Apache Spark Components
The Spark project consists of various types of components that are closely integrated. Spark is at its core a computational engine capable of scheduling, distributing, and monitoring multiple apps.
The main components of Spark are:
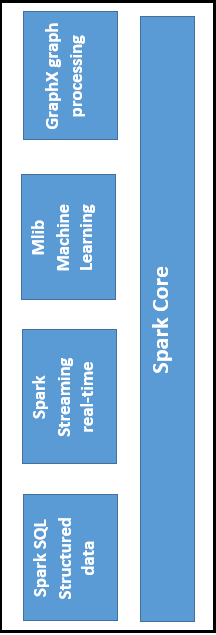
- Spark Core
- Spark SQL
- Spark Streaming
- Mlib Machine Learning
- GraphX graph Processing
Spark core
- Spark Core is the heart of Spark, which is built on all other functionalities.
- It includes the components for job scheduling, fault recovery, communicating with storage, and memory management systems.
Spark SQL
- On top of Spark Core, the Spark SQL is developed. It supports structured data.
- Spark SQL(Structured Query Language) allows querying data from SQL as well as Apache Hive of SQL, which is called HQL (Hive Query Language).
- It supports connections between JDBC and ODBC that create a relationship between Java objects and existing databases, data warehouses, and business intelligence tools.
- It also supports complex data sources such as Hive tables, Parquet, and JSON.
SQL Streaming
- Spark Streaming is a component of Spark that supports scalable and fault-tolerant streaming data processing.
- It uses the quick scheduling capabilities of Spark Core to conduct streaming analytics.
- It accepts mini-batch data and executes RDD transformations on that data.
- Its architecture ensures that the applications written for streaming data can be reused with little modification to analyze batches of historical data.
- Log files generated by web servers can be considered as an example of a data stream in real-time.
MLlib
- MLlib is a type of machine library, which includes a variety of machine learning algorithms.
- It comprises checking of associations and theories, classification and regression, clustering, and study of main components.
- The disk-based implementations have been used nine times by the Apache mahout to make it faster.
GraphX
- GraphX is a library used to manipulate graphs and perform parallel graph computing.
- It facilitates the development of a directed graph with arbitrary properties attached to each vertex and edge.
- To control the graph, it supports various key operators, such as subgraph, merges Vertices, and aggregate Messages.