What is Apache HAWQ?
Apache HAWQ can be described as an advanced Hadoop native SQL query engine. It includes the key technological advantages of MPP (Massively Parallel Processing) database with the scalability and convenience of Hadoop. It has tools to confidently and successfully interact with petabyte range data sets. It is a parallel SQL query engine built on top of the HDFS, claiming to be the world fastest SQL engine on Hadoop.
History of Apache HAWQ
Apache HAWQ was brought into the Apache Foundation from the well-established Pivotal HAWQ project. Pivotal developed HAWQ as a SQL query database that combined the merits of Pivotal Greenplum with Hadoop distributed storage. Pivotal contributed the Pivotal HAWQ core to Apache Foundation in September 2015. The historical changes can be described as:
- 2011: Prototype – GoH (Greenplum Database on HDFS)
- 2012: HAWQ Alpha
- March 2013: HAWQ 1.0 – Architecture changes for a Hadoopy system
- 2013~2014: HAWQ 1.x – HAWQ 1.1, HAWQ 1.2, HAWQ 1.3…
- 2015: HAWQ 2.0 Beta & Apache incubating – http://hawq.incubator.apache.org
- 2016: Oushu founded, focusing on HAWQ
- 2017: OushuDB 3.0 released: new SIMD executor
- 2018: HAWQ graduates as Apache Top Level Project
Why use HAWQ?
HAWQ reads data and writes data to HDFS (Hadoop Distributed File System) natively, which is fast. It delivers industry-leading performance and linear scalability. It provides users a complete, standards compliant SQL interface, which means HAWQ works with SQL-based applications and BI/data visualization tools. It can be used to execute complex queries and joins, including roll-ups and nested queries.
The original team of developers continued working on HAWQ project to make the product better, so it can run adequately on public cloud, private cloud, or shared physical cluster environments. Because of continuous development, it also works with the rest of the Apache Hadoop ecosystem products. It can be integrated and managed with Apache YARN provision with Apache Ambari, and interface with Apache HCatalog. It also supports Apache Parquet, Apache HBase, and works well with the Apache MADlib machine learning libraries for AI-based analytics. HAWQ divides complex queries into small tasks and distributes them to MPP query processing units for execution.
Architecture of Apache HAWQ
For a typical deployment, each slave node consists of one physical HAWQ segment, an HDFS DataNode, and a NodeManager. Masters for HAWQ (HDFS and YARN), are kept on separate nodes.
In HAWQ architecture, nodes can be added dynamically without data redistribution. Expansion takes only seconds. If there is a new node, it automatically contacts the HAWQ master, which performs to make the resources available on the node to be used for future queries immediately.
A diagram shows the high-level architectural view of a typical HAWQ deployment:
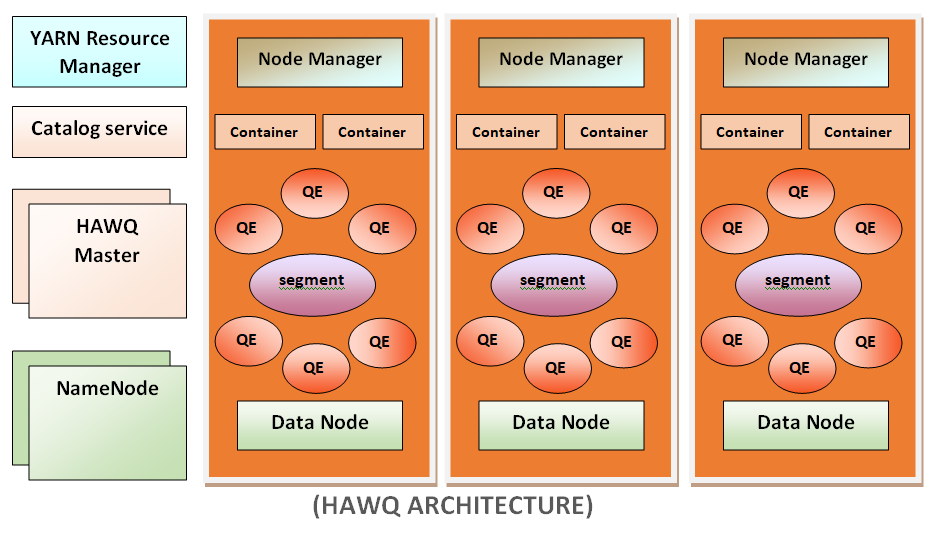
HAWQ is perfectly integrated with YARN for query resource management. It takes containers from YARN in a resource pool and manages those resources locally. It controls them by leveraging HAWQ’s own finer-grained resource management for users and groups. To get the query executed, HAWQ allocates a set of virtual segments according to the resource queue definitions, cost of a query, data locality, and the current resource usage in the system. After that, a query is dispatched to corresponding physical hosts, which can be a subset of nodes or the whole cluster. To avoid resource usage violations, HAWQ resource enforcer on each node monitors and controls the real-time resources used by the query.
Components of Apache HAWQ
A figure shows more details regarding the internal components of the newly redesigned HAWQ:
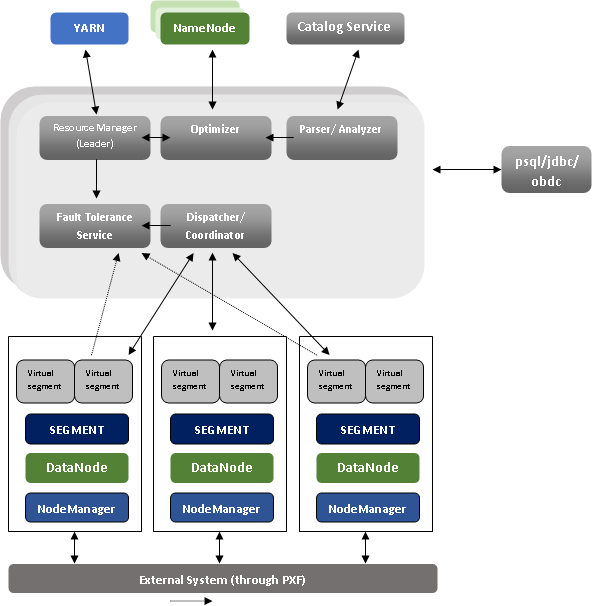
Components Highlights
The HAWQ master is an entry point to the system. It is the database process which accepts client connections and processes the issued SQL commands. The HAWQ master parses, optimizes, dispatches the queries to the segments and coordinates the query execution.
The HAWQ master is where the global system catalog exists. A global system catalog is the set of system tables which contain metadata about the HAWQ system itself. HAWQ master does not contain any user data; data exists only on Hadoop Distributed File System.
End-users can interact with HAWQ through the master. It can also join the database using client programs such as psql or application programming interfaces (APIs) such as JDBC or ODBC.
The segments are the units which are responsible for processing data simultaneously.
Each host consists of only one physical segment. Each segment can generate many Query Executors (QEs) for each query slice, which makes a single segment act like multiple virtual segments. It enables HAWQ to utilize all available resources to perform in a better way.
A segment is slightly different from a master because of:
- It is stateless.
- It does not keep the metadata for each database and table.
- It does not store data on the local file system.
Interconnect can be described as the networking layer of HAWQ. Whenever a user connects to a database and issues a query, an interconnect starts creating the processes on each segment to handle the query. The interconnect indicates to the inter-process communication between the segments, as well as the network infrastructure on which this communication exists. The interconnect uses standard Ethernet switching fabric.
The interconnect works with UDP (User Datagram Protocol) system to send messages over the network. The HAWQ checks for additional packet verification beyond what is provided by UDP. It indicates that the reliability is equivalent to the TCP (Transmission Control Protocol), and the performance and scalability exceeds that of TCP.
Resource management is key to supporting elasticity. HAWQ supports three-level resource management:
- Global Level: It is responsible for getting and returning resources from global resource managers, for example, YARN and Mesos.
- Internal Query Level: Internal Query Level is responsible for allocating acquired resources to different sessions and queries according to resource queue definitions.
- Operator Level: Operator level is responsible for allocating resources across query operations in a query plan.
The HAWQ resource manager takes the resources from YARN and communicates with resource requests. After that, Resources are buffered by the HAWQ resource manager so that it can easily support low latency queries; it can also be run in standalone mode.
HAWQ manages resources within resource queues. If a query is submitted, resources are obtained from HAWQ through libYARN, which is a C/C++ module in HAWQ that communicates with YARN. The resource allocation for each query is transferred with the plan together to the segments. Each Query Executor reads the resource quota for the current query and enforces the resource consumption during query execution. When query execution finishes (or is canceled) the resource is returned to HAWQ RM.
A figure shows the detailed processing of the Resource Manager and its components:
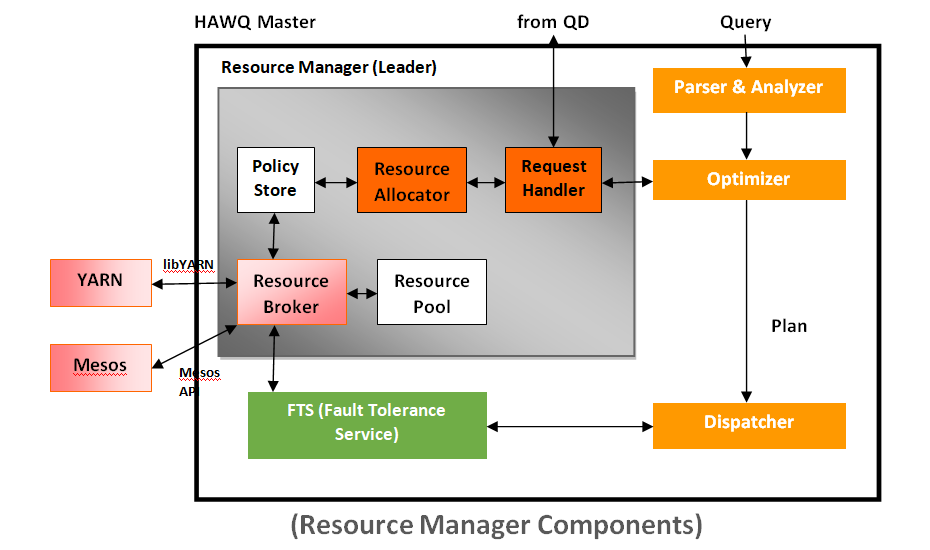
- Catalog Service: The HAWQ catalog service is used to store all metadata, such as UDF/UDT information, relation information, security information, and data file locations.
- Fault Tolerance Service: Fault Tolerance Service (FTS) detects segment failures. It is also used to accept heartbeats from segments.
- Dispatcher: HAWQ dispatcher dispatches the query plans to a selected subset of segments and coordinates the execution of the query. The HAWQ dispatcher is responsible for dispatching query plans to a selected subset of segments. It also coordinates the execution of the query. The dispatcher and the resource manager are known as the main components for the scheduling of queries dynamically and the resources required to execute them.
- YARN: It is a Hadoop resource management framework.
Features of HAWQ
HAWQ has the following feature:
- On-premise or cloud deployment
- Robust ANSI SQL compliance
- World-class parallel optimizer
- Full transaction capability and consistency guarantee
- Support for dynamic data flow engine through high-speed UDP based interconnect
- Elastic execution based engine for on-demand virtual segments and data locality
- Support for multiple level partitioning and List/Range based partitioned tables.
- Support for multiple compression methods
- Support for multi-language user-defined function: Python, Perl, Java, C/C++
- Provides advanced machine learning and data mining functionalities through MADLib
- Dynamic node expansion, in seconds
- Advanced three level resource management
- Easy access of all Hadoop Distributed File System data and external system data
- Authentication and granular authorization: SSL, Kerberos, and role-based access
- Support for most third-party tools
- Standard connectivity: JDBC/ODBC.
HAWQ Implementation over Hadoop
Most of the modern applications require to access the data directly in the HDFS. Many practitioners need SQL to interact with data in HDFS, as they are not well versed in MapReduce programming. Specifically, practitioners require advanced Hadoop Native SQL analytics with enterprise-grade processing capabilities. The following are the standard requirements from customers who are using Hadoop for their daily analytical work:
- Interactive queries: It is the key to help data exploration, rapid prototyping, and other tasks.
- Scalability: It is required for the explosive growth of data size.
- Consistency: Data consistency has some responsibilities which must be abstracted from application developers.
- Extensibility: A system must be supported by common, popular data formats, such as plain text, SequenceFile, and new formats.
- Standard Compliance: To get the most from existing BI and visualization tools, standard compliance is required with SQL and various other BI standards.
- Productivity: Advance productivity is needed with analytics skill sets.
In its starting state, Hadoop could not satisfy all of the given requirements. In the database community, one of the increasing trend is the wide adoption of MPP (Massive Parallel Processing) systems. HAWQ is true SQL compliant engine based on MPP history. It is a unique product with state of the art Query optimizer and dynamic partition elimination, robust HDFS data federation with the native Hadoop file system. With the YARN support and its acceptance as an Apache Foundation project, HAWQ is now more than ever a truly Hadoop Native SQL Database.
Installation of Apache HAWQ
Prerequisites
- Compatible HDFS Cluster should be installed.
- Download Apache HAWQ from here:
http://hawq.apache.org/#download
Prepare Host Machines
Configure OS parameters on each host machine before you begin to install HAWQ.
- Open a text editor and edit the /etc/sysctl.conf Add or edit each of the following parameter definitions to set the required value:
kernel.shmmax = 1000000000
kernel.shmmni = 4096
kernel.shmall = 4000000000
kernel.sem = 250 512000 100 2048
kernel.sysrq = 1
kernel.core_uses_pid = 1
kernel.msgmnb = 65536
kernel.msgmax = 65536
kernel.msgmni = 2048
net.ipv4.tcp_syncookies = 0
net.ipv4.conf.default.accept_source_route = 0
net.ipv4.tcp_tw_recycle = 1
net.ipv4.tcp_max_syn_backlog = 200000
net.ipv4.conf.all.arp_filter = 1
net.ipv4.ip_local_port_range = 1281 65535
net.core.netdev_max_backlog = 200000
vm.overcommit_memory = 2
fs.nr_open = 3000000
kernel.threads-max = 798720
kernel.pid_max = 798720
# increase network
net.core.rmem_max=2097152
net.core.wmem_max=2097152
Save it after making the changes.
- Execute the command to apply updated /etc/sysctk.conf file to the OS configuration:
$ sysctl -p
- Open a text editor and edit the file /etc/security/limits.conf. Add the given definitions in the exact order that they are mentioned below:
* soft nofile 2900000
* hard nofile 2900000
* soft nproc 131072
* hard nproc 131072
Save it after making changes.
- Use a text editor and edit the hdfs-site.xml Ensure that the following HDFS parameters are set as per given definitions:
| Property |
Setting |
| dfs.allow.truncate |
True |
| dfs.block.access.token.enable |
false if an unsecured HDFS cluster, or true if secure cluster |
| dfs.block.local-path-access.user |
gpadmin |
| dfs.client.read.shortcircuit |
true |
| dfs.client.socket-timeout |
300000000 |
| dfs.client.use.legacy.blockreader.local |
false |
| dfs.datanode.data.dir.perm |
750 |
| dfs.datanode.handler.count |
60 |
| dfs.datanode.max.transfer.threads |
40960 |
| dfs.datanode.socket.write.timeout |
7200000 |
| dfs.namenode.accesstime.precision |
0 |
| dfs.namenode.handler.count |
600 |
| dfs.support.append |
True |
- Again, edit the core-site.xml file and set the parameters as follows:
| Property |
Setting |
| ipc.client.connection.maxidletime |
3600000 |
| ipc.client.connect.timeout |
300000 |
| ipc.server.listen.queue.size |
3300 |
- Restart HDFS to apply the configuration changes.
- Make sure that the /etc/hosts file on each cluster node contains the hostname of every other member of the cluster. Create a single, master /etc/hosts file, and either copy it on every host which will take part in the cluster.
Add New HDB Software Repositories
Set up a local
yum HDB repositories on the single system (call it
repo-node) to host the HDB software. This system must be accessible by all nodes of HAWQ cluster.
After repo set up, each HAWQ host will be configured to achieve the HDB software from the
repo-node HDB repositories.
Install HAWQ Cluster on a Single Machine
Follow the instructions below to install HAWQ software on a single host machine:
- Log in to the main target machine as the root user. Switch to the root account using the below command if you are logged in as a different user:
$ su – root
- Create the gpadmin user account and set an appropriate password. For example:
$ /usr/sbin/useradd gpadmin
$ echo –e "changeme\changeme" | passwd gpadmin
- Install HAWQ using the command:
$ yum install –y hawq
- Switch to the gpadmin user:
$ su – gpadmin
- Source the sh file to set up the environment for HAWQ. For RPM installations, enter command:
$ source /usr/local/hawq/greenplum_path.sh
If downloaded file is in tarball format , substitute the path to the extracted
greenplum_path.sh file (for example
/opt/hawq-<version>/greenplum_path.sh).
- HAWQ requires direct SSH access to all cluster nodes without any password, even on a single-node cluster installation process. Run the following hawq command to exchange keys and enable passwordless SSH to localhost:
$ hawq ssh-exkeys –h localhost
- Turn off temporary password-based authentication (Optional).
- If HDFS Namenode does not use the default port, 8020, then open the $GPHOME/etc/hawq-site.xml file with a text editor and modify the following property definitions to use the actual Namenode port number:
<property>
<name>hawq_dfs_url</name>
<value>localhost:8020/hawq_default</value>
<description>URL for accessing HDFS.</description>
</property>
Make sure that the gpadmin user has both read/write access to the parent directory specified with hawq_dfs_url. For example:
$ hdfs dfs -chown gpadmin hdfs://localhost:8020/
- Now, use the following command to initialize and start the new HAWQ cluster:
$ hawq init cluster
Finally, Apache HAWQ is successfully started, and you can now validate the installation to ensure that the new cluster is functional. Also install PXF plug-ins if you are planning to access data in external systems such as HDFS or JSON files, Hive or HBase.
What did others say?
Apache HAWQ is currently in use at Alibaba, Haier, VMware, ZTESoft, and more than hundreds of users around the world. There are some feedbacks from satisfied users:
"
We admire HAWQ's flexible framework and ability to scale up in a Cloud eco-system. HAWQ helps those who are seeking a heterogeneous computing system to handle ad-hoc queries and heavy batch workloads," said by Kuien Liu, Computing Platform Architect at Alibaba.
"
Our Group has deployed clusters of more than 30 nodes in the production environment from the beginning of HAWQ," said by Xiaoliang Wu, Big Data Architect at Haier.
It shows that Apache HAWQ is accepted widely around the world.
Summary
The newly redesigned Apache HAWQ is loaded with powerful new features and functionalities designed to provide maximum value to practitioners. It allows administrators to:
- Increase workloads on existing clusters as a result of the new elastic runtime and resource management capabilities.
- Easily and dynamically scale-out HAWQ clusters to meet peak query demand periods
- Leverage YARN integration for advanced Hadoop cluster resource management.
For end-users, HAWQ aims to provide the required SQL analytics capabilities to get the most out of data in Hadoop. It provides a result of the leading Hadoop Native SQL Database which delivers actionable insights to more people in the enterprise.