Architecture of Cassandra
Architecture of Cassandra: Cassandra’s core objective to accomplish large scalability, availability, and having storage requirements accordingly is achieved through the architecture of Cassandra.
The architecture of Cassandra was made based on the following objectives,
- The schema should be flexible.
- The throughput of read and write should be increasing and should be linear with each additional processor.
- The queries should be partitioned in a key oriented way.
- As there is no master-slave paradigm among nodes, the replication is done through gossip method among the nodes without use of outside machine.
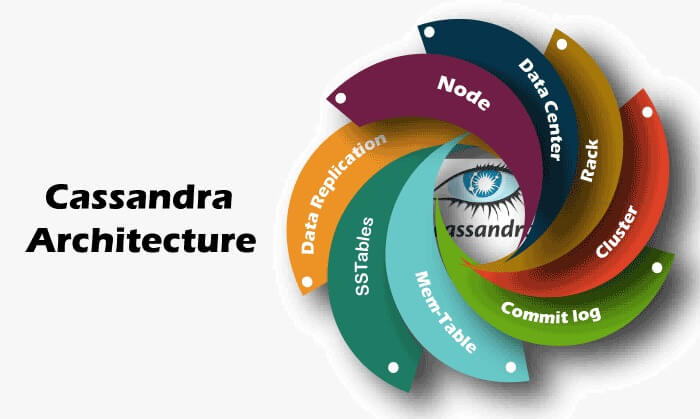
Components of Cassandra:
- Basic components:
- Node: A node is storage space where information is processed and stored when request is sent by a user. It is the most basic component of Cassandra.
- Data Centre: A collection of nodes is called a data centre. The actual request is received by a node in data centre.
- Rack: A rack in Cassandra is collection nodes in a logical grouping. The racks help in ensuring that the replicas are made across different logical groupings of nodes.
- Cluster: The cluster is a collection of multiple data centre’s .The user can acquire as many cluster as required. The group of clusters contributes a machine. These components broadly fulfill the objectives of Cassandra. They help in availing high scalability and availability of data with no point failure.
- Storage Engine:
- Commit-Log: Any data in Cassandra is written before in commit-log then in mem-tables. This improves the durability of data and risk of shutdown. It is a append log only for all the mutations to nodes. The size of commit-log is limited. If a commit is filled a new commit log is allocated. The commit-logs are distributed in segments which have limited size. The default size of commit-log is 32. The query for commit-log segment size is ‘commitlogg_segment_size_in_md’.
As we know commit-log append log of al mutations of Cassandra node. These mutations on startup are synced.
‘Commitlog_sync’: it can be either periodic or batch.
- Batch mode the batch mode would not write until fsynced with disks. The commit-log would wait in milliseconds between fsyncs. ‘commitlog_sync_batch_window-in-ms’. In this batch mode the sudden shut down may lose sync period and delayed if the sync is not applied immediately.
- Periodic mode commit-log writes immediately and syncs every ‘commitlog_sync_period_in_ms’.
- ‘Commitlog_directory’: It is a default option runs on the magnetic HDD rather than running on data directories.
- ‘Commitlog_comression’: The compression is applied to commit-logs and if not compressed the commit-log writes uncompressed.
- ‘Commitlog_total_space_in_mb’: It is used for total space in a commit logs on disk.
- Mem-tables: These are memory structures where Cassandra buffer writes the data. Usually there is one mem-table for every single table. These mem-tables further flushed into the disks and eventually become SS-Tables.
- ‘memtable_cleanup_threshold’: The memory for use of mem-tables if exceeds the given configured threshold.
- The commit-log reaches its maximum size and forces the mem-tables to flush in orderly to allow commit-log segments to be free.
- The mem-tables store completely in heap or partial-heap depending on the ‘memtable_alloaction_type’.
- SS-Tables: The mem-tables are further flushed into the disk and converted into SS-tables. These are immutable data files used for prevention of risk. With help of triggers multiple SS-tables are combined into one. Every time a new SS-table is implemented the old one is removed.
TheSS-tables are made of various components,
- Data.db: It is the actual data stored in rows.
- Index.db: It is the index that separates the keys to position of data.db.
- Filter.db: It I a filter that partitions the keys in a SS-table.
- CompressionInfo.db: It helps in keeping the metadata about the offsets. They are also help in compression of lengths of chunks in data.db.
- Statastics.db: Timestamps, clustering keys, compaction, compressions etc, metadata of SS-tables are stored.
- TOC.txt: It lists the component files of SS-tables in a plain-text.
- Data replication: It is a process of replicating the data to various nodes of single data centre. In a data centre a node catches the request from the user and processes the information. This processed information is then stored in that particular node. This information is then copied by all the rest of the nodes in the data centre. This process happens through ‘Gossip method’ as there is no master node for monitoring.
- Dynamo:
- It has a ring-type structure.
- All the nodes are connected to each other and have no master node.
- If the request is given it hits one of the nodes and that node processes the request and writes on to the database.
- Data is automatically distributed across the nodes.
- Data is kept on the memory and written on the disk. The data among the cluster is distributed using hash values of the keys.
- The replication of the data processed by one node is replicated to other nodes in data centre using Gossip method.
- Gossip: The node after writing signals other nodes to update the data as well. This way of interaction between nodes is known as Gossip.
- Replication: As the requirement the replication of data can be done in the nodes. This helps in high availability of data and no single point failure.
- Cassandrarepresents the data in a cluster in the form of a ring.
- The ring like architecture has many nodes. Each of the nodes in a cluster is assigned a token value i.e, T1, T2, T3…..
- These tokens carry some range which determined position of the ring and used in identifying each partition.
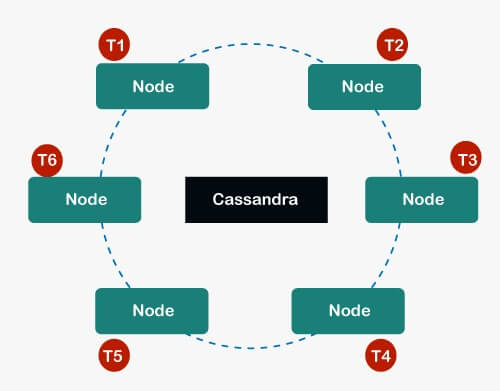
- Virtual Nodes (Vnodes): These are the node help in breaking the token range and assign multiple tokens single physical node.
- A user may connect to any node in a cluster of any data centre and that particular node is known as coordinator node.
- These coordinate node initiate read and write operations. This node identifies which other nodes are replicas and forwards them the query.
Read operation:
In a read operation the coordinator sends request to the other nodes in the cluster. The node which accepts the write operation requests are called coordinator node for the particular operation.
This request is of three types.
- Direct Request: In this type the coordinator node sends the request to the one of the nodes in the data centre.
- Digest Request: Based on the consistency level the coordinator node will contact replica/ replicas. For example, consistency 3 that means any three nodes in a data centre will be contacted.
- Read Repair Request: If the data is not consistent across the node this case will be initiated i.e, Read Repair Request is initiated to retrieve the recent data available across the nodes.
Note: consistency level determines the number of nodes that will respond back with success acknowledgement.
Write Operations:
The Coordinator node sends the request to replicas. If all the replicas are responded the write request will be received regardless of consistency level.
- The write activity is captured by the commit-log and written in the nodes.
- These written data will be captured and stored in the mem-table.
- When the storage of mem-table is max they will be flushed and data will be written into the SS-table.
- All these write activities are automatically replicated and partitioned throughout the entire cluster.
- Cassandra consolidates the SS-tables and will be discarding unnecessary data.
Key Concepts, Data Structures and algorithms:
- Data Partitioning: A single database is divided into various nodes and each node has to save the data.
- Replication strategy:The first replica will be the node that accepts the token range in which the token falls, but the rest of the replicas are placed according to the replication strategy.
- Consistent Hashing: In process of distribution of data two problems arise. First to determine which data has to be assigned to which node. Second minimizing data movements when removing or adding of nodes is done.
- Data Replication: The data had to be stored over various nodes.
- Tunable Consistency: It can provide tuning of data by reading and writing operations.
- Cassandra Key Space: It is a container for all the application data. It is similar schema in RDBMS.
- Gossip Protocol: Cassandra uses gossip protocol to identify node status.
- Merkle Tree: It is a hash tree which provides difference in data blocks.
- Write Back Cache:Write operation is only defined to cache memory.