Boyer Moore Algorithm
Boyer Moore Algorithm
The Boyer Moore algorithm is a searching algorithm in which a string of length n and a pattern of length m is searched. It prints all the occurrences of the pattern in the Text.
Like the other string matching algorithms, this algorithm also preprocesses the pattern.
Boyer Moore uses a combination of two approaches - Bad character and good character heuristic. Each of them is used independently to search the pattern.
In this algorithm, different arrays are formed for both heuristics by pattern processing, and the best heuristic is used at each step. Boyer Moore starts to match the pattern from the last, which is a different approach from KMP and Naive.
Let us now understand the bad character heuristic :
Bad character: A character in the Text that has no match with the pattern is called a bad character.
Now, when there is a case of mismatch, we shift the pattern until it becomes a match, and the pattern moves past the mismatched character.
MISMATCH BECOMES A MATCH
Find the position of the last character that mismatched in the pattern and, then shift the pattern until it gets aligned to the mismatched character in the Text.
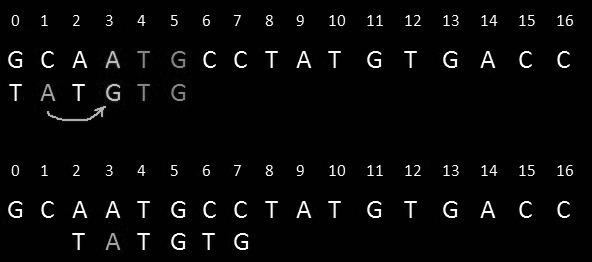
Example: In the above Text, there is a mismatch at position 3( A does not match with G). Now we find the last occurrence of A in our Text. At position 1, We get the A now we shift the pattern to position 1.
PATTERN MOVE PAST THE MISMATCH CHARACTER
We look up the last occurrence of the character that does not match the pattern; if it does not exist in the pattern, we move the pattern past that last mismatched character.
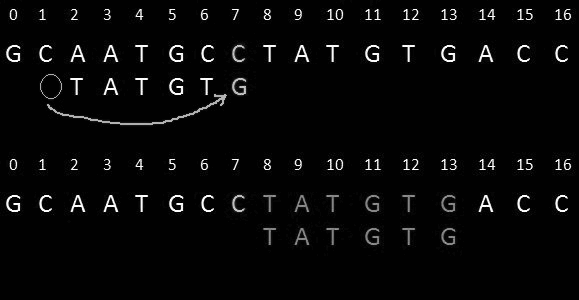
Example: At position 7 there is a mismatch of character "C". It does not exist in the pattern, so we shift the pattern past 7. On shifting the pattern past 7 we get a perfect match.
Thus we find the last occurrence of every possible character in an array of size equal to alphabet size. If not present, we shift the pattern by m size.
This bad character approach takes O (n/m) time complexity in the best case.
C++ code:
#include <bits/stdc++.h>
using namespace std;
#define TOTAL_CHARS 256 // Total 256 characters can be there
void badCharacterHeuristic(string STR, int size, int badcharacter[TOTAL_CHARS])
{
for (int i = 0; i < TOTAL_CHARS; i++) // Initialize all occurrences as -1
badcharacter[i] = -1;
// Put the value of last last occurrence of the character
for (int i = 0; i < size; i++)
badcharacter[(int)STR[i]] = i;
}
// Boyer Moore bad character approach
void Bad_Character_Search(string text, string pattern)
{
int m = pattern.size();
int n = text.size();
int badcharacter[TOTAL_CHARS];
badCharacterHeuristic(pattern, m, badcharacter); // Preprocess by filling bad character
int shift = 0;
while (shift <= (n - m)) // Shift until end of text
{
int j = m - 1;
while (j >= 0 && pattern[j] == text[shift + j]) /* j decreases until characters of pattern and text are match at the current shift */
j--;
if (j < 0) // It indicates pattern is there at current shift position
{
cout << "pattern occurs at shift = " << shift << endl;
/* The case shift + m < n is mandate to handle the pattern at end of text */
shift += (shift + m < n) ? m - badcharacter[text[shift + m]] : 1;
}
else
/* maximum function gives a positive shift . There are possible cases
to get a negative shift value if last occurrence of bad character is on right of current one */
shift += max(1, j - badcharacter[text[shift + j]]);
}
}
// Main function to run bad character approach
int main()
{
string text = "ABAAABCD";
string pattern = "ABC";
Bad_Character_Search(text, pattern);
return 0;
}
C code:
#include <stdio.h>
#include <string.h>
#define TOTAL_CHARS 256 // Total 256 characters can be there
int max(int a, int b) { return (a > b) ? a : b; }
void badCharacterHeuristic(char* STR, int size, int badcharacter[TOTAL_CHARS])
{
for (int i = 0; i < TOTAL_CHARS; i++) // Initialize all occurrences as -1
badcharacter[i] = -1;
// Put the value of last last occurrence of the character
for (int i = 0; i < size; i++)
badcharacter[(int)STR[i]] = i;
}
// Boyer Moore bad character approach
void Bad_Character_Search(char* text, char* pattern)
{
int m = strlen(pattern);
int n = strlen(text);
int badcharacter[TOTAL_CHARS];
badCharacterHeuristic(pattern, m, badcharacter); // Preprocess by filling bad character
int shift = 0;
while (shift <= (n - m)) // Shift until end of text
{
int j = m - 1;
while (j >= 0 && pattern[j] == text[shift + j]) /* j decreases until characters of pattern and text are match at the current shift */
j--;
if (j < 0) // It indicates pattern is there at current shift position
{
printf("pattern occurs at shift = %d", shift);
/* The case shift + m < n is mandate to handle the pattern at end of text */
shift += (shift + m < n) ? m - badcharacter[text[shift + m]] : 1;
}
else
/* maximum function gives a positive shift . There are possible cases
to get a negative shift value if last occurrence of bad character is on right of current one */
shift += max(1, j - badcharacter[text[shift + j]]);
}
}
// Main function to run bad character approach
int main()
{
char text[] = "ABAAABCD";
char pattern[] = "ABC";
Bad_Character_Search(text, pattern);
return 0;
}
The Bad character approach takes O(nm) time in the worst case when all characters in the Text are the same as the pattern.
As we have discussed the bad character heuristic approach, Now, understand the Good suffix approach.
This approach also calculates a preprocessing table.
Good suffix approach
Let T be the substring of Text that matches with any substring in the pattern P.
Now we shift the pattern until:
- Another occurrence of T in P matches with T in the Text.
- A prefix of Pattern P that matches the suffix of T.
- P moves past T.
Another occurrence of T in P matches with T in the Text.
There can be few more occurrences of T in our pattern. In such a scenario, we shift the pattern to align it with T.

For example, there is a substring in Text (“AB”) at index 3 and 4 that matches with the pattern. So we shift our pattern to the positions where the substring lies in order to match.
A PREFIX OF PATTERN THAT MATCHES WITH SUFFIX OF T IN THE TEXT
If the above case fails anyhow, we will match the suffix of T in the prefix of our pattern. If it exists, we will align the pattern with the suffix.

For example, The suffix "BAB" matches with the prefix of the pattern("AB") at position starting from 0. We then align the pattern with the matching "AB" suffix of the Text.
PATTERN MOVES PAST T
If the above cases don't work, we shift the pattern past the T.

For example, Here, both the above cases fail because of no occurrence of T in P and no prefix in pattern match with a suffix of T. In such a case, we move the index past 4.
STRONG GOOD SUFFIX HEURISTICS
Consider a case where a substring Q(P[i to n]) got matched with T in Text, but the (i-1)th character in P is a mismatch. Now unlike case 1 we will search for T in P, which is not preceded by (i-1)th character.

For example, positions 7 and 8 matches with Text and pattern. The (i-1)th character mismatch is “C”. Now, if we start searching t in P, we will get the first occurrence of t starting at position 4. But this occurrence is preceded by "C", so we will skip this and carry on searching. At position 1 we got another occurrence of t (in the yellow background). This occurrence is preceded by "A" (in blue), which is not equivalent to "C".
This results in a shift of pattern P 6 times to align this occurrence with T in Text. This is done as character "C" causes the mismatch. Therefore, any occurrence of T preceded by "C" will again cause a mismatch when aligned with t, so that's why it is better to skip this.
PREPROCESSING FOR THE GOOD STRING SUFFIX
Create an array shift. Shift[i] will contain the distance our pattern will shift if there is a mismatch at (i-1)th position.
- PREPROCESSING FOR STRONG GOOD SUFFIX
Border: It is a substring that is both a proper prefix and suffix. For example, in string “ccacc”, “c” is a border, “cc” is a border because it appears in both ends of the string, but “cca” is not a border. As a part of preprocessing an array bopos (border position) is calculated. Each entry bopos[i] contains the starting index of the border for the suffix starting at index i in given pattern P.
The suffix ? beginning at position m has no border, so b0pos[m] is set to m+1, where m is the length of the pattern. The shift position is obtained by the borders, which cannot be extended to the left.
The Following is the code for preprocessing:
void preprocess_strong_suffix(int *shift, int *bopos,
char *pattern, int m)
{
int i = m, j = m+1;
bopos[i] = j;
while(i > 0)
{
while(j <= m && pattern[i-1] != pattern[j-1])
{
if (shift[j] == 0)
shift[j] = j-i;
j = bopos[j];
}
i--; j--;
bopos[i] = j;
}
}
Explanation: Consider pattern P = “ABBABAB”, m = 7.
- The longest region of suffix “AB” beginning at index i = 5 is ? (nothing) starting at position 7 so bopos[5] = 7.
- At index i = 2 the suffix is “BABAB”. The widest border for this suffix is “BAB” starting at position 4, so j = bopos[2] = 4.
Let’s understand it with an example:
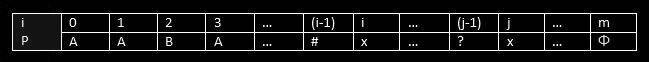
If character # Which is at position i-1 is equivalent to the character? at index j-1, what will the border be? + border of suffix at position i, which is starting at position j, which is equivalent to saying that border of suffix at i-1 begin at j-1 or bopos[ i-1 ] = j-1 or in the code:
i--;
j--;
bopos[ i ] = j
But if character # at position i-1 does not match with the character at position j-1, then we continue our search to the right. Now, we know that:
1. Border width will be smaller than the border starting at position j, i.e. smaller than x…?
2. Border has to begin with # and end with ? or could be empty (no border exists).
With the above two facts, we will continue our search in substring x…? from position j to m. The next border will be at j = bopos[j]. After updating j, we again compare characters at position j-1 (?) with #, and if they are equal, then we got our border; otherwise, we continue our search to the right until j>m. This process is shown by code –
while(j <= m && pattern[i-1] != pattern[j-1])
{
j = bopos[j];
}
i--; j--;
bopos[i]=j;
In the above code, look at the following conditions:
pattern[i-1] != pattern[j-1]
This is the condition which we discussed in case 2. When the character preceding the occurrence of t in pattern P is different from the mismatching character in P, we stop skipping the occurrences and shift the pattern. Here P[i] == P[j] but P[i-1] != P[j-1] so the pattern shifts from i to j. So shift[j] = j-i is a recorder for j. So whenever any mismatch occurs at position j, we will shift the pattern shift[j+1] positions to the right.
In the above code the following condition is very important:
if (shift[j] == 0 )
This condition prevents modification of shift[j] value from suffix having the same border.
2) Preprocessing - Case 2
The widest border of the pattern that is contained in that suffix is found, and the starting position of the widest border is stored in bopos[0].
In the following algorithm, this value bopos[0] is initially stored in all free entries of array shift. When the suffix of the pattern becomes smaller than bopos[0], the algorithm moves forward with the next-wider border of the pattern, i.e., with bopos[j].
C code:
#include <stdio.h>
#include <string.h>
// strong good suffix implementation
void preprocess_strong_suffix(int* shift, int* bopos,
char* pattern, int m)
{
int i = m, j = m + 1; // length of pattern is m
bopos[i] = j;
while (i > 0) {
while (j <= m && pattern[i - 1] != pattern[j - 1]) // if not euqal continue to find border
{
/* Now no skipping the occurrences and shift the pattern from i to j. */
if (shift[j] == 0)
shift[j] = j - i; /* Character preceding the occurrence of T in
pattern P is different than the mismatching character in P */
j = bopos[j]; //Change the position of next border
}
i--;
j--; /* store the beginning position of border when border found*/
bopos[i] = j;
}
}
void preprocess_case2(int* shift, int* bopos,
char* pat, int m) // case 2 Preprocessing
{
int i, j;
j = bopos[0];
for (i = 0; i <= m; i++) {
if (shift[i] == 0)
shift[i] = j;
if (i == j) /* here the suffix became smaller than bopos[0] */
j = bopos[j]; // j will be used as next wider border
}
}
void good_suffix_algo(char* text, char* pattern) // Implement good suffix algo
{
int s = 0, j; // s is shift of pattern w.r.t text
int m = strlen(pattern);
int n = strlen(text);
int bopos[m + 1], shift[m + 1];
for (int i = 0; i < m + 1; i++)
shift[i] = 0; // initially all shifts are 0
preprocess_strong_suffix(shift, bopos, pattern, m); // preprocess the pattern
preprocess_case2(shift, bopos, pattern, m); // case 2 Preprocessing
while (s <= n - m) {
j = m - 1;
while (j >= 0 && pattern[j] == text[s + j]) /* j reduces while text and pattern characters keep matching at s shift*/
j--;
if (j < 0) // Pattern present at cuurent shift makes j < 0
{
printf("Pattern found at shift = %d\n", s);
s += shift[0];
}
else
/*pattern[i] != pattern[s+j] the pattern shifts j+1 times */
s += shift[j + 1];
}
}
int main() // Main function for good suffix heuristic
{
char text[] = "ABAAAABAACD";
char pattern[] = "ABA";
good_suffix_algo(text, pattern);
return 0;
}
C++ code:
#include <bits/stdc++.h>
using namespace std;
// strong good suffix implementation
void preprocess_strong_suffix(int* shift, int* bopos,
char* pattern, int m)
{
int i = m, j = m + 1; // length of pattern is m
bopos[i] = j;
while (i > 0) {
while (j <= m && pattern[i - 1] != pattern[j - 1]) // if not equal continue to find border
{
if (shift[j] == 0) /* No shifting of characters*/ shift[j] = j - i;
/* Characters before the occurrence of T in
pattern P are different than the mismatching character in P */
j = bopos[j]; //Change the position of next border
}
i--;
j--; /* store the beginning position of border when border found*/
bopos[i] = j;
}
}
void preprocess_case2(int* shift, int* bopos,
char* pat, int m) // case 2 Preprocessing
{
int i, j;
j = bopos[0];
for (i = 0; i <= m; i++) {
if (shift[i] == 0)
shift[i] = j;
if (i == j) /* here the suffix became smaller than bopos[0] */
j = bopos[j]; // j will be used as next wider border
}
}
void good_suffix_algo(char* text, char* pattern) // Implement good suffix algo
{
int s = 0, j; // s is shift of pattern w.r.t text
int m = strlen(pattern);
int n = strlen(text);
int bopos[m + 1], shift[m + 1];
for (int i = 0; i < m + 1; i++)
shift[i] = 0; // initially all shifts are 0
preprocess_strong_suffix(shift, bopos, pattern, m); // preprocess the pattern
preprocess_case2(shift, bopos, pattern, m); // case 2 Preprocessing
while (s <= n - m) {
j = m - 1;
while (j >= 0 && pattern[j] == text[s + j]) /* j reduces while text and pattern characters keep matching at s shift*/
j--;
if (j < 0) // Pattern present at current shift makes j < 0
{
cout << "Pattern found at shift = " << s << endl;
s += shift[0];
}
else
/*pattern[i] != pattern[s+j] the pattern shifts j+1 times */
s += shift[j + 1];
}
}
int main() // Main function for good suffix heuristic
{
char text[] = "ABAAAABAACD";
char pattern[] = "ABA";
good_suffix_algo(text, pattern);
return 0;
}