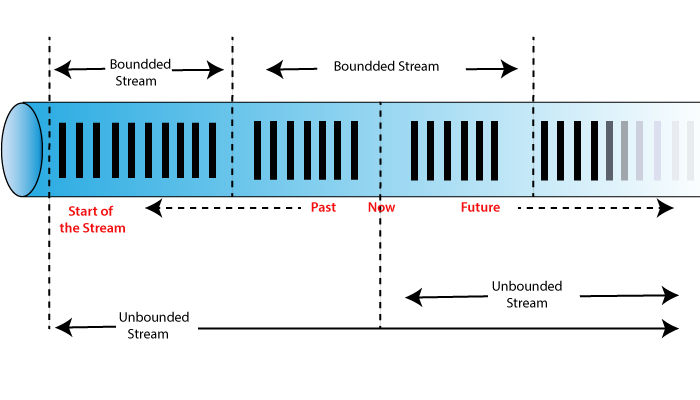
Apache Flink excels at processing at bounded and unbounded data sets. Precise control of state and time enables Flink’s runtime to run any application on unbound streams. Data structures and algorithms internally process bounded streams.
History of Apache Flink
In 2010, a research project “Stratosphere: Information Management on cloud” was started as a collaboration of Technical University Berlin, Hasso-Plattner-Institute Potsdam, and Humboldt-Universitat zu Berlin. Flink started from a branch of stratosphere’s distributed execution engine, and in March 2014, it became an Apache Incubator project. Flink accepted as an Apache top-level project in December 2014.
| Version |
Release Date |
Latest Version |
Release Date |
| 0.9 |
24-06-2015 |
0.9.1 |
01-09-2015 |
| 0.10 |
16-11-2015 |
0.10.2 |
11-02-2016 |
| 1.0 |
08-03-2016 |
1.0.3 |
11-05-2016 |
| 1.1 |
08-08-2016 |
1.1.5 |
22-03-2017 |
| 1.2 |
06-02-2017 |
1.2.1 |
26-04-2017 |
| 1.3 |
01-06-2017 |
1.3.3 |
15-03-2018 |
| 1.4 |
12-12-2017 |
1.4.2 |
08-03-2018 |
| 1.5 |
25-05-2018 |
1.5.6 |
26-12-2018 |
| 1.6 |
08-08-2018 |
1.6.3 |
22-12-2018 |
| 1.7 |
30-11-2018 |
1.7.2 |
15-02-2019 |
| 1.8 |
09-04-2019 |
1.8.0 |
09-04-2019 |
Apache Flink Ecosystem
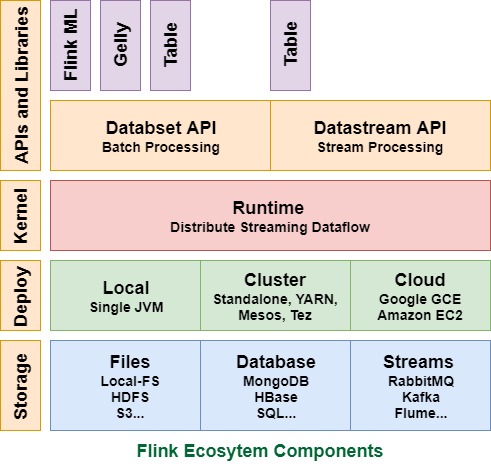
Below diagram shows a complete ecosystem of Apache Flink. Flink Ecosystem has different layers, which are given below:
 Layer 1:
Layer 1:
Flink is just a processing engine. There is no storage layer. Flink is dependent on third-party for storage. Flink can read the data from different storage systems. There is a list of storage systems from which Flink can read/write data.
- HDFS – Hadoop Distributed File system
- Local-FS – Local File System
- S3 – Simple Storage Service from Amazon
- RDBMS – Any Relational Database
- HBase – NoSQL Database in the Hadoop Ecosystem
- Flume – Data collection and Aggregation Tool
- Kafka – Distributing Messaging Queue
- MongoDB – NoSQL Database.
Layer 2:
The second Layer of Apache Flink is Deployment/ Resource Management. We can deploy Flink in these following modes:
- Local Mode - Flink can deploy on the local machine, i.e., on a single JVM. Local mode is used for development and testing purpose.
- Cluster – It works on the multi-node cluster with the following resource managers.
a) Standalone mode is a default resource manager which shipped with Flink.
b) YARN is a demanding resource manager. It’s a part of Hadoop which introduced in
Hadoop 2.x.
c) Mesos is a generalized resource manager.
- Cloud –We can deploy Flink on Amazon or Google cloud.
Layer 3:
Runtime is a core layer of Apache Flink. It is also known as kernel of Flink. Runtime is a streaming engine, which provides
fault tolerance, distributed processing, reliability, native iterative processing capability, etc.
Layer 4:
We have several APIs and libraries available at the top layer of the architecture. It provides a different capability to Flink.
Dataset API is used for the batch processing, and
DataStream API is used for stream processing.
This layer has some specialized components, such as
Flink ML for Machine Learning,
Gelly for graph processing, and
Table for SQL processing.
Following description is given for components and APIs of the fourth layer:
DataSet API allows the user to implement operations on the dataset like
filter, map, group, join, etc. It is mainly used for distributed processing.
Dataset API is a special case of Stream processing in which, we have a finite data source.
DataStream API manages a continuous stream of data. It provides various operations like
filter,
map,
update states,
aggregate,
window, etc., to process live stream data.
It can be embedded with DataSet and DataStream APIs. It helps users from writing complex code to process the data. It allows the users to run SQL queries at the top of Flink.
Gelly is a graph processing engine. It allows users to run a set of operation to create, process, and transform the graph. Its APIs are written in Scala and Java.
Flink ML uses for Machine Learning. Machine Learning algorithms are iterative. Apache Flink provides native support for iterative algorithm to manage them efficiently and effectively.
Apache Flink Architecture
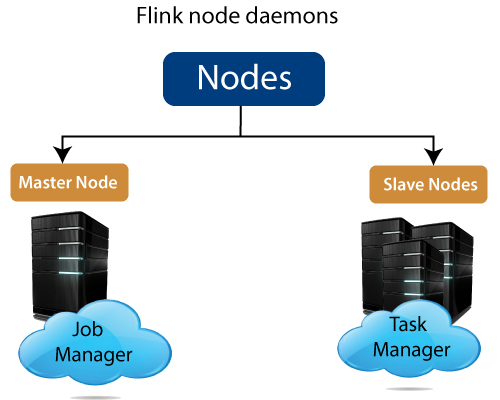
Apache Flink works in Master-slave manner. The slave is a worker node of the cluster, and Master is the manager node. As we can see in the figure that the client can submit the work application to Master, which is the centerpiece of the cluster. Now, the Master node will divide the work and submit it to the slave nodes. Flink enjoys the distributing computing power that allows Apache Flink to process the data at fast speed.
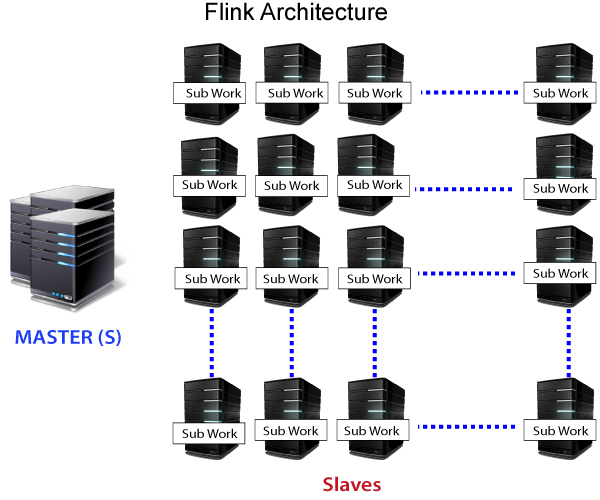
There are two types of node.
- Master node - We configure the master daemon of Flink called “Job Manager,” which runs on the master node.
- Slave node –Slave daemon of the Flink called as “Node Manager” runs on all the slave nodes.
Features of Apache Flink
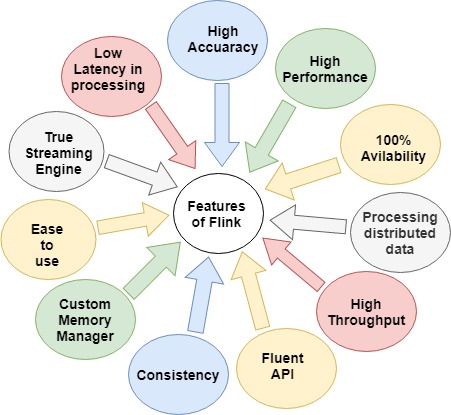
- Apache Flink provides high performance.
- Flink provides low –latency streaming engine and high throughput.
- It provides support for event-time processing and state management.
- Flink is accurate in data ingestion.
- By supporting the combination of in-memory and disk-based processing, Flink manages both batch and stream processing job.
- Applications of Flink are fault-tolerant in the event of machine failure.
- Flink has its own automatic memory manager.
Advantages of Apache Flink
- When compared to the micro-batching approach of Spark, Stream first approach of Flink provides better throughput of data and low latency in execution.
- In Spark, manual optimization required, whereas Apache Flink manages caching and data partitioning.
- For data analytics, Flink has Machine Learning Libraries (Flink ML), SQL style querying, graph processing, and in- memory computation.
How is Flink different from Apache Hadoop and Apache Spark?
Apache Flink uses
Kappa-architecture, the architecture which uses the only stream (of data) for processing, whereas, Hadoop and Spark use
Lambda architecture, which uses batches (of data) and micro-batches (of streamed data) for processing.
Difference between Apache Flink and Apache Spark
| |
Apache Flink |
Apache Spark |
| Definition |
It is an open source cluster for streaming and processing data. |
It is an open source cluster for big data processing. |
| Preference |
Flink is less preferred. |
Spark is more preferred and can be used along with Apache projects. |
| Graph Support |
Flink has Gelly for graph processing |
Spark has GraphX for graph processing. |
| Platform |
Cross-platform and application integration. |
It operated using third-party cluster manager. |
| Generality |
Apache Flink is an open source and gaining popularity recently. |
Spark is also an open source and is being used by many large scale data based companies. |
| Community |
The Community needs to grow. |
Slightly more user-based community. |
| Contributors |
Flink has a large base of contributions. |
Very large open source contributors. |
| Runtime |
It is slower than Spark. |
Runs processes 100 times faster than Hadoop. |
How to install Apache Flink
Flink can runs on Windows, Linux and Mac OS. We need to follow some steps on Linux, Mac OS as well as Windows environment:
- Verify Requirements
- Download the binary package of Apache Flink.
- Unpack the downloaded packets.
- Configure
- Start a local instance.
- Validate that the Flink is running.
- Run a Flink example.
- Stop the local Flink instance
Here, we will learn the installation process for Windows.
Prerequisite
- Java 1.8 or higher versions.
- Windows 7 or above.
Step 1: Before download, we have to choose a binary of Flink based on our requirements. If our data stored in Hadoop, download binary according to Hadoop version. Download the file from here.
https://flink.apache.org/downloads.html.
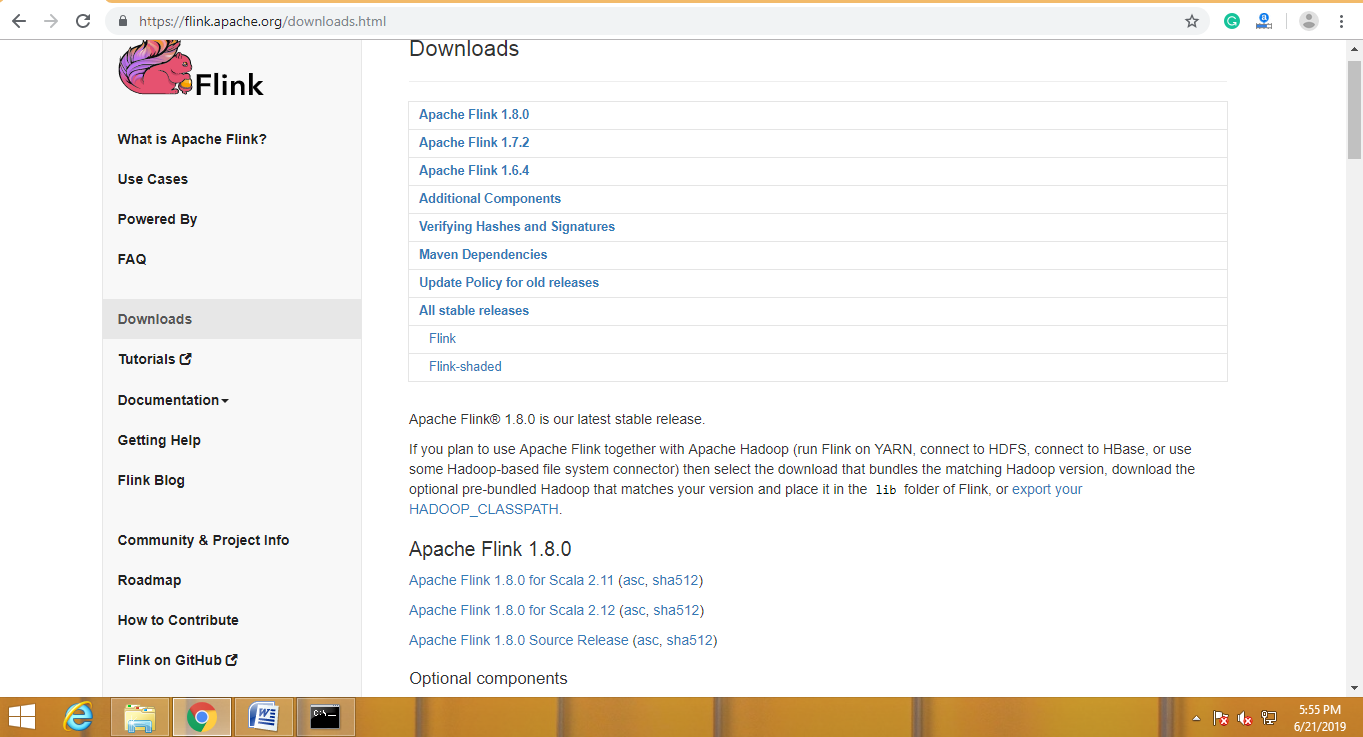 Step 2:
Step 2: Extract the downloaded bin package.
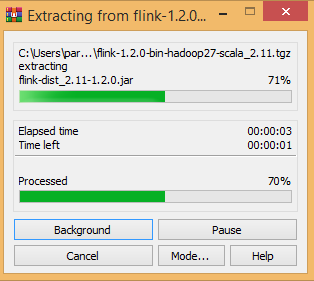 Step 3
Step 3: Set the path of Apache Flink. Go to This PC à Properties à Advanced system setting à Environmental variable à New, and create a new variable with name Flink_Home and copy the path of the bin folder of Apache Flink here.
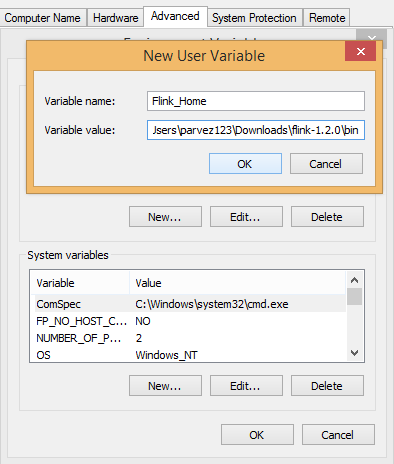 Step 4
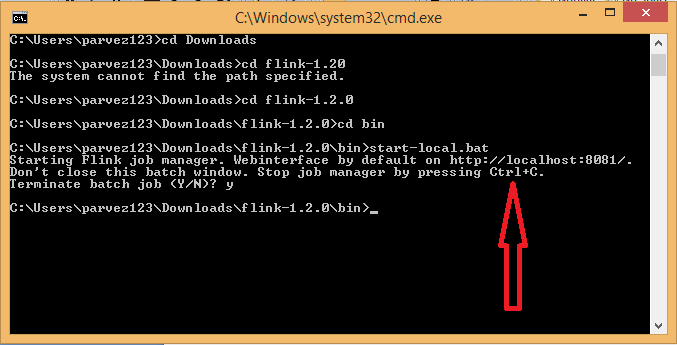
Step 4: Inside the bin folder start-local.bat has all the essential script to start the local cluster. To start the local cluster, navigate to the bin folder of Flink, i.e., /flink-folder.bin/ and open command prompt from the bin folder.
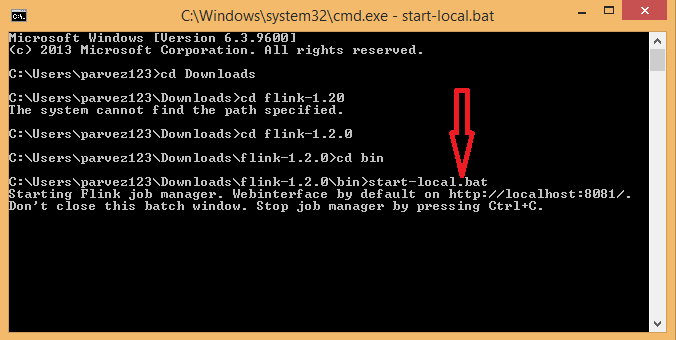
Run the command start-local.bat on command prompt.
Step 5: We can stop the local cluster by using the command
stop-cluster.bat or by pressing shortcut key
Ctrl+C.