LR Parser in Compiler Design
LR Parser
The most popular type of bottom-up parsing is LR(K) parsing. The LR() parser scans the input from left – to – right, which is the actual abbreviation of L in the LR(K) parser. However, the R in the LR() parser constructs the rightmost derivation in the reverse order. The LR parser uses the lookahead input symbol, which is represented by K in LR(K) parser. The lookahead helps in making parsing decisions.
Why LR Parser
- For any programming language construct, if we are able to write a context-free – grammar, then the LR parser will recognize such kind of programming language. There also exist some non – LR CFG, but in that case, the programming language will avoid the non – LR context-free – grammar.
- The Non–backtracking shift-reduce parser is one of the most preferred LR Parser, which can be implemented in the same way as other primitive shift-reduce parsers.
- LR parser can easily detect any error at the time of scanning the input when required.
- The LR parser, which is parsed by the grammar, is itself the subset of the grammar parsed by LL or Predictive parser.
Difference Between LL and LR Parser
| LL Parser | LR Parser |
| The first L in the LL parser is for scanning the input from left to right, and the second L is for the leftmost derivation. | L in LR parser is for the left to right, and R stands for rightmost derivation in the reverse order. |
| LL follows the leftmost derivation. | LR follows rightmost derivation in reverse order. |
| An LL parser amplifies non - terminals. | Terminals are condensed in LR parser. |
| LL parser constructs a parse tree in a top-down manner. | LR parser constructs a parse tree in a bottom-up manner. |
| It ends whenever the stack in use becomes empty. | It starts with an empty stack. |
| It starts with the start symbol. | It ends with the start symbol. |
| It is easier to write | It is difficult to write |
| Pre-order traversal of the parse tree. | Post-order traversal of the parse tree. |
| Reads the terminals when it pops out of the stacks. | Reads the terminals while it pushes them into the stack. |
| Example LL(0), LL(1) | Example LR(0), SLR(1), LARL(1), CLR(1) |
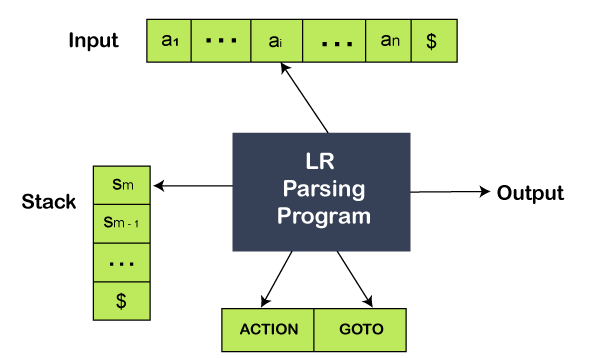
The LR Parser Algorithm
A schematic of an LR parser is shown below fig. This parser contains an input, an output, a stack, a driver program, and a parsing table. ACTION and GOTO are the two parts of the parsing table. The driver program is not different for all LR parsers; only the parsing table is different from one parser to another parser. The stack stores the chronology of grammar with a $ at the bottom of the stack. The string which has to be parsed stays in the input buffer, which is used to indicate the end of input, followed by a $ Symbol.