Installation Hadoop on Ubuntu
Level 1) Download and install Hadoop
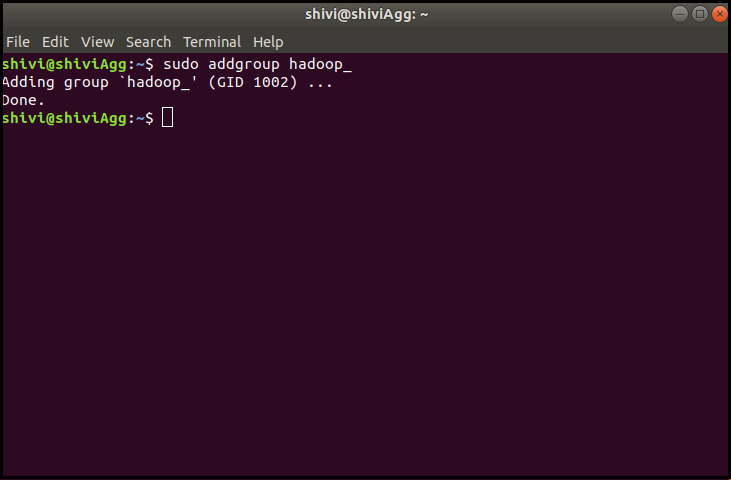
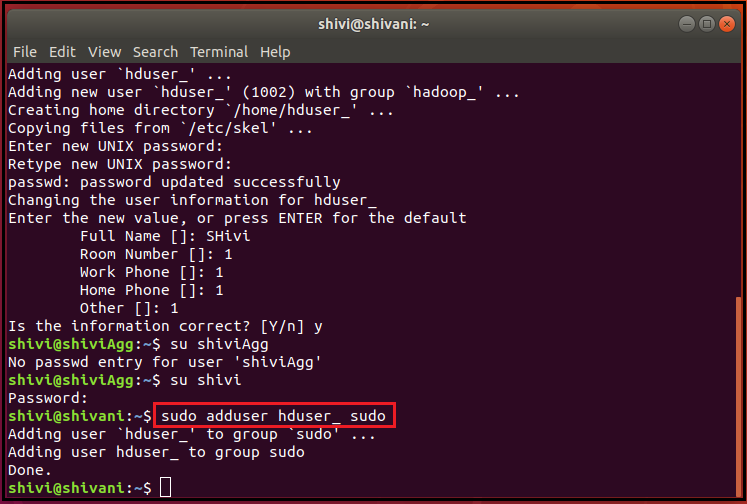
1. beginning you have to create a Hadoop system user through the following command-
sudo addgroup hadoop_
sudo adduser --ingroup hadoop_ hduser_
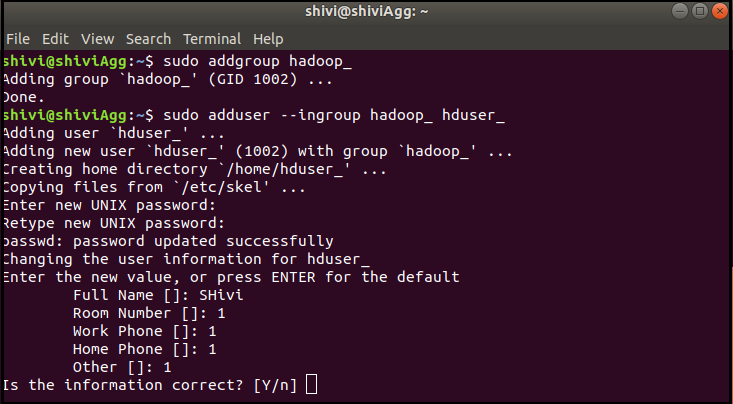
Now, write your credentials such as - password, full name, room number, and other details carefully.
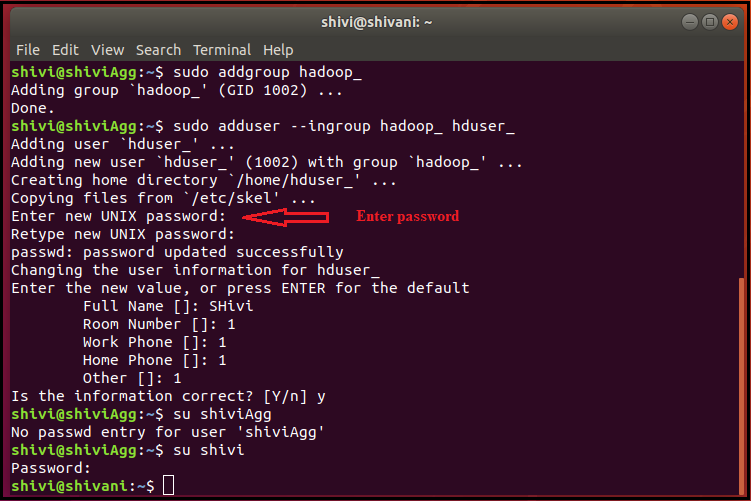
sudo adduser hduser_ sudo
2. Configuration of SSH.
Manage the nodes in a cluster, Hadoop system requires SSH access
First, you need to switch user by writing the following command
su - hduser_
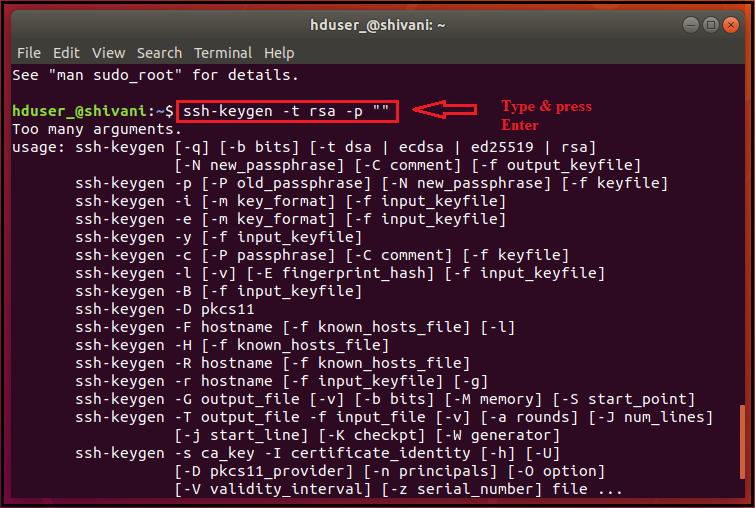
The command will create a new key.
ssh-keygen -t rsa -P ""
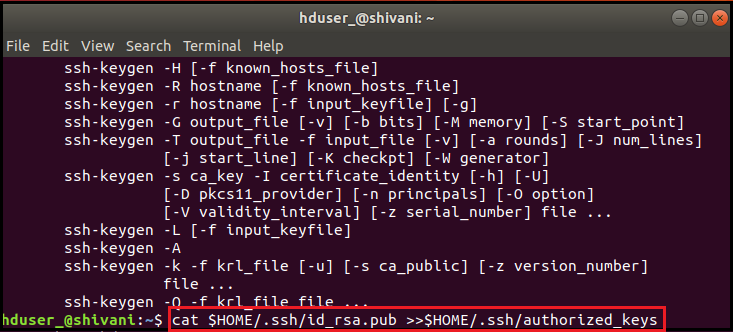
Now enable SSH access to the local machine by using this key as shown.
cat $HOME/.ssh/id_rsa.pub >> $HOME/.ssh/authorized_keys
Now by connecting to localhost as 'hduser' user, test SSH setup.
ssh localhost

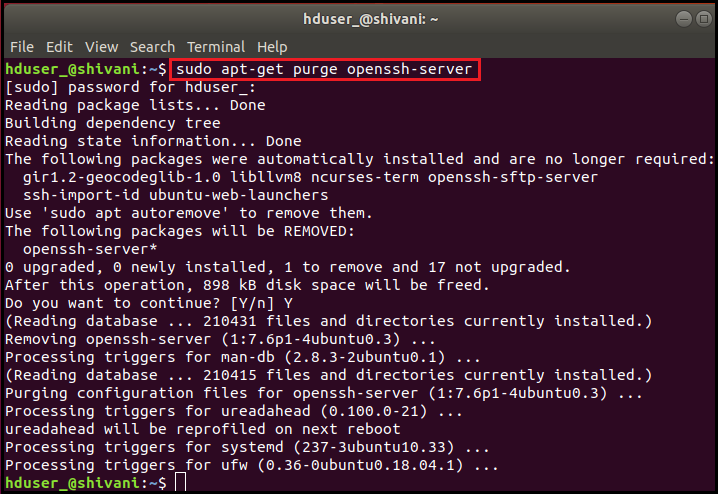
Purge SSH using the following command,
sudo apt-get purge openssh-server
Purge before the start of installation comes under the excellent practice of coding.
Install SSH using the following command-
sudo apt-get install openssh-server

3. Now download Hadoop as shown in the image-
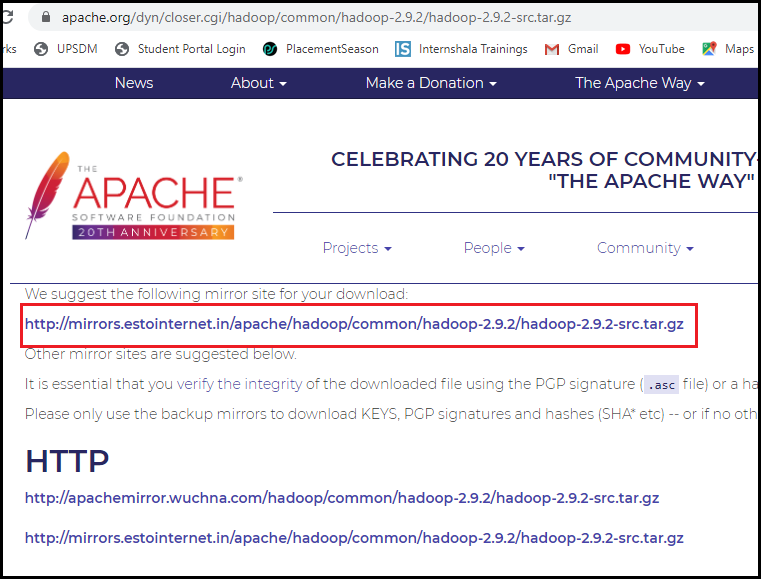
Click on the link to download it.
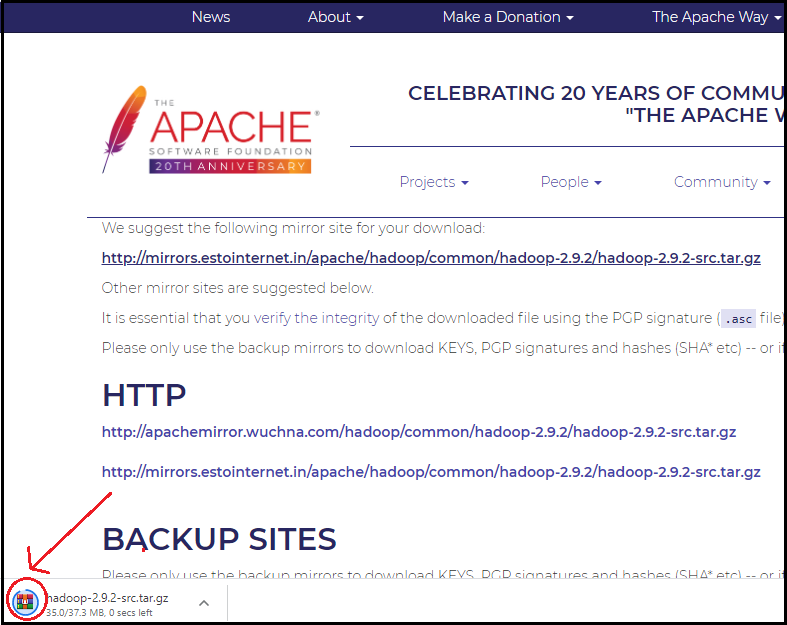
Go to the directory containing the downloaded .tar file, as shown in the image. And use the following code.

sudo tar xzf hadoop-2.9.2.tar.gz

Now, rename hadoop-2.9.2 as Hadoop, as shown by using the given command.
sudo mv hadoop-2.9.2 hadoop

sudo chown -R hduser_:hadoop_ hadoop

Level 2) Configuration of Hadoop
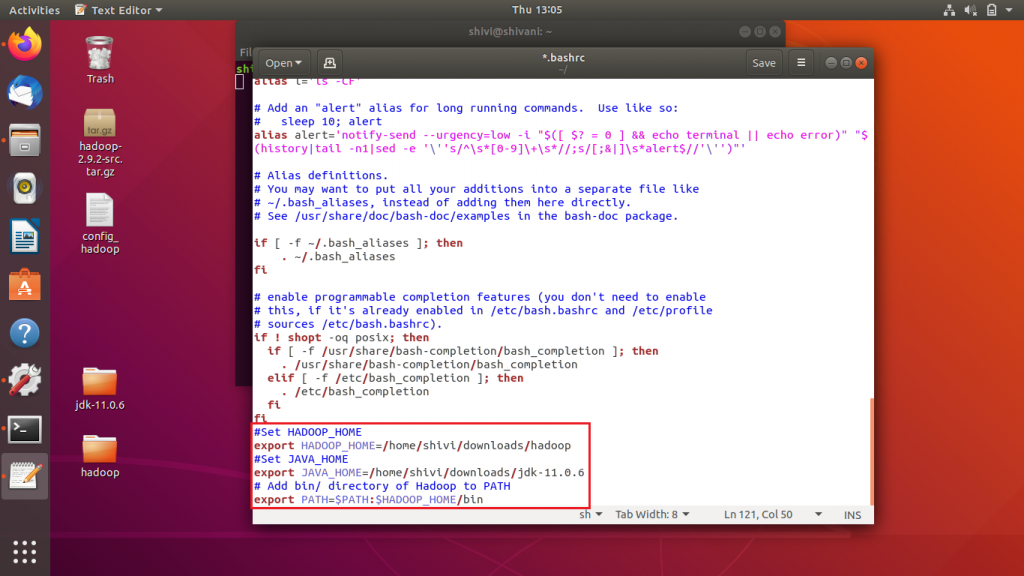
1. Modify ~/.bashrc file
Add this lines at the end of file ~/.bashrc
#Set HADOOP_HOME
export HADOOP_HOME=<Installation Directory of Hadoop>
#Set JAVA_HOME
export JAVA_HOME=<Installation Directory of Java>
# Add bin/ locationn of Hadoop to PATH
export PATH=$PATH:$HADOOP_HOME/bin
We will source this environment configuration by using the command given below.
. ~/.bashrc

2. Configurations related to HDFS
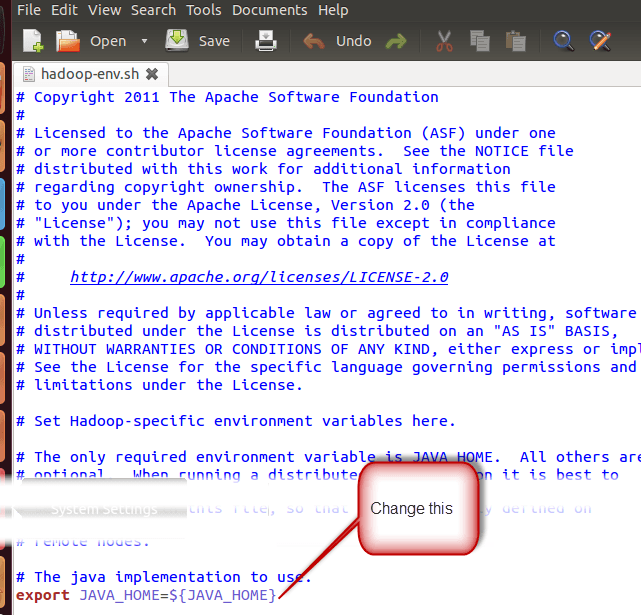
Now ,set JAVA_HOME inside the file $HADOOP_HOME/etc/hadoop/hadoop-env.sh as shown in the image.

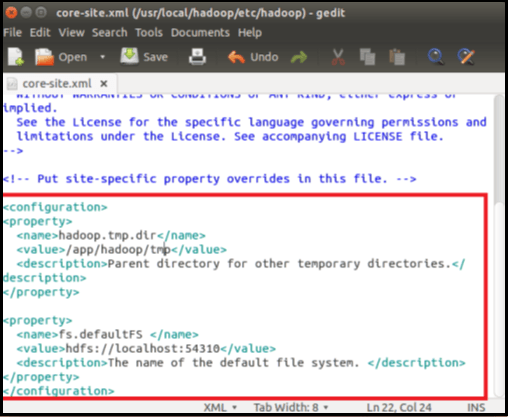
$HADOOP HOME / etc / hadoop / core-site.xml has two parameters that need to be set.
- 'hadoop.tmp.dir' - Used to define a directory that Hadoop will use to store its data files.
- 'fs.default.name' - This command specifies the default file system.
Open core-site.xml, to set these parameters.
command-sudo gedit $HADOOP_ HOME/ etc/ hadoop /core-site.xml

Grab and paste below line of code in between tags <configuration></configuration>
<property> <name>hadoop.tmp.dir</name> <value>/app/hadoop/tmp</value> <description>Parent directory for other temporary directories.</description> </property> <property> <name>fs.defaultFS </name> <value>hdfs://localhost:54310</value> <description>The name of the default file system. </description> </property>
Now, go to the directory $HADOOP_HOME/etc/Hadoop

Create the directory mentioned in core-site.xml using the following code, as shown in the image.
sudo mkdir -p <Path of Directory used in above setting>

Grant all the permissions required to the directory by using the following command.
sudo chown -R hduser_:Hadoop_ <Path of Directory created in above step>

sudo chmod 750 <Path of Directory created in above step>

3. Configuration of Map Reduce.
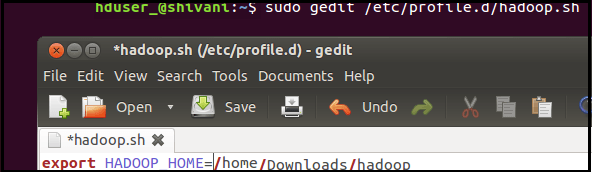
Lets set the HADOOP HOME path before you start these configurations. Use the following code for the reference.
sudo gedit /etc/profile.d/hadoop.sh
And
export HADOOP_HOME=/home/shivi/Downloads/Hadoop
Next write the following code.
command- sudo chmod +x /etc/profile.d/hadoop.sh

Now, exit the Terminal and restart it. And type the following code.
echo $HADOOP_HOME.
To verify the path

Copy the files. For reference, use the following command.
command- sudo cp $HADOOP_HOME/etc/hadoop/mapred-site.xml.template $HADOOP_HOME/etc/hadoop/mapred-site.xml

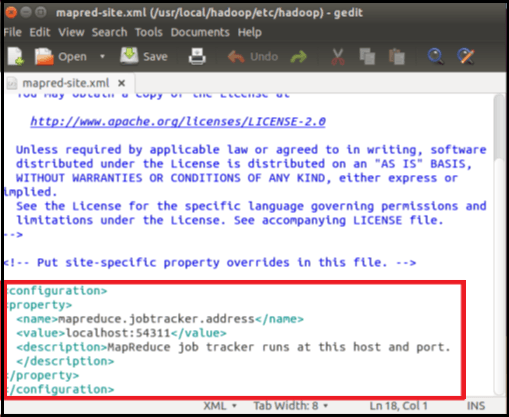
Now, open the file named mapred-site.xml by using the following command.
command- sudo gedit $HADOOP_HOME/etc/hadoop/mapred-site.xml

Copy and paste the given code in between the tags <configuration> and </configuration>
<property> <name>mapreduce.jobtracker.address</name> <value>localhost:54311</value> <description>This host and port is run by MapReduce job tracker. </description> </property>
Now, open $HADOOP_HOME/etc/hadoop/hdfs-site.xml for reference use the following code,
sudo gedit $HADOOP_HOME/etc/hadoop/hdfs-site.xml

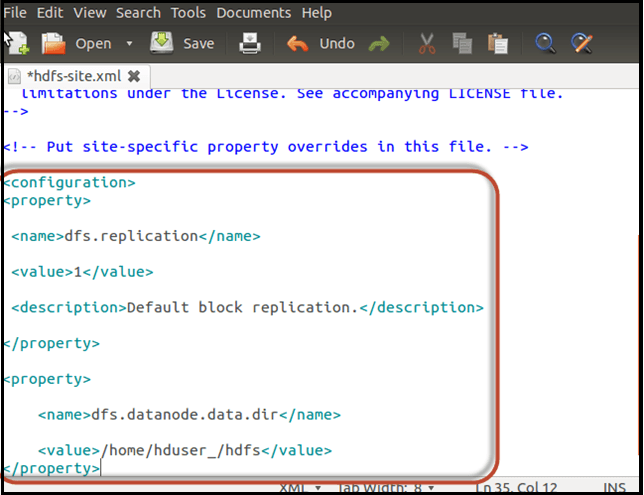
Copy and paste the below lines of code between the tags <configuration> and </configuration>
<property> <name>dfs.replication</name> <value>1</value> <description>Default block replication.</description> </property> <property> <name>dfs.datanode.data.dir</name> <value>/home/hduser_/hdfs</value> </property>
Now, create a directory as given in the setting, as shown above, by using the following line of code.
sudo mkdir -p <Path of Directory used in above setting>
sudo mkdir -p /home/hduser_/hdfs

sudo chown -R hduser_:hadoop_ <Path of Directory created in above step>
sudo chown -R hduser_:hadoop_ /home/shivi/hduser_/hdfs

sudo chmod 750 <Path of Directory created in above step>
sudo chmod 750 /home/hduser_/hdfs

4. Until we first start Hadoop, format HDFS using the command below.
$HADOOP_HOME/bin/hdfs namenode –format

5. Now start Hadoop single node cluster using the command given below.
$HADOOP_HOME/sbin/start-dfs.sh
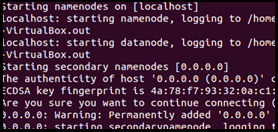
$HADOOP_HOME/sbin/start-yarn.sh
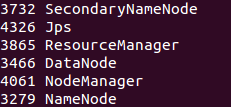
If Hadoop has successfully started, then a jps output will show NameNode, NodeManager, ResourceManager, SecondaryNameNode, DataNode.
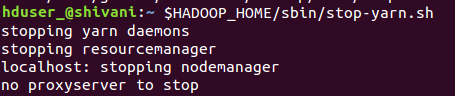
6. Stopping the Hadoop.
$HADOOP_HOME/sbin/stop-dfs.sh
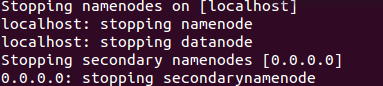
$HADOOP_HOME/sbin/stop-yarn.sh