Spark Architecture
The Apache Spark architecture is well layered, connecting all types of Spark layers and components to the architecture.
The main two important components of architecture are:
- RDD (Resilient Distributed Datasets)
- DAG (Directed Acyclic Graph)
RDD (Resilient Distributed Datasets)
A group of Resilient distributed datasets, in which the datasets of all worker nodes are fully stored in memory.
RDD Stands for:
Resilient: It can build data in terms of variability and fault-tolerant.
Distributed: The data is distributed among clusters of many types of nodes.
Datasets: Data is divided according to values.
RDD is immutable that once it is created, it cannot be changed, but we can transform it at any time. In RDD, many Datasets are divided into several logical partitions, and Spark does this distribution, so there is no need to worry about calculating any type.
We can create an RDD through parallelizing existing collections in your driver programs or using an external system dataset, such as HBase or HDFS.
The RDDs enable you to perform two types of applications:
- Transformations
- Action
Transformations
Transformation is the framework used for the creation of a new RDD.
Action
Action is applied to an RDD, which instructs Spark to compute and send the result to the driver.
DAG (Directed Acyclic Graph)
Directed acyclic graph is a type of finite direct graph, which performs calculations on data. Each node is a Resilient Distributed Datasets partition, and the edge on top of the data is a transformation. The graph here refers to the navigation and acyclic refers to how it is achieved.
Let's explain the architecture of Spark.
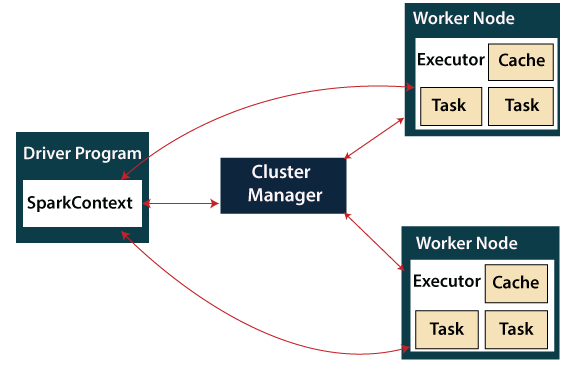
Driver Program
A driver is a process that runs the application's main () function and creates a SparkContext object. The purpose of SparkContext is to coordinate the spark applications, which act as separate groups of operations on a cluster.
The SparkContext connects to another type of cluster manager to operate on a cluster, and then performs the following tasks:-
- It sends its application code to the executors. Here, the application code is determined with the help of JAR and Python files, which is present in SparkContext.
- It acquires node executors in the cluster.
- Finally, followers have to act in order to run SparkContext.
Cluster Manager
- The cluster manager has a role in allocating resources across applications. The Spark is powerful enough to operate on many clusters.
- The cluster manager includes different types of managers such as Hadoop Yarn, Apache Masos and Standalone Scheduler.
- Here, the Standalone Scheduler is a standalone spark cluster manager that enables the deployment of Spark on an empty set of devices.
Worker Node
- The node to the worker is a slave node.
- The role of the worker node is to run the application code in the cluster
Executor
- An executor is a process that has been started for a worker node application.
- It executes activities, and stores data across them in memory or disk storage.
- It reads the external sources and writes data.
- Each program has its own executor.