HBase Technology
HBase, together with HDFS and MapReduce, is one of the core components of the Hadoop. The Apache Hadoop platform is a highly secure, enterprise-ready extensive data application, which is part of the Hortonworks Data Platform. Some of the biggest companies, such as the Facebook messaging system and so on, are implementing it on a routine basis.
The features of HBase, which makes it a common messaging storage systems are:
- HBase works for random write as well as read operations.
- It has an architecture that is fully decentralized and can operate on huge files.
- It has a high write throughput that is unmatched.
- It has quick and consistent scaling to meet additional requirements.
- It can be used for structured as well as semi-structured data types.
- It is useful when we do not need full RDBMS capabilities.
- The linear modular and scalability feature of HBase is strictly consistent with data reads and writes.
- Table sharding in HBase can be easily configured.
- Automatic failover support is provided by the server.
- It can support MapReduce jobs with HBase Tables.
- The client can access the java API easily.
Pros of HBase
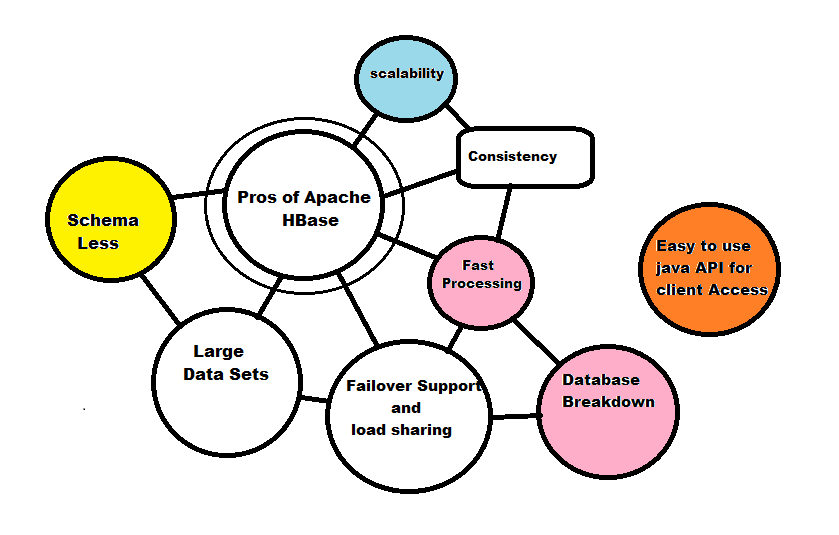
- Large Data sets
HBase can handle large datasets and can store them in addition to storing HDFS files. It also analyzes and aggregates billions of rows in the tables of HBase.
- Failover support and load sharing
HBase is self-recovered by distributing, automatically restoring HDFS internally, and running HBase on top of HDFS. We have this facility for failover, using the Replication of Region Server.
- Scalability
The scalability of HBase is supported in both modular and linear form.
- Schema-less
There is no fixed column schema concept in HBase, as it is schema-less. Therefore, it defines only families with columns.
- Database Breakdown
HBase flashes might occur in the picture during the breakdown of relational databases.
- Fast Processing
It will take a short time to read and process the data as compared to a traditional database.
- Easy to use Java API for client access:-
HBase provides an easy to use Java API for programmatic access.
- Consistency:-
We can use it for high-speed requirements since it offers consistent reads and writes.
Cons of HBase:-
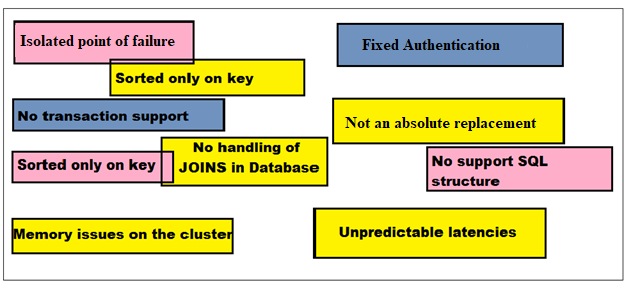
- Isolated point of failure
There is a probability of failure at a time when only one HMaster is used.
- Sorted only on the key
In some arbitrary field, RDBMS and HBase can be indexed and sorted on key only.
- No Transaction support
The transaction is not allowed in HBase.
- Memory issues on the cluster:-
HBase is combined with the effects of Pig and Hive workers in some period memory problems on the cluster.
- No handling of JOINS in database:-
JOINs are handled in the MapReduce layer instead of the database itself.
- Fixed authentication
There are no permissions as well as no fixed authentication.
- Not an absolute replacement
HBase does not support some features of the traditional models. So, we cannot rely entirely on HBase to be used as a subsitute for traditional models.
- No support SQL structure
SQL structure is not supported, it cannot contain any query optimizer.
Where to use HBase?
- Big Data in random, real-time read/write can be viewed by using Apache HBase.
- It has very large tables on top of commodity hardware clusters.
- Apache HBase is considered as a non-relational database after Google's Bigtable. Bigtable runs on Google File System, and Apache HBase operates on top of Hadoop and HDFS as well.
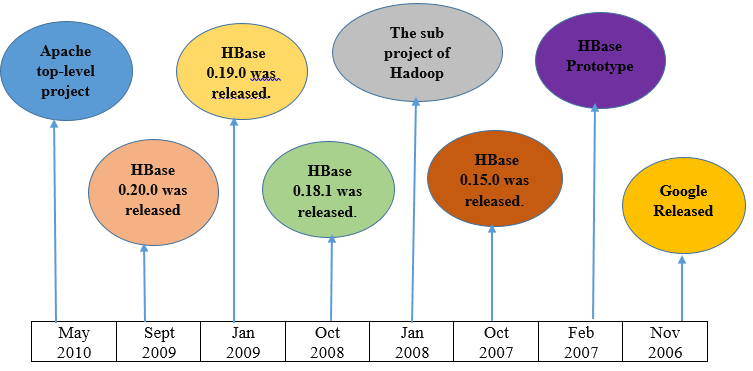
History of HBase
|