Instruction Pipelining and Pipeline Hazards
Instruction Pipelining and Pipeline Hazards
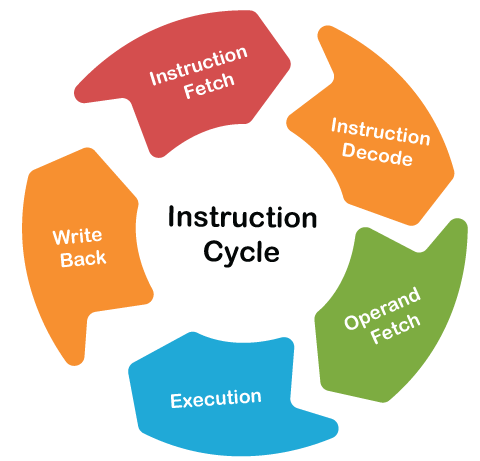
To apply pipeline, the prerequisite is to perform the same processing over multiple inputs, then pipelining is important. So instruction execution is the best example for this kind of requirement. For every instruction, there is an instruction cycle which fetches, decode, then operand fetches, then operation execution and write back and then continue. For other instruction, same five or six stages are followed, and for other same stages are followed. This process continues for the execution of the instructions with multiple inputs. So, the pipelining process is applied/ implemented on the instruction cycle.
Definition- “ If pipeline processing is implemented on instruction cycle then it is called as Instruction Pipelining."
Five stages of pipelining
- IF = Instruction Fetch
- ID = Instruction Decode and Address Calculation
- OF = Operand Fetch
- EX= Execution
- WB = Writeback

These are the hardware in the system which are used to execute the instruction.
Now, let's take an example where we have different instructions to execute with different clock- cycles. Following are the steps for executing the instructions:
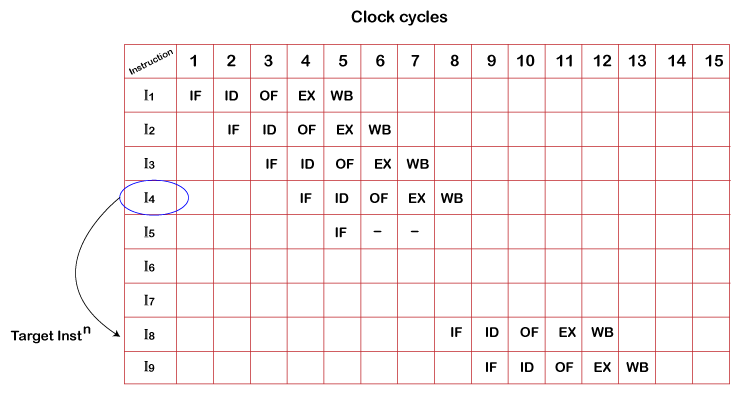
- In the first instruction, it goes through an instruction cycle where firstly, it will be fetched (fetch phase) at the first clock cycle. After fetching, it is decoded(ID), Operand Fetch(OF), Execution phase occurs. The CPU completes the execution of the first instruction in 5 clock cycles.
- We cannot fetch the second instruction at the first clock cycle because IF is hardware, and it can do one work simultaneously. Therefore, we can write IF in the second clock cycle.
- In the third cycle instruction, I3 starts and completes the cycle and the same with the 4rth clock cycle.
- In the case of the fourth instruction, we see that it is a branched instruction. Here when the fourth instruction being decoded, fifth instruction is fetched simultaneously. It may point to some other instruction when it is decoded as it is a branched instruction. Thus, fifth instruction is kept on hold until the branched instruction is executed. When it gets executed, the fifth instruction is copied back, and the other phases continue as usual.
- Assume I4 has taken the target (target instruction) to I8 instruction where instruction fetching starts after the delay in operand fetch of I5 instructions and the delay is named as stalls cycles.
- After the ending of write back of I4 instruction, I8 start the fetching of next instruction and next instruction can be previous one, next or target instruction.
- Process of fetching the instruction continues until the system detect branch instruction which delay the process of execution
Pipeline Hazards
In the pipeline system, some situations prevent the next instruction from performing the planned task on a particular clock cycle due to some problems.
“Pipeline hazards are the situations that prevent the next instruction from being executing during its designated clock cycle." These hazards create a problem named as stall cycles.
Types of Pipeline Hazards
- Structural Hazard/ Resource Conflict
- Data Hazard/ data Dependency
- Control Hazard / Branch Difficulty
Structural Hazard/ Resource conflict
This type of Hazard occurs when two different Inputs try to use the same resource simultaneously.
Suppose there are two Instructions MUL and ADD. Multiplication is very heavy instruction, and for that, instruction pipelines take more than one cycle for execution.
MUL IF ID OF EX EX EX WB
ADD IF ID OF -- --- EX WB
In this second instruction ADD, we perform IF(instruction fetch), ID(decode) and OF(operand fetch), but EX (execution) cannot be performed because EF is hardware that can perform one task at one time. EX of multiplication instruction still occupies it. The same hardware cannot perform the instruction and execution of instruction I2 at C7, which is considered as resource conflict.
To eliminate the resource conflict problem, CPU can use two cache memories; one is instruction cache, and the second is data cache. CPU can fetch instruction from the instruction cache, data from the data cache and can be parallelly accessed.
Data Hazard / Data Dependency
What is Data dependency? Suppose there are two instructions, I1 and I2.
Instruction 1 i: R1ß R2 * R3 IF ID OF EX WB
Instruction 2 i +1: R4 ß R1 + R5 IF ID --- --- OF EX WB

Instruction 1 cycle is processed where it is fetched, decoded, operand fetch, execution and write back of instruction takes place. When instruction two is processed from i+ 1, then it is fetched, decoded but we cannot fetch the operand because the value of R2 and R3 is stored in R1, and that updated value is used in the next instruction operand. So in i + 1, we cannot fetch the operand because the R1 value is not updated. Therefore, we have to delay the second instruction's operation fetch till the write back instruction of the first instruction is completed, and this situation is called a Hazard.
“The instruction R1 result is required as an input for the next instruction R1 value, it means value of R1 in second instruction depends on the resulting value of instruction R1and this dependency is called as Data Dependency, and because of this data dependency, two Stall cycles have been created by the pipeline in executing the instructions.
Solution for data Dependency
General pipeline hardware cannot detect data dependency. If the i+1 type of instruction comes, it fetches the operand in the fourth cycle without checking dependency. This final result of the pipeline will not be correct as in instruction i+1, user needs to fetch a new value of R1, but the general pipeline will fetch the old value, which gives the wrong answer.
So to solve this, we have two types of solutions.
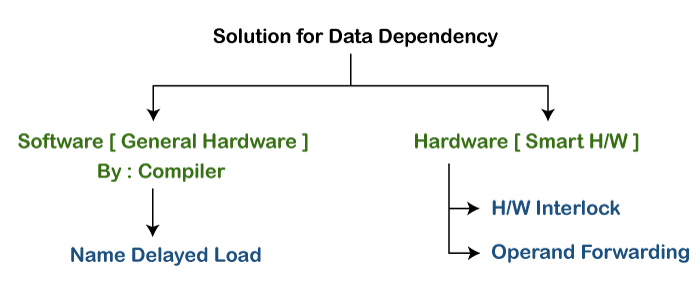
- Software solutions
The compiler will provide the software solution. The compiler generates binary sequence instruction on the CPU. The compiler detects whether the hardware is intelligent or not; if the compiler says hardware is not intelligent, it is general hardware. Therefore, it cannot detect the data dependency. It cannot provide any solution to such a problem by itself. To solve this, the compiler generates instructions (known as no instruction) between two instructions to abolish data dependency condition among the instructions.
The name of the compiler solution is Delayed Load.
- Delayed Load:- A compiler generates it in general hardware. It is explained with an example.
Suppose there are two consecutive instructions having data dependency.
R1 ß R2 * R3
------------------
No instruction/ independent instruction
-------------------
R5ß R1 + R4
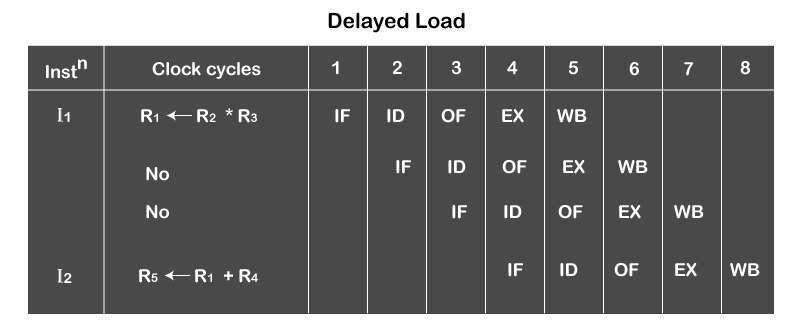
Here, the second instruction's operand fetch should be delayed by two clock cycles, so the compiler inserts two more instructions between these instructions. Those two instructions can be other or can be no operation instruction. If the compiler inserts independent instruction between R1 and R2, they will not affect the result as they are independent instruction. These independent instructions will execute in between, and the operand fetch phase of R2 will get delayed.
We have two options in the delayed role: either insert independent instructions or no operations between the dependent instructions. No operation instructions are specially created to do nothing; these instructions will be fetched, decoded, operand fetched, executed and write back the result, but they will not change any register values. They will not affect flags, or nothing will change. So upcoming instructions will not be affected by any operations. The pipeline doesn't understand what happened; it will execute continuously.
- Hardware solutions
When hardware can detect the data dependency, then smart hardware provides the solution by two methods.
- H/w interlocks – Hardware interlocks means providing stalls cycles.
For example, we have two instructions.
R1ß R2* R3 IF ID OF EX WB
R4 ß R1+R5 IF ID --- ---- OF EX WB
In these two instructions R1 and R2, hardware detects the data dependency. The first instruction R1 cycle starts with phases IF (instruction fetch), ID(instruction decode), OF(operand fetch), EX (execution), WB(write back) and when the second instruction R2 cycle completes the decoding phase of instruction after IF, OF phase, the operand fetched hardware will be locked. This OF(hardware) doesn’t receive any signal or clock to work. OF will open after writing back (WB) the first instruction to get the right value of R1. So, as soon as data dependency is detected by hardware, Operand fetch remains locked until the solution is provided by hardware.
- Operand Forwarding
Operand forwarding also called operand bypassing, as we are bypassing the value of operand. It is a little expensive solution as we have to make hardware intelligent.
Assume two instructions execute in pipeline like this:-
R1ß R2* R3 IF ID OF EX à WB
R4 ß R1+R5 IF ID OF EX WB
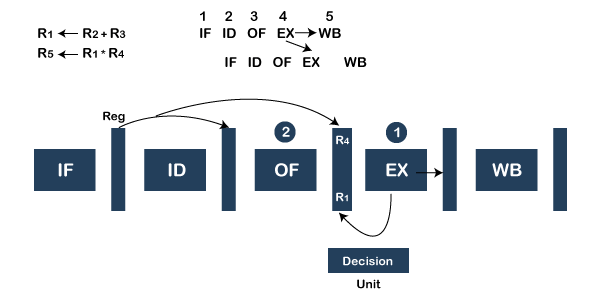
System hardware detects the data dependency problem in instructions. The value of R1 in the second instruction depends on the previous instruction. Hardware understands that the execution phase will generate the result R1, and the first execution phase forwards the value directly for the next cycle. The operand is forwarded in ALU to ALU for the next cycle means ALU forwards the value of R1 to the next cycle and the WB (of first instruction) to update the value of R1 in that register. After the second instruction execution, we can have a writeback (WB), and instruction is completed here. Hence pipeline will not have any dependency.
Decision unit:- This unit is required to detect the condition of data dependency. If there is data dependency, only operand forwarding occurs; otherwise, it is not required.
Note:- ALU to ALU data dependency has no stall cycles because of data dependency if operand forwarding is used. Operand forwarding has no stall cycles.
Control Hazard or Branch Difficulty
If there is a branch instruction, after branch instruction, CPU will be in dilemma that what condition to execute next. Executing the following condition is dependent on the condition, and the condition is evaluated in the execution phase. Until the condition is evaluated, the CPU cannot take any instruction because of the branch instruction, and in this case, there will be extra cycles called Stalls cycles. Due to branch instruction, there arise difficulty known as Branch Difficulty or Control Hazard.
The general hardware cannot detect branch difficulty of control hazards.
The solution of Control Hazards or Branch Difficulty.
Again there are two types of solutions.
- Software solution
- The compiler provides it, and the name of the solution is Delayed Branch.
The compiler will insert some instruction because of delaying the next fetched instruction.
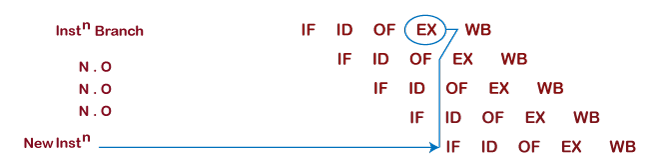
Suppose there is a branch instruction, and after executing a branch instruction compiler will insert some instructions so that the next instruction will be delayed. Two or three operations are inserted after the branch instruction is decoded by a pipeline that how many stall cycles to be inserted. Pipeline decides that after how many stall cycles, the final instruction to be executed and the number of instructions is immediately inserted after the branch instruction.
Now, fetching of new instruction will be done after the updated program counter value, and that will be updated at the end of the execution cycle of the branch instruction. So, branch instruction in the execution cycle will update the program counter value based on the condition ( True/ False), and then the next instruction will be fetched.
- Hardware solution
- Prefetch Target Solution
Suppose few instructions are being executed, and branch instruction is detected by hardware. As soon as hardware detects branch instruction, it initiates two pipelines, one in the direction where the branch is taken the jump and one in where branch jump not taken. Two instructions are initiated parallelly. After two or three cycles, the decision will be calculated. Based on it, the pipeline will take the original correct one and discard the wrong one. If the condition is true, then the wrong pipeline will be discarded, and the actual single pipeline will be executed.
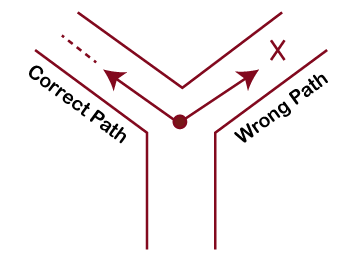
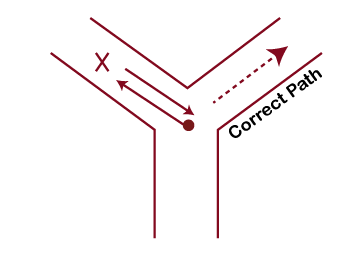
- Branch Prediction
Prediction means to estimate whether it will happen or not. So branch hardware will predict whether the instruction will take a jump or not. If instruction takes a jump, then hardware will start execution of that side instruction without any delay. After two or three cycles, CPU will get to know whether the decision was correct or not. If the decision is correct, then continue in the same direction, and if not, then the CPU will roll back the system to branch instruction and further goes in the correct direction. This is called Branch prediction.
Branch Prediction is of two types.
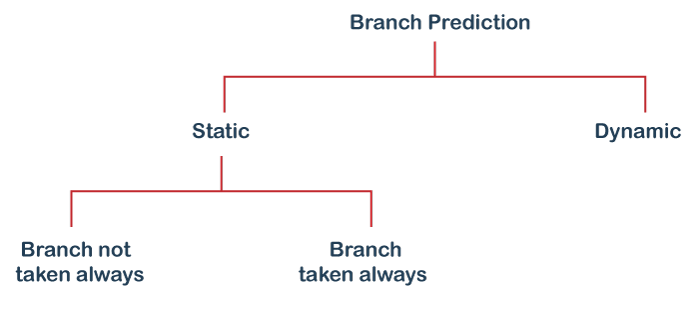
- Static Branch Prediction
When the branch instruction comes, static branch prediction helps to take decision whether to take the branch instruction always (i.e. instruction can jump) or not to take the branch instruction (instruction cannot jump).
- Dynamic Branch Prediction
It will detect the program's current execution behavior, and based on that, it will make a decision. Nowadays, hardware can predict up to 80-90% correct predictions.
- Loop Buffer
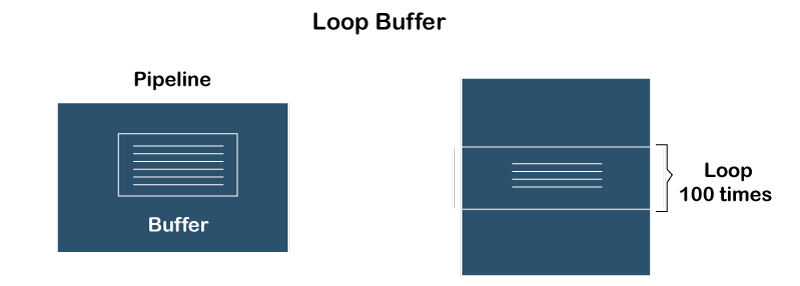
Explanation: Suppose there are a loop and two instructions in the main memory loop. Loops need to be executed 100 times. So, in executing the loop, again and again, every time, there will be a condition, i.e., branching (jump) condition arises. To resolve this, the hardware will have a buffer, and that buffer will store those two instructions of the loop, and those instructions will be executed 100 times in the sequence without any branch or any delay. Without fetching, instruction will be executed again and again.
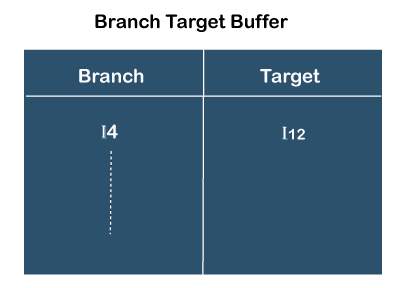
- Branch target prediction
In branch target prediction, a buffer maintained within the pipeline that buffer says that previously taken branch instruction( assume I4) took jump on I12 instruction. It has captured the history of the instruction. If again instruction I4 comes, then the CPU can use this instruction's history and directly go there. All the previously branch instructions come then it can be used for the predictions.