Apache Geode Tutorial for Beginners
Apache Geode is a real-time in the memory data grid, which can use for the cache. Apache geode cannot replace a traditional database and used for caching your data. Imagine, Geode, or Gem Fire is like a crucial In-memory value pair which can support JSON. Gem Fire cache can support JSON by default, and it is using the key-value pair for storing in the memory grid. We can do queries in the form of objects so; there is a concept of the continuous question. We can convert the data into the string which is from the in-memory cache.

Apache geode is designed for the low latency, and when we use it, we will see the difference between the traditional database and the in-memory database. If there is something in In- memory, it is going to give you very low latency. Same way apache geode or the Gem Fire are designed for the low latency all these are key-value pair, which are stored in the In-memory data grid.
So In-memory data grid is nothing but In-memory cache is different machines or the clusters which are connected in the form of network. Primarily, these are all interconnected, there is no ring if you have a ring, not all the node are related, but in the data grid you have the nodes interconnected, so it's an In-memory data grid. It is by default cloud-ready so you can move the Apache code to cloud by default any time and most probably it is like memory oriented so it has mind oriented features and you have an option way to write on a disk.
Apache geode is known as data management environment that provides reliable real-time access to data –accelerated application throughout extensively circulating cloud architectures. Geode pools memory, CPU, Network resources, and voluntarily local disk across multiple processes to manage demand, objects, and performance.
Apache geode is a mature, robust technology developed initially by Gemstone Systems. It is commercially available at Gemfire, and it was the first financial sector as the transactional, low-latency data engine used in Wall Street trading platforms. Today Apache Geode technology is used by many enterprise clients for large business applications that must meet low latency and 24x7 openings needs.
Crucial components of Apache Geode
There is a node in a geode circular System which is described by caches, an abstraction. Within each cache, we represent data fields. Data fields are similar to tables in a relational database and manage data in a distributed fashion as name/value pairs. A duplicate field store's identical copies of the data on each cache member of a circular system. A divided field increases the data among cache members. After the order is configured, client applications can access the distributed data in fields without knowledge of the underlying system architecture. We can define listeners to receive alerts when data has changed, and we can describe expiration criteria to delete obsolete data in a region.
Spotter provides both analysis and load balancing services. We configure clients with a list of spotter services, and the spotters manage a dynamic list of member servers. By default, Geode members and servers use port 40404 and multicast to finding each other.
Gem Fires core processing has been taken out from the Gem Fire code and then it has moved to the Apache foundation. So that is the apache geode, so apache geode is the core processing engine of the Gem Fire Cache. Gem Fire was developed by pivotal, so it was previously under VMware and not it got to move to crucial, so Gem Fire is now owned by central, and the core processing of the Gem Fire cache has been taken out and then proceed to be apache foundation so, the first version of apache geode came into November 2016. But the Gem Fire was in research for the past like ten years or something so, and Gem Fire was the initial. In memory data grid which people were researching on and then they had taken out the core processing of the Gem Fire cache and then they put it inside an open source foundation which is under Apache, which is called Geode.
So, Gem Fire is a product which pivotal sales and apache geode is an open source framework which we can use for creating Gem Fire, kind of cache so, most of the core processing is inside apache geode there is some additional feature inside Gem Fire.
Features of Apache Geode
- High Read and Write output
Geode uses coincidence main-memory data structures, and a large scale optimized circulate infrastructure to provide read-and-write output. Applications can create copies of data dynamically in memory through synchronous or asynchronous duplication for large-scale read output or dividing the data across many Geode system members to achieve high read-and-write throughput. Data are sharing doubles the aggregate production if the data access is a reasonable balance across the entire data set. The linear increase in performance is limited only by the backbone network capacity.
- Low and Easy to foretell latency
Geode’s maximize caching layer minimizes context switches between threads and processes. It manages data in highly parallel architecture to minimize contention points. Communication to peer members is contemporary if the receivers can keep up, which keeps the latency for data distribution to a minimum. Servers manage object graphs in the ordered form to decrease the strain on the garbage collector.
Geode divides offering arrangement (curiosity of registration and continuous queries) across server data stores, ensuring that acceptance is processed only once for all interested clients. The resulting enhancements in CPU use and bandwidth usage progress output and decrease latency for client acceptance.
- Highly Able To Climbed
Geode achieves scalability through dynamically dividing of data across a lot of members and increasing the data load uniformly across the servers. For "trending" data, we can configure the system to increase dynamically to create more copies of the data. We can also provide application behavior to run in a circulated manner in not allowed proximity to the data it requires.
If we require supporting high and unpredictable bursts of concurrent client load, we can increase the number of servers managing the data and distribute the data and behavior across them to provide uniform and predictable response times. Clients are repeatedly load balanced to the server farm based on frequent feedback from the servers on their load situations. With data partitioned and duplicated across servers, clients can dynamically move to various servers to uniformly load the servers and transfer the best response times.
We can also recover scalability by implementing asynchronous "write-behind" of data changes to external data stores, like a database. Geode avoids an obstacle by queuing all updates in order and unnecessary. We can also conflate updates and propagate them in batch to the database.
- Constant availability
In adjoining to assurance consistent copies of data in memory, applications can persist data to disk on one or more Geode members synchronously or asynchronously by using Geode’s “shared nothing disk architecture.” All asynchronous incidents (store-forward incident) are unnecessarily arranged in at least two members such that if one server fails, the extravagant are over. All clients relate to logical servers, and the client fails over automatically to proxy servers in a group during failures or when servers become unresponsive.
- Trustworthy Event alerts
Publish/contribute systems offer a data-distribution service where new events are published into the system and routed to all interested subscribers stably. Traditional messaging platforms support message delivery, but often, the receiving applications need access to related data before they can process the event. It requires them to access a standard database when the game is delivered, limiting the subscriber by the speed of the database.
Geode proposals data and events through an individual system. Data managed as objects in one or more spread data fields, similar to tables in a database. Applications insert, update, or delete objects in data regions, and the platform delivers the object changes to the contributor. The donor receiving the event has direct access to the related data in local memory or can fetch the data from one of the other members through a single hop.
- Coordinately Application Attitude On Data Stores
We can execute application business logic in a coordinate on the Geode clients. Geode’s data-aware function-execution service allowance execution of arbitrary, data-dependent application functions on the members where the data is a partition for the locality of reference and scale.
By collecting the relevant data and parallelizing the calculation, you increment overall output. The estimated latency is inversely proportional to the number of members on which it can be correlated.
The basic premise is to route the function transparently to the application that carries the data subset needed by the purpose and to ignore moving data around on the network. Application function can be run on only one member, in correlate on a subset of members, or side across all members. This programming model is similar to the favorite Map-Reduce model by Google. Data-aware routing purpose is most appropriate for applications that need iteration over multiple data items (such as a query or custom aggregation function).
- Dividend- Nothing Disk perseverance
Every Geode system associate arranges data on disk files self-sufficient of another associate. The collapse in disks or cache collapse in one associate does not affect the ability of another cache instance to operate securely on its disk files. This "shared nothing" persistence structure allows applications to be configured such that different classes of data are persisted on various members across the system, dramatically increasing the overall throughput of the claim even when disk persistence is built for application items.
A traditional database system, Geode does not arrange data and transaction logs in hidden files. All data updates are attached to files that are the same as transactional records of traditional databases. You can avoid disk-seek times if other processes do not concurrently use the disk, and the only cost incurred is the rotational latency.
- Decrease Charge Of Ownership
We can build caching in tiers. The client application method can host a cache nearby (in memory and overflow to disk) and representative to a cache server. Thirty percent hit ratios on the regional cache interpret to symbolic accumulation in costs. The total price associated with every single transaction comes from the CPU cycles spent, the network cost, the access to the database, and intangible costs associated with database maintenance. By arranging the data as application objects, you escape the extra charge (CPU cycles) associated with mapping SQL rows to objects.
- Individual-Hop Ability To Perform for applicant/ Server
Clients can send individual data appeals directly to the server holding the data key, avoiding multiple hops to establish data that is divided. Metadata in the client classifies the correct server. This behavior improves performance and client access to divide fields in the server tier.
- Client-Server Protection
Geode supports running multiple, definite users in customer applications. This feature contains installations in which Geode applicants are embedded in application servers, and every application server supports data appeals from various users. Each user may be authenticated to access a small subset of data on the servers, as in a customer application where every customer can access only their arrangements and shipments. Each user in the client relationship to the server with its own set of credentials and has its access authorization to the server cache.
Client/server connection has increased security against replay attacks. The server sends the client a single, random modifier with each response to be used in the next client request. Because of the id, even a repeated client operation call is sent as a single request to the server.
- Multisite Data Circulation
Scalability can result from data sites being spread out geographically across a wide-area network (WAN). Gem Fire provides a model to address these topologies, ranging from a single peer-to-peer cluster to reliable communications between data centers across the WAN. This model permits circulated systems to scale out in an unbounded and loosely coupled without loss of performance, reliability, or data consistency.
At the core of this structure is the gateway sender configuration used for distributing region events to a remote site. You can deploy gateway shipper instances in parallel, which authorize Gem Fire to increase the throughput for distributing region events across the WAN. We can also build gateway sender rows for persistence and high availability to avoid data loss in the case of a member defeat.
- Endless Querying
In messaging systems such as Java Message Service, clients contribute to points and rows. Any message transfer to a topic is sent to the donor. Geode permits continuous querying by having applications express compound interest using Object Query Language.
Fundamentals and Architecture of Apache Geode
Geode’s management and monitoring system consist of one JMX Manager node (there should only be one), and one or more managed nodes within a distributed network. All members in the circulated system are controllable through MBeans and Geode Management maintenance APIs. The following figure explains the structure of arrangements and monitoring system constituent.
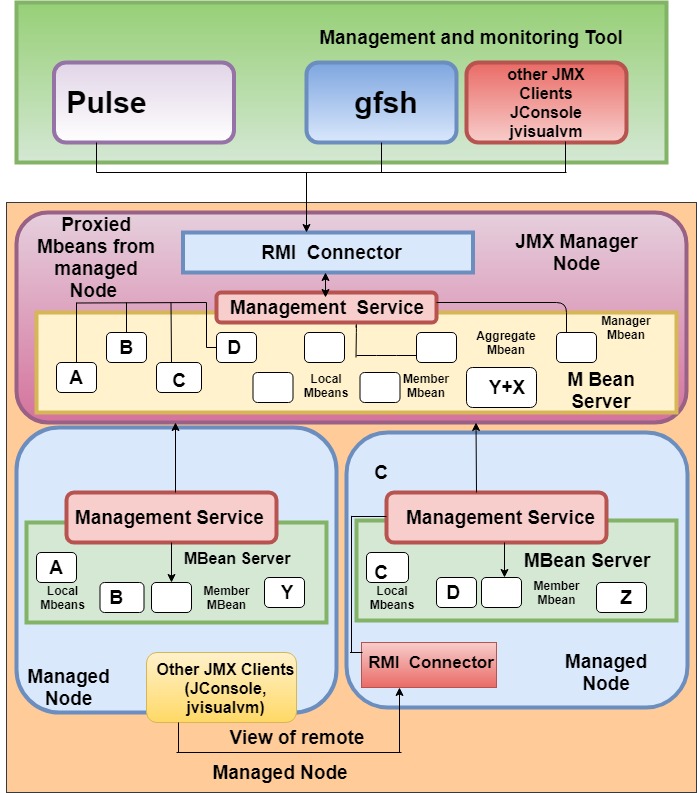
Implementation of Apache Geode-
The implementation of Apache Geode is depends on the isolation through ThreadLocal. For each entry we should implement the resolver by the using getRoutingObject method for return routing object, the hash of returning routing object resolves the bucket. These two steps are initial points to implementation of Apache Geode:
- Copy existing reference in ThreadLocal.
- Perform conflict check under lock at commit time.
The Geode can implement the continuous querying, we are able to run updated queries on the server by continues querying from clients to receive updates. There is an OQL query use in Apache Geode which is use to retrieve the data from the server according to our need.
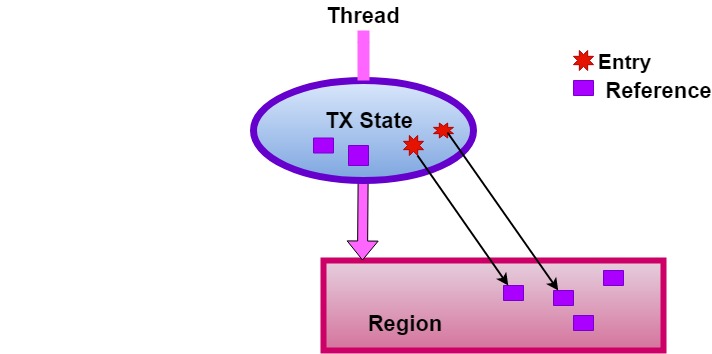
The Above Diagram describes the implementation of the Apache Geode, which is implemented according to this Diagram. The OQL query must satisfy some CQ requirements in addition which are given following:
- The single region specification must in FROM clause, for the operational iterator variable.
- The query is in the SELECT expression, and preceeds by zero or we can IMPORT statements.
- Here, we are discuss some terms, which cannot use the CQ query:
Cross region joins
Drill- downs into nested collections
DISTINCT
Projections
Bind Parameters
Installation of Apache Geode
Step 1:
First we need to install Apache Geode here and we can create source on UNIX, Configure the source on windows or we can install binaries from .zip or .tar files.
Create from Source on UNIX
- Set the JAVA_HOME environment variable.
- JAVA_HOME=/usr/java/jdk1.8.0_60
- export JAVA_HOME
- Download the project source from the URL: http://geode.apache.org, and unpack the source code.
- Inside the directory containing the unpacked source code, configure without tests:
- $ ./gradlew build -Dskip.tests=true
Or, configure with the tests:
$. /gradlew build
- Verify the installation by call gfsh to print version information and exit. On Linux/Unix environment, the version will be the same as:
- $ cd geode-assembly/build/install/apache-geode
- $ bin/gfsh version
- v1.1.0
Configure the Source on Windows
- Set the JAVA_HOME to the environment variable. For example:
- $ set JAVA_HOME="C:\Program Files\Java\jdk1.8.0_60"
- Install Gradle, version 2.3, or a more recent version.
- Download the project source from Releases page found at http://geode.apache.org, and unpack the source code.
- Inside the folder containing the unpacked source code, build without the tests:
- $ Gradle build -Dskip.tests=true
Or, build with the tests:
$ Gradle build
- Verify the installation by invoking gfsh to print version information and exit.
- $ cd geode-assembly\build\install\apache-geode\bin
- $ gfsh.bat version
- v1.1.0
Install Binaries from .zip or .tar File
- Download the .zip or .tar file from the Releases page found at http://geode.apache.org.
- Unzip the .zip file or expand the .tar file, where path_to_product is an absolute path, and the file name will vary due to the version number. For the .zip format:
- $ unzip apache-geode-1.1.0.zip -d path_to_product
For the .tar format:
$ tar -xvf apache-geode-1.1.0.tar -C path_to_product
- Set the JAVA_HOME environment variable. On Linux/Unix platforms:
- JAVA_HOME=/usr/java/jdk1.8.0_60
- export JAVA_HOME
On Windows platforms:
Set JAVA_HOME=c: \ProgramFiles\Java\jdk1.8.0_60
- Add the Geode scripts to your PATH environment variable. On Linux/Unix platforms:
- PATH=$PATH:$JAVA_HOME/bin:path_to_product/bin
- export PATH
On Windows platforms:
Set PATH=%PATH%; %JAVA_HOME%\bin;path_to_product\bin
- To verify the installation, type gfsh version at the command line and note that the output lists the installed version of Geode. For example:
- $ gfsh version
- v1.1.0
For more detailed version instruction such as the date of the build, build number and JDK version being used, call upon:
$ get version --full
Step 2:
Now, we should start the locator of Apache Geode, we can use gfsh to start that locator. We should mention the member name at that time when locator is start if we are not declare the name of member so, gfsh will automatically pick a random member name. After that we should move forward to the next step.
Step 3:
In the third step we need to start pulse, this pulse application display the locator. The pulse is the web application that supports graphical dashboard for monitoring vital and real time achievement of Geode Clusters.
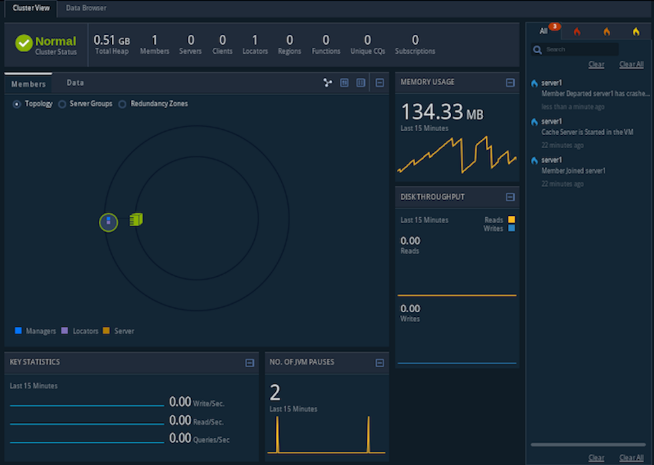
Step 4:
Now, we should start the Geode server. For this purpose we have to start cache server first, and the syntax for that is given following:
gfsh>start server --name=server1 --server-port=4041
This type of command is use for the cache server 1. The Geode server is mainly using for the host the long –lived data regions. The port number 4041 is mandatory to use for this purpose.
Step 5:
In this step we have to create the replicated persistence region. The command for this purpose is given following:
gfsh>create region --name=regionA --type=REPLICATE_PERSISTENT Member | Status ------- | -------------------------------------- server1 | Region "/regionA" created on "server1"
Step 6:
In this step, the data manipulation in the region and demonstrate the persistence. We can also use gfsh command to add and retrieve the data.
We can use put command to add some data and run the following:
gfsh>put --region=regionA --key="1" --value="one" Result : true Key Class : java.lang.String Key : 1 Value Class: java.lang.String Old Value: <NULL> gfsh>put --region=regionA --key="2" --value="two" Result: true Key Class : java.lang.String Key: 2 Value Class: java.lang.String Old Value : <NULL>
Step 7:
In this step we need to examine the effect of replication, we can start the second cache server because the region A is replicated. The command to start the second cache server is given following:
gfsh>start server --name=server2--server-port=40412
Step 8:
Restart the cache server in parallel, the data is persisted again the data is available when the servers restart. Due to replication you must start servers in parallel so that the data synchronization is processed before starting.
Step 9:
In this step, you have to shut down the system including the locators and the command is use for stop the cluster which is given following:
gfsh>shutdown --include-locators=true.