Apache Hama Tutorial
What is Apache Hama?
Apache Hama is a java based framework for Big Data analytics. It uses the Bulk Synchronous Parallel (BSP) computing techniques for massive scientific computations, e.g., matrix, graph, and network algorithms. It is a distributed computing framework inspired by Google’s Pregel large-scale graph computing framework described in 2010. Hama was established in 2012 as a Top-level Project of The Apache Software Foundation.Architecture of Apache Hama
Hama has three major componentsBSPMaster
Each time the BSPMaster receives a heartbeat message, it brings up-to-date groom server status. Then, BSPMaster makes use of groom servers’ status in order to assign tasks to idle groom servers effectively. After that, it returns a heartbeat response which contains assigned tasks and other actions that a groom server has to do. BSPMaster is responsible for:- Maintaining groom server status
- Controlling super steps in a cluster
- Maintaining job progress information
- jobs scheduling and assigning tasks to groom servers
- Controlling fault
GroomServer
A GroomServer is a process which performs BSP tasks assigned by BSPMaster. Each groom contacts the BSPMaster, takes assigned tasks, and reports its status to the master (BSPMaster) via periodic piggybacks called heartbeat messages. Each groom is designed to run with HDFS (Hadoop Distributed File System) or other distributed storages. The assigned task is run in a child Virtual Machine, which is spawned every time a new assignment comes. A groom server and a data node, both of them should be run on one physical node to achieve the best performance for data-locality.Zookeeper
A zookeeper manages the efficient barrier synchronization of the BSPPeers. It is also used for the area of a fault tolerance system.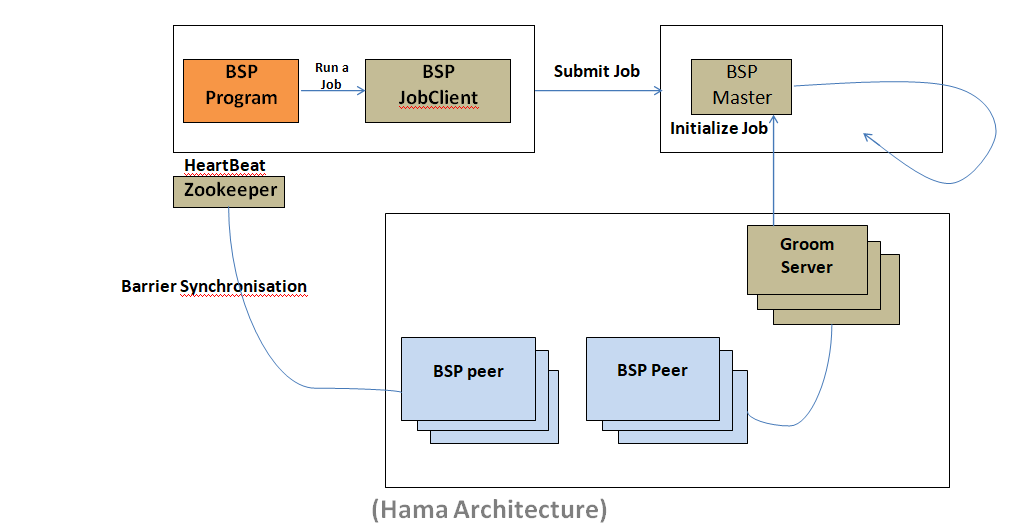
Process of Communication and Synchronization
Each BSP task consists of an Outgoing Message Manager and Incoming Queue. Outgoing Message Manager collects the message required to be sent, serializes it, compresses it and puts it in bundles. At the barrier synchronization phase, each BSP task is used to exchange, de-serialize, decompress the bundle and put it into the incoming queue.Why use Hama?
The task to efficiently process massive digital data is growing exponentially, which becomes increasingly challenging. Most of the big data projects are limited in their processing domain. However, Hama is a framework which supports diverse massive computational tasks and is more suitable for intensive iterative applications. It outperforms MapReduce frameworks in such application domains because it avoids the processing overhead of sorting, shuffling, reducing the vertices, etc. MapReduce inherits this overhead for each iteration and essentially there exist at least millions of iterations, whereas Hama provides a message passing interface, and each BSP superstep is faster than a full job execution in the MapReduce framework, such as Hadoop.Hama Implementation over Hadoop
Hama was implemented on top of Hadoop because of:- Hadoop framework has some limitations in several application domains, such as complex algorithmic computation, graph, and streaming data. Whereas, Hama uses BSP techniques for such computations.
- Hama can perform MapReduce feature in the same framework in parallel with the BSP engine.
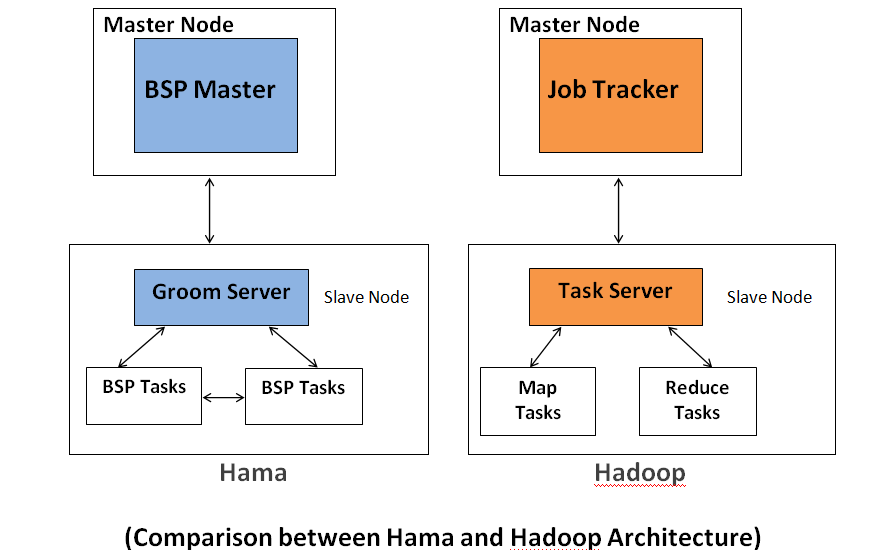 Each framework has respective advantages and disadvantages, and there is no single yardstick that truly embodies a one-size-fits-all solution.
Each framework has respective advantages and disadvantages, and there is no single yardstick that truly embodies a one-size-fits-all solution.
Advantages of Apache Hama
- Hama provides BSP primitives rather than graph processing APIs, which enable programmers to operate at a lower level.
- Hama uses BSP model to avoid conflicts and deadlines during communication.
- It provides not only the BSP programming model but also SQL-like query interface and vertex/neuron centric programming models.
- Hama manages to provide explicit support to message passing.
- It is primarily-Java based but also allows C++ programs.
- Hama is not limited to HDFS and may be used with any distributed file system.
- It supports general purpose computing on graphics processing units (GPGPU).
- Hama is an open-source software framework, and its source code is available for free to use. So, we can modify the source code as per our needs.
Disadvantages of Hama
- Hama uses graph partition strategy, which may have a negative performance impact because of the unnecessary communication between nodes.
- Hama was proposed in 2010, but it has not yet been widely adopted.
- Although Hama is an open-source framework, still it has no community support to communicate with the developers.
- Hama should have a better interface for the models that they readily support.
- Like any big data framework, Hama is also subject to security attacks and privacy issues, e.g., denial of service (DOS) attacks, or data use without permission.
Installation of Apache Hama
Preparations Make sure that you have installed all the required software on all nodes in your cluster:- Hadoop-1.0.x or higher version(non-secure version)
- Sun Java JDK 1.7.x or higher version
- SSH access to manages BSP daemons
- Download Hama from the release page: https://hama.apache.org/downloads.html
tar –xzf hama-0.x.0.tar.gzDon’t forget to choose the directory as the same user you configured Hadoop. Startup Script The $HAMA_HOME/bin directory contains some script which is used to start Hama daemons.
- Start-bspd.sh
- hama-env.sh
- groomservers
- hama-default.xml
- hama-site.xml
Setting up Hama
This section will help you to understand how to get started by setting up a Hama cluster.- BSPMaster and Zookeeper settings
% $HAMA_HOME/bin/start-bspd.shIt will start a BSPMaster, GroomServers, and Zookeeper on your machine. Stopping a Hama Cluster To stop the Hama Cluster, run the command:
% $HAMA_HOME/bin/stop-bspd.shIt will stop all the daemons running on your cluster. Enabling Fault Tolerance Service Fault Tolerance service remains disabled by default. To enable FT service, set properties like below:
<property> <name>bsp.ft.enabled</name> <value>true</value> <description>Enable Fault Tolerance in BSP Task execution.</description> </property> <property> <name>bsp.checkpoint.enabled</name> <value>true</value> <description>Enable Hama to checkpoint the messages transferred among BSP tasks during the BSP synchronization period.</description> </property> <property> <name>bsp.checkpoint.interval</name> <value>10</value> <description>If bsp.checkpoint.enabled is set to true, the checkpointing is initiated on the valueth synchronization process of BSP tasks.</description> </property>Hama Web Interfaces The web user interface provides information about BSP job statistics of the Hama cluster, running/completed/failed jobs. By default, it’s available at http://localhost:40013 For additional information, check out the Compatibility Table:
| Apache Hama Release Version | Apache Hadoop Release Version | Java | Known Compatibility Problems |
| 0.5.0 | 0.20.2, 0.20.2-cdh3u3b, and 1.0.x | 1.6 | None |
| 0.6.1 | 0.20.2, 0.20.2-cdh3u3b, and 1.x | 1.6, and 1.7 | None |
| 0.6.2 | 0.20.2, 0.20.2-cdh3u3b, and 1.x | 1.6, and 1.7 | None |
| 0.6.3 | Hadoop 0.20.x, 1.x, 2.x, and CDH3, CDH4 | 1.6, and 1.7 | Support only HDFS2 |
| 0.6.4 | Hadoop 0.20.x, 1.x, 2.x, and CDH3, CDH4 | 1.6, and 1.7 | Support only HDFS2 |
| 0.7.0 | Hadoop 1.x, 2.6+, and CDH3, CDH4 | 1.7+ | Support HDFS2Mesos and YARN |
(Compatibility Table)
By default, Hama 0.7 contains hadoop-2.7.0.jar files. If you are going to use lower or higher version of Hadoop, then you need to replace Hadoop jar files in the ${HAMA_HOME}/lib folder. To run with Hadoop 1.x, download ansrc-release tarball and build with the following command:%mvn clean install –Phadoop1 –Dhadoop.version=1.x.xRun Examples Hama provides examples packages that allow running examples on Hama cluster quickly. To run one of them, use command:
% $HAMA_HOME/bin/hama jar hama-examples-x.x.x.jarFor example: download an Iris dataset from here: http://people.apache.org/~edwardyoon/kmeans.txt And then, run K-Means using the command:
% $HAMA_HOME/bin/hama jar hama-examples-x.x.x.jar kmeans/tmp/kmeans.txt /tmp/result 10 3Conclusion If there is a lot of parallel processing for a massive amount of data, then it is a good idea to produce bulk synchronous programming models and use Apache Hama framework for the computations. Note: Apache Hama is an open source volunteer project under the Apache Software Foundation which encourage us to learn about the project and contribute our expertise. Moreover, it will help to stimulate interdisciplinary research and development in Hama to unleash its full potential.