Apache Flume Tutorial for Beginners
What is Apache Flume?
Apache Flume is distributed and reliable software. Apache Flume is a tool that is used for data ingestion in HDFS. It efficiently collects, aggregates, and moves a large amount of log data from various sources to a centralized data store.
Apache Flume use is not only restricted to the log data aggregation. Apache Flume can be used to transport massive quantities of event data because data sources are customizable.
For Example, Log files, events from various sources like social media, network traffic, and email messages can be transferred to HDFS (Hadoop Distribution File System).
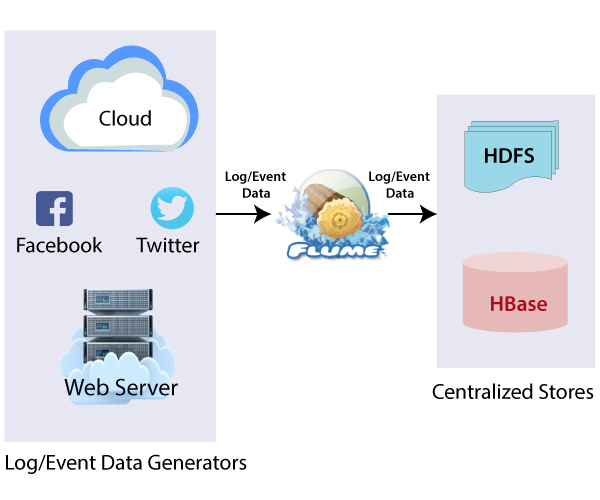
Apache Flume has a simple and flexible architecture that is based on streaming data flows. The main idea behind the Flume’s design is to capture streaming data from various web servers to HDFS. Flume is robust and faults tolerable. Apache Flume provides reliability mechanism for fault-tolerant and failure recovery.
Advantage of Apache Flume
There are various advantages of Apache Flume, which makes it a better choice than others.
- Apache Flume is reliable, customizable, fault tolerable, and scalable for different sources and sinks.
- Apache Flume supports a large number of sources and destination types.
- Apache Flume provides us a solution which is reliable and distributed. It also helps in collecting, aggregating, and transporting a large number of data sets.
- We can ingest the data from various servers into Hadoop using Flume.
- Apache Flume provides a steady flow of data between read and write operations if the read rate exceeds the write rate.
- Apache Flume helps to ingest online streaming data from multiple sources like network traffic, email messages, social media, log files, etc. into HDFS.
- Flume can store data in centralized stores such as HBase and HDFS.
Features of Apache Flume
- Apache Flume is open source. It is easily available.
- Apache Flume is horizontally scalable.
- Apache Flume provides a special feature of contextual routing.
- Apache Flume efficiently ingests the log data from several web servers to centralized stores like HDFS and HBase at a higher speed.
- Apache Flume is also used to import huge volumes of events data. This data is produced by social networking sites like Facebook, Twitter, and e-commerce websites like Amazon and Flipkart.
- It supports a large set of source and destination type.
- We can get the data from several servers immediately into Hadoop.
Limitation of Apache Flume
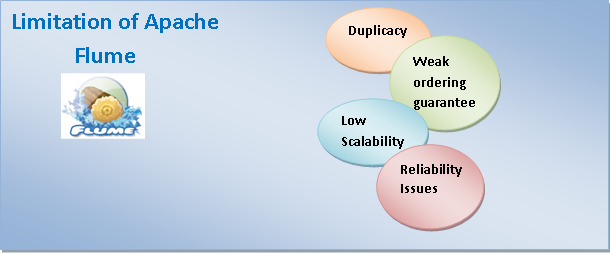
Duplicacy: In many cases, Apache Flume does not guarantee that the message will be unique. However, there is a possibility of duplicate message might be pop.
Weak ordering: Apache Flume is weak in ordering guarantee.
Low Scalability: There is a slight possibility that sizing of the hardware of a typical Flume can be tricky for an enterprise. Hence, the scalability aspect is low.
Reliability: Scalability and reliability is questionable when the choice of backing store is not chosen wisely.
Architecture of Apache Flume
There is a Flume Agent which consists of three main components, i.e., source, sink, and channel. Data generator such as Facebook and Twitter generate the data which is collected by individual Flume agents running on them. A data collector collects the data from the agents, which is aggregated and pushed into a centralized store (HDFS or HBase).
The underlying architecture of Apache Flume is as shown in the figure.
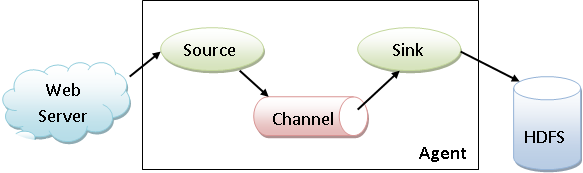
There are also some additional components of Apache Flume Agent.
- Flume Interceptors
- Flume sink processor
- Flume Channel selector
Flume Agent
An agent is an independent daemon process in Apache Flume. Flume Agent ingests the streaming data from various data sources to HDFS. Agent receives the data from the client or other agents and forwards it to its next destination (sink or agent). The Flume agent contains three main components, i.e., source, channel, and sink.
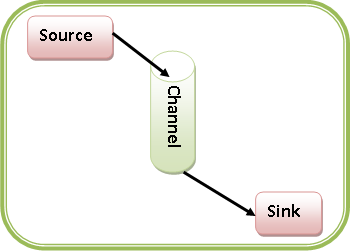
Components of Apache Flume
Source
Source is a component of Apache Flume. It receives the data from the data generator and stores the data in the channel in the form of Flume events.
Apache Flume supports multiple types of sources. Each source receives events from a specified data generator.
Example – Avro source, Thrift source, twitter 1% source etc.
Channel
Channel is temporary storage. Channel receives the events from the source and buffers them until they are consumed by sinks. It acts as a bridge between the source and the sinks. Channel can work with any number of sources and sinks.
Example - Memory channel, JDBC channel, and File system Channel, etc.
Sinks
The last component of Apache Flume is sink. Sinks stores the data into a centralized store such as HBase and HDFS. Sink accept the data from the channel and writes the data in HDFS permanently.
Example – HDFS sink
Note – Apache Flume can have several sources, channel, and sinks.
Additional Components of Apache Flume
1. Flume Interceptor
Apache Flume Interceptor is used to alter or inspect flume events which are transferred between the source and channel.
2. Flume Channel Selector
Flume channel selector is useful to determine that in case of several channels which channel we should select to transfer the data. Generally, there are two types of the channel selector.
- Default Channel Selector – Replicating channel selectors which replicate all the events in each channel.
- Multiplexing Channel Selector – It is a channel selector which decides the channel to send an event.
3. Sink Processor
To invoke a particular sink from the selected group of sink we generally sink processor. We also use the sink processor to create a failover path for our sink. It also used to load balance events across several sinks from a channel.
System Requirements
- Java Runtime Environment (JRE) – Java 1.8 or other latest versions.
- Memory – Sufficient memory for the configuration used by the sources, channel, or sinks.
- Directory Permission – Read/Write permissions for directories used by the agent.
- Disk Space – Sufficient disk space for the configuration used by channels and sinks.
- Hadoop – Hadoop is also required for Apache Flume.
How to download Apache Flume?
Apache Flume is distributed under the Apache License, version 2.0.
Step 1: We can download the latest version of Apache Flume from here http://flume.apache.org/download.html. Here, both binary and source distributions are available. Click on apache-flume-1.9.0-bin.tar.gz for binary distribution.
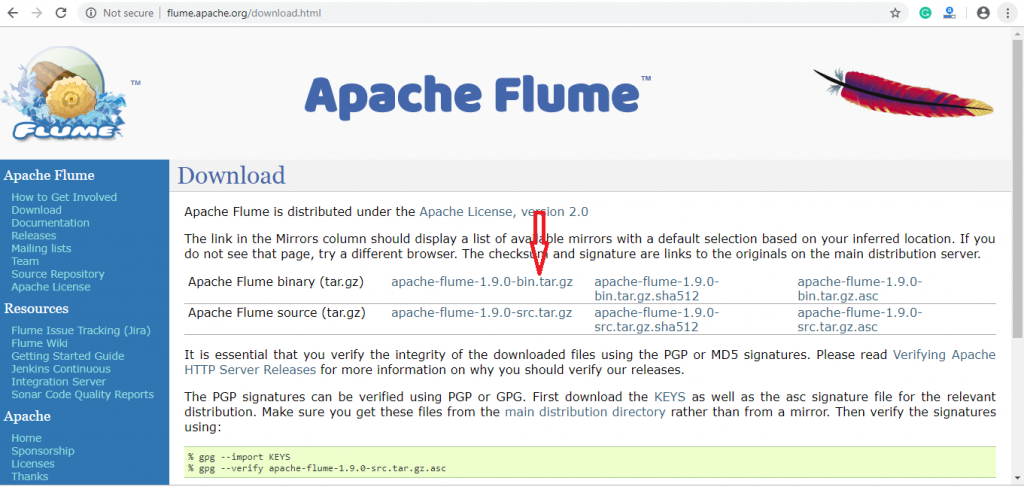
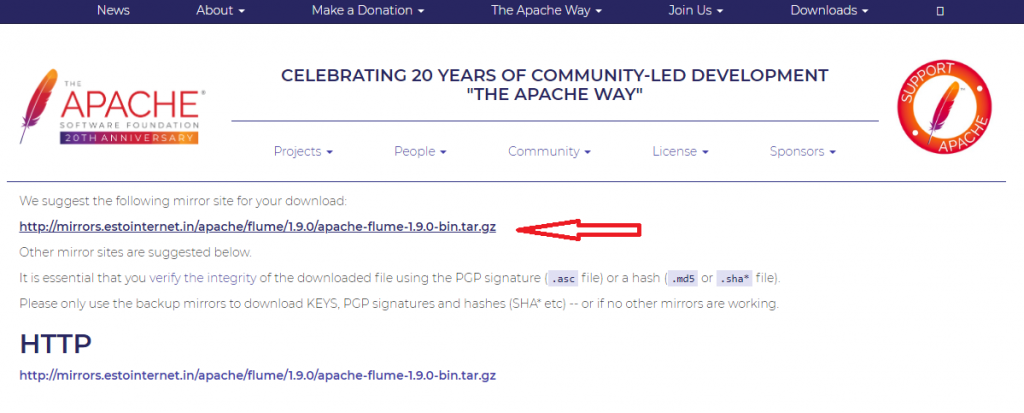
Step 2: Download the binary distribution from here. Similarly, you can download source distribution by clicking on apache-flume-1.9.0-src.tar.gz.
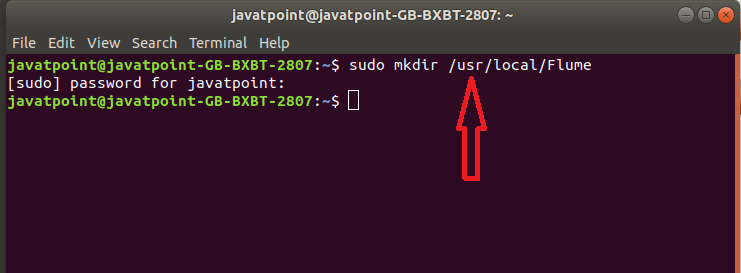
Step 3: Create a directory with name Flume in the same directory where the installation directories of Hadoop and HBase using this command.
$ mkdir Flume
Step 4: Now, we extract the downloaded tar file by using the given command.
$ sudo tar zxvf apache-flume-1.6.0-bin.tar.gz
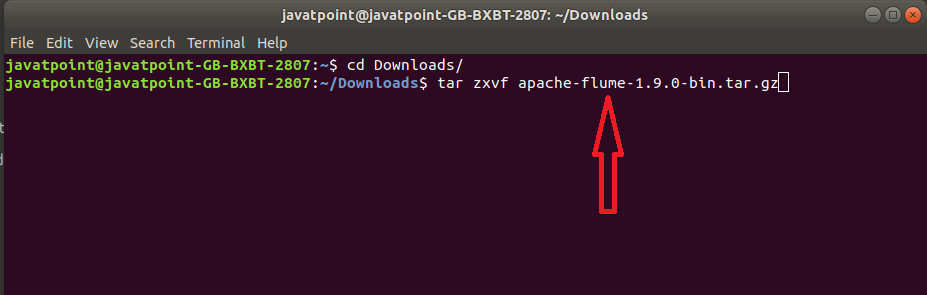
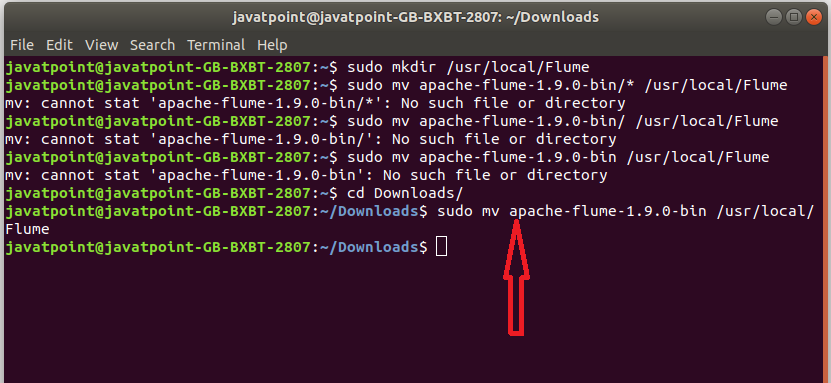
Step 5: Move the downloaded apache-flume-1.9.0-bin file to the Flume directory, which we created earlier.
syntax - $sudo mv source destination
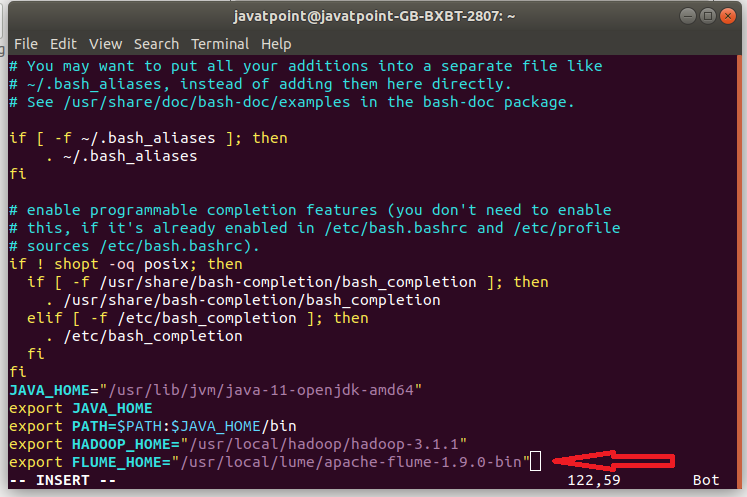
Step 6: Edit the .bashrc file using this command and set the path of Apache Flume.
$ nano .bashrc
Note: To verify that Apache Flume is successfully configured, execute the following command
$flume-ng –help