Cassandra Tutorial
Introduction to Cassandra
Cassandra name was originally taken from ApolloGreek mythology who was priestess.
In technical terms, Cassandra is an open-source NoSQL distributed database technology. Especially used for large amount of data storing across various machines and datacenters. The storing is done across many clusters .Each cluster containing several nodes, which are similar to each other. The information is passed by a request from the user and caught by one of the node in a cluster. The node reads and writes the data and then the processed data is stored.
The replica of the information is done by Gossip method which signals other nodes to copy the data. Below are the detailed features of Cassandra.

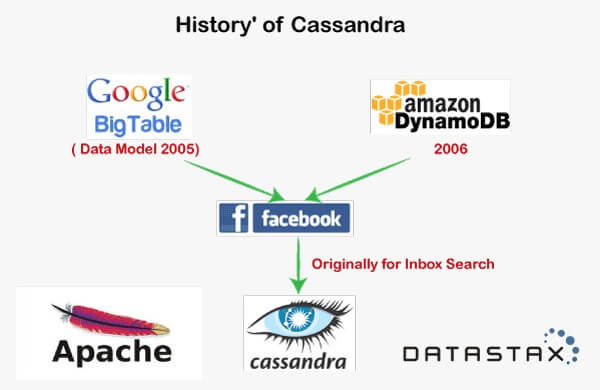
History of Cassandra:
Cassandra was originally developed by Facebook. AvinashLakshman and Prashanth Malik were the co-founders of Cassandra.
Here is a brief journey of Cassandra,
- It was developed originally to deal with inbox search in Facebook.
- It was made an open source in the year 2008.
- Apache incubator accepted Cassandra in the year 2009.
- Cassandra is the most valuable project of Apache since 2009.
- The latest version of Cassandra currently is 4.0.
- From version 3.11 Github branch was added to Cassandra.
Importance of Cassandra:
Cassandra database is perfect for purpose of high scalability and storage of memory.
- Huge data writes: Cassandra can deal with wide amount data with fast data velocity with variety of data and includes complexity issues of data as well.
The modern day cloud technologies are data centric requiring high volume and high velocity. Hence, for such cloud technologies Cassandra is perfect marriage based on the amount of data and cluster size.
Apart from that Cassandra handles data variety and data complexity .Data variety viz, different form data coming from various resources. Data complexity i.e, complex data is handled easily.
- Handling of huge Data sets: Cassandra is a highly tested technology. It was experimented in various different real world scenarios. The experiments proved that it was capable of handling huge data sets.
Companies such as Spotify, Ebay, Netflix use Cassandra for working on the data.
- Homogenous environment:The architecture of Cassandra is complete and does not require outside components for operations. It is a self processing machine running the queries on huge data sets. The machine containing clusters has nodes which has no master node to monitor. The administrator has just to handle about the machine.
- Fault tolerant: In the mechanism of working of Cassandra, there is no master node to monitor. Hence, there is no single point failure and the Cassandra also has capacity of working without downfall even when some nodes are failed in a cluster. There is barely some impact on performance.
- No bound to a single field:Cassandra not bound to IT field only
as many other fields make use of it. It is especially used in banking, medical fields where one has to deal with huge amount of financial / medical bills, statement etc.
- Custom Tuning: Cassandra is enabled in such a way that it can be customized accordingly due to the options that are available.The work load can also be changed according the environment. For example, if read the data from one data centre and write heavily on another data centre. This can be done by adjusting the settings and tuning it accordingly.
Applications of Cassandra:
- Messaging:Cassandra is used widely by messaging apps which has high amount of data.
- Engine Recommendations: E-commerce, social media websites use Cassandra widely for making auto recommendations
- IOT Applications: The IOT applications require to process huge amount of data which use Cassandra.
- Analytics:In the field of data science a data set is widely used for storage and processing of data.
Pros:
- Implementation of SQL column family through NoSQL.
- Replication of information which is tunable and very consistent.
- Has query language called Cassandra query language (CQL).
- It has very flexible schema.
- It is highly scalable and available with no single point failure.
- The read throughput and write throughput are very high.
Cons:
- The application is over developed.
- There no requirement of joins or aggregates.
- There should be some requirements meeting at Hadoop, kubernets, Big data,etc.