Supervised Machine Learning
Supervised Machine Learning: In Supervised learning, the machine is trained with the help of well-labeled training data, i.e., the data is tagged with the truthful answer. In other words, we can say that in supervised learning, a supervisor or a teacher is always present.
With the help of labeled training data, the supervised learning algorithm undergoes learning to predict the result for unexpected data.
In order to build, scale, and deploy correctly, the supervised machine learning models not only necessitate time but also highly proficient experts from a team of extremely trained data scientists. The data scientist reconstructs the model to make sure that the provided insight remains true until the data alters.
How Supervised Learning Works?
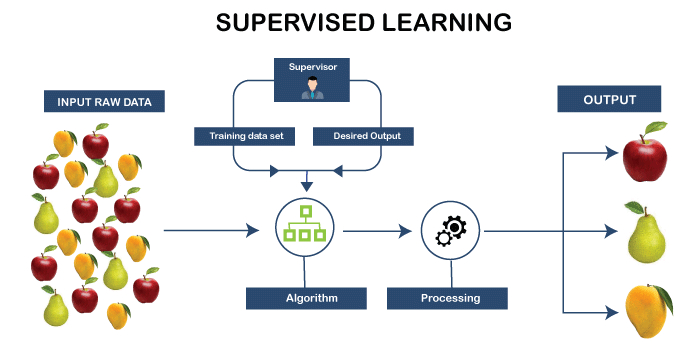
As the name suggests, supervised learning is one such kind that requires a teacher or a supervisor. Basically, in supervised learning, the machine is trained on well-labeled training data, i.e., some amount of data is already marked with the right answer. Once the training is done, a new set of data is fed into the machine so that the supervised learning algorithm can result in a precise outcome by analyzing the training data.
Consider the following example to have a better understanding of the working of supervised learning.
Suppose there is a basket that contains different varieties of fruits. Since the first step is to train the machine with several fruits, so we will do as follows:

- If the fruit is in the ovoid shape, non-edible rind and pale yellow or dark green in color, then it will be marked as a Mango.
- Similarly, if the fruit is in the shape of a long curved cylinder and yellow or green in color, then it will be marked as a Banana.
Let us assume that after training the data, you give a new separate fruit, say Mango, from the fruit basket and ask the machine to classify it.

Now that the machine has already learned about fruits from the previous data, it will consider the following things while making the classification:
- Shape
- Color
Since the fruit is in ovoid shape and pale-yellow color, the machine will classify the fruit as a MANGO and will put it in the category of MANGO. Thus, in this way, the machine learns from the training data (i.e., the fruit basket) and then apply the knowledge to test data (new fruit).
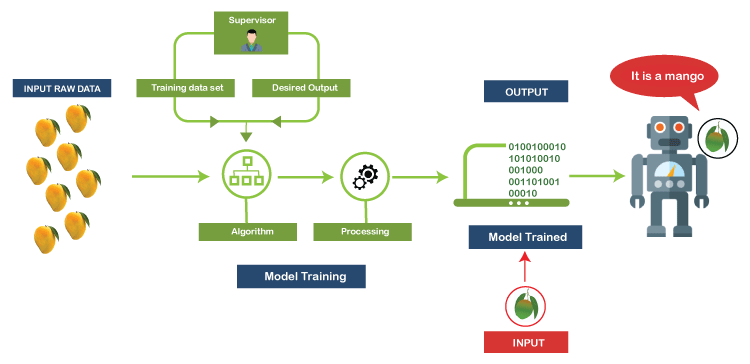
Steps involved in Supervised Learning
Following are the steps incurred in supervised learning:
- Firstly, it ascertains the category of the training dataset.
- Next, it collects well-labeled training data.
- Then segment the training dataset into train dataset, test dataset, and validation dataset.
- Determine the training dataset’s input features that will further assist the model in predicting the correct output.
- In the next step, it discovers an appropriate algorithm such as a support vector machine, decision tree, etc., for the model.
- After this, it implements the algorithm on the training dataset. Since the validation sets are itself the subset of the training dataset, so we often need them to act as our control parameters.
- Lastly, it assesses the model’s accuracy with the help of the test set. If the correct output is predicted by the model, then it can be concluded that our model is accurate.
Types of Supervised Learning
Supervised learning is classified into 2 types:
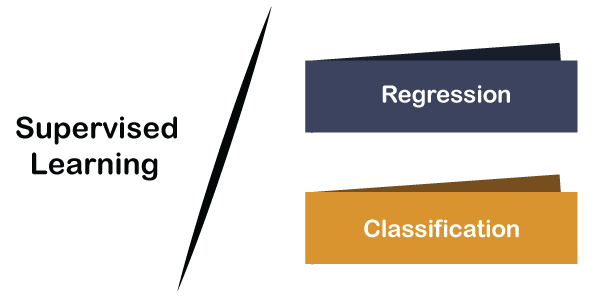
Regression
The supervised learning that learns from well-labeled train data to predict continuous values of variables from a well-labeled test data is generally termed as Regression. A regression problem is mostly used whenever we have a real-valued output variable, such as "dollars" or "weight." The regression algorithm is further divided into the following types:
Linear Regression
Given well-labeled train data, the logistic regression predicts a continuous value of variables such as house price, blood pressure of a person, etc., from the well-labeled test data.
Logistic Regression
The logistic regression technique falls under the category of statistical and machine learning. It classifies the dataset’s records based on its input field values. Given a well-labeled input dataset, the logistic regression predicts a categorical or discrete target field such as Yes-No, Male-Female, True-False, etc.
Classification
The classification learning is mainly used whenever we are given a categorical output variable, i.e., we have two classes such as 1-0, Yes-No, True-False, etc. The classification problem is further divided into the following types:
Naïve Bayes
The Naïve Bayes model (NBN) is mainly used in the case of large datasets. It is easily implemented. The Naïve Bayes model is serene as direct acyclic graphs that has a single parent and numerous children, assuming liberation among child nodes separated from their parent.
Decision Tree
Based on the feature value, Decision trees catalog an element simply by sorting them. Here each node represents the feature value of an instance, and the branch represents the value assumed by each node. A decision tree is a preferred technique for classification.
It mainly estimates the real values such as the cost of purchasing a car, number of calls, total monthly sales, etc.
Support Vector Machines
The support vector machines are linked to kernel functions that play a vital role in every task. The kernel framework and SVM are used in a variety of fields. The application area of support vector machines is multimedia information retrieval, bioinformatics, and pattern recognition.
Advantages of Supervised Learning
- Supervised learning is helpful in deriving the output from past experiences or prior knowledge.
- It supports performance optimization by incorporating past experiences.
- Supervised machine learning tends to solve several kinds of practical computation problems.
Disadvantages of Supervised Learning
- The only disadvantage of the supervised learning model is that it cannot handle complicated tasks.
- In case if the test dataset varies from the training dataset, the supervised learning algorithm will face problems while predicting the outcome.
- Training required lots of computation times.
- It does require an ample amount of knowledge regarding the object class.