Data Science vs Machine Learning
Concept and Definition
Data science, at its core, is a field of study based on the approach to scientifically extract some insights and meanings from data or a data set. Popularly, data science is defined as the combination of various methods of modeling information technology used for business management. Various technical and statistical institutions have acknowledged and adopted the importance of data science. They have been providing career-oriented degree programs both offline and online across various popular websites.
On the other hand, machine learning deals with the set of techniques used by the data scientist to make computers learn from the existing or the given data. These techniques are highly carved and well-computed methods that produce effective results to outperform well without dealing with explicit programming rules. The diagram given below justifies the fine differences so that we don't get confused before moving further.
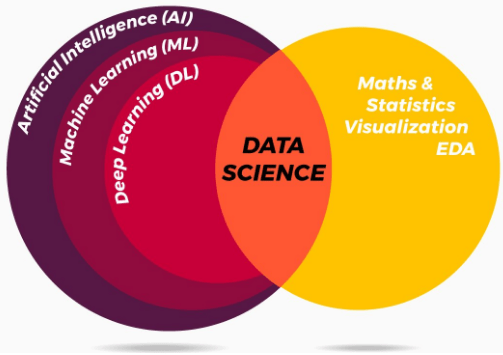
Both Machine learning and data sciences are trending topics and the talk of the hour these days. These two terms are confusing to many and are understood by some because they serve a close relationship with each other although being different from each other.
Workflow of Data Science
The digital world is adapting rapidly, and there is a visible materialistic change in the proliferation of smartphones that are seen to impact our daily life massively. At each step of this technical advancement, one aspect is common, i.e., data generation. Technological advancement is severely inclined to computing, thereby increasing the vicinity of these digital applications in almost all aspects of life. Day by day, the dramatic increase in computing power and decreasing relative cost has made computing cheap and widely accessible globally. By combining this entire immense amount of generated data, the act of studying the data being generated is just a mere portion of data science.
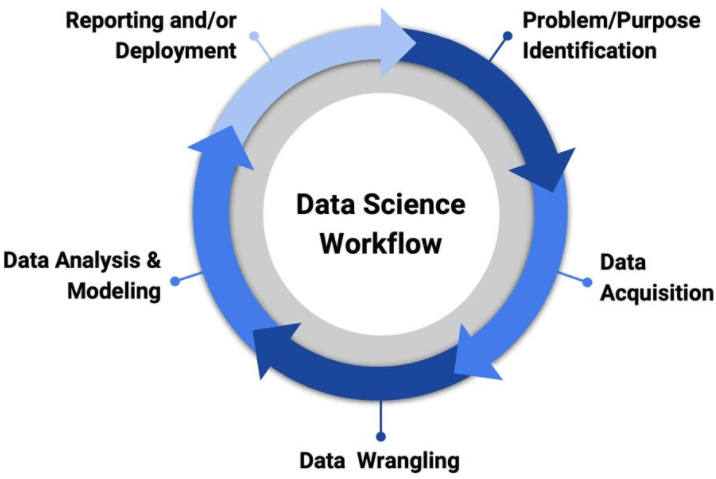
The workflow of data sciences requires a combination of different skills and experience. This is one of the main reasons why data scientists are being paid to what their mouth utters. A skilled data scientist is considered an experienced individual who is prolific in various programming languages and is greatly influenced by their workflow. However, all programming languages can be used for data science and study its workflow; the best data science is R and Python. Both of these languages have immense computational power. Apart from these programming languages, statistical methods and a basic understanding of database and its architecture to understand the workflow. To get a grip on data science, it is highly recommended to go for a master's in data science. It can build the existing skills to ensure that a person will go long into the ever-growing and developing world of data science.
Challenges and Limitations of Data Science
The growing data generation at each computing stage has reached the immense availability of datasets, spurs smartphones and computers, the growth of data science. These datasets are complex and difficult to handle if the methods used to handle these datasets are not utilized at the right place. Some instances are obvious that data science is completely reliant on data. Other factors that might challenge data science are inconsistent datasets, small datasets, messy data, or datasets having unreadable formats that are very difficult to make readable. Without having the experience to handle these datasets might result in great data loss, and the loss cannot be compromised.
Moreover, using ineffective algorithms and methods to handle these datasets may incorporate the wastage of time. Young and inexperienced scientists often try to create models that can deal with these datasets but eventually fail because the models are inefficient to deliver the required instance and return meaningless and misleading results. Also, if the data variation is not captured while dealing with these kinds of datasets, it is bound that data science will fail.
Carriers in Data Science

As we already have come across the massive data science arena, data science is always needed for big data. Due to the rapid increase in industrialization and customers' engagements to products, companies tend to keep their data for the future so that they don't have to deal with the same customer as he proceeds to buy more after some time. Hence, there is data everywhere from the ground level to the branches, and to deal with different data variations, only one group of persons is not enough.
For becoming a data scientist, one needs to have multiple data skills. Since data science is the study of all the electronic data present in and around the world, you need to have a grip over certain data recognition, data judging, and situational approaches. Apart from this, technical skills like Python and R, followed by statistics and analytics, are needed. To be precise, technical skills apart from Python and R are segmented skills required at each step of data science.
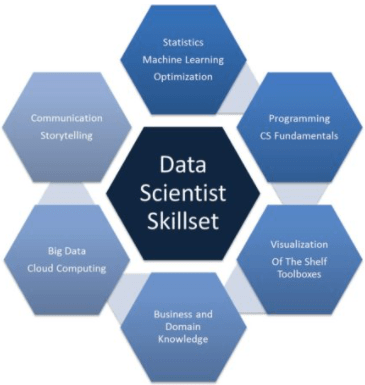
Experienced data scientists or aspiring data scientists are expected to have the expertise of all the skills given in the image above. Most of the skills are technical skills, despite the communication and storytelling skills. Communication and storytelling are important skills in data science. This skill determines how well you are versed with your grip on the aspects. It also ensures that you can deliver quality results if you are well aware of discussing the problem and solution at the organization you're working at. Let's now move ahead and discuss machine learning and how it is different from Data Science.
What is Machine Learning?
Machine learning is a part of artificial intelligence that primarily relates to creating useful models or programs trained to test out various solutions against the data available autonomously. The best result is considered fit for the problem. This usually means that machine learning is designed to handle extreme labor tasks that need extensive human effort. The effort of repeating a particular thing, in the same manner, is considered wastage of time and capital in the industry since humans need consistency, and humans cannot always deliver consistency. Thus, machine learning provides unique solutions for these problems and can deliver better decisions and predictions on complex topics that humans fail to be efficient and reliable.
The power of machine learning is useful to a huge number of industries. Machine learning carries a varied number of possibilities. Most of the technical institutions have opted to teach machine learning from day 1 of academics. Machine learning technology has the potential to transform the lives of individuals. It can solve some of the complex problems of different domains like healthcare, cyber security, and much more.
Limitations of Machine Learning
There are various instances to support these statements. You may have known that machine learning algorithms are better at creating some of the best and efficient results with less footprint and minimum intervention. But, these algorithms need experts to implement. Due to the rapid advancement of machine learning, people usually find it hard to gain an edge over the machine learning algorithms to get the problems solved. Inherently, machine learning, as it sounds, appears like a magic bullet that can answer all your questions and problems; it is not at all powerful like it seems. Yet, the mathematics behind it scares most of the developers. Since machine learning can be termed the advanced mathematical logic that solves problems easily, it is quite tough for programmers to navigate constraints and optimize these algorithms to make them work out on new problems.
There are some more challenging problems where machine learning fails to deliver the correct results. If a problem is being solved using the traditional technique, implementing machine learning may not seem the proper option because it may complicate it instead of simplifying it.
Why Machine Learning?
Since the growth of technology, machine learning has been put into research for quite a few years. Still, it recently has gained tremendous momentum since it is being applied at every nooks and corner of different industries. Moreover, machine learning outlasts making lucrative decisions and creating cost-effective solutions with much less effort when cost-cutting.
Applying machine learning techniques to industries in medicine, healthcare, hiring, or lending might play some ethical concerns because machine learning algorithms are trained based on the data produced by humans. Since this data is associated with social biases, the results will also be based on social norms.
Machine learning operates on algorithms having no explicit rules since most biases remain hidden. Some machine learning algorithms are termed as "black box". You may never know what goes inside and what may come out; you will know what went there. Some popular machine learning implementing organizations like Google is carrying out their research on how neural networks think. This is another instance that addresses social and ethical biases associated with machine learning. In short, machine learning is inclined to the idea of training machines to think like humans, although they can't do it like humans perfectly, but can do some tasks better than humans with less effort and, of course, less cost.
Therefore, machine learning in correlation with data science can be termed one of the tools that can manipulate the data scientist's proposed data. This means that you need a skilled data scientist to operate machine learning algorithms that can organize and orient the data properly by applying proper techniques and tools that mostly constitute the use of numbers or precisely mathematics.
Machine Learning Workflow
The workflow of machine learning, like the name suggests, may appear simple since most people think of it as a machine imitating the tasks done by humans. But machine learning, has gripped almost all the nooks and corners of technological implementations. It is the ambiguity amongst the young machine learning engineers that machine learning is just confined to training models to automate some human tasks that need constant human effort and no errors. Nevertheless, it is treated like a piece of code or an algorithm designed to perform a task, but it is beyond that. See the below explanation covering the workflow of machine learning.
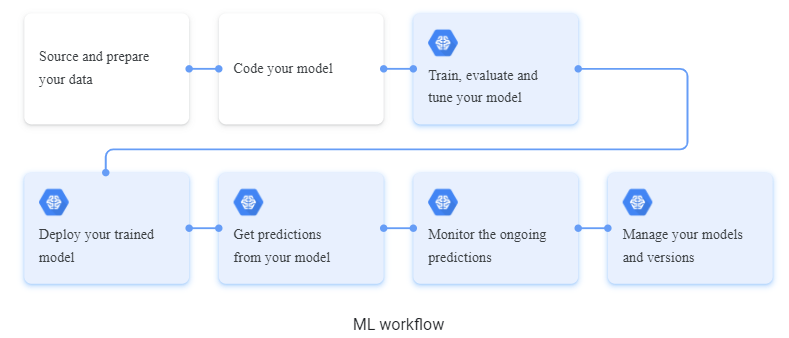
The diagram is given above consists of a high-level overview of the multiple stages of machine learning workflow. The boxes having the color blue indicate where the platform provides API and services.
The first stage of workflow consists of preparing the data coming from the source. Since the nature of data is mostly inconsistent, it is the first step of the machine learning engineer to prepare this data in a proper format and keep it aside. The next step involves coding the model as per requirement, followed by training the models against the data that you kept aside previously. Also, this data is tuned and modeled against the data because the nature of the data may vary. Hence, it becomes necessary that data is tuned finely and is evaluated with hyperparameters so that no error occurs in the next stage of the workflow.
The next step is governed by deploying the model trained against the data you provided. The deployment platform can be anything that suits your model. The results are generated after deployment for the further process, and results are checked if they deliver what you predicted. Since there is a variation of data, the prediction can be different every time. This variation needs to be managed because the predictions are based on the batch, online, or ongoing processes. Therefore, the model has to be again trained to generate the data to learn from the predictions.
The final step consists of managing your models and the version. If you think the model delivers correct results based on what you provide, it may work fine. But if there are any variations in the results, you need to re-manage the model and its version. Versions can be easily managed by version control systems that return to the previous version if the current version is not delivering the expected results.
Thus, each step at machine learning is complex, and the workflow is properly needed to be grasped by the model being trained else it will not work like expected. The steps covered in the workflow of machine learning are iterative. This means that at each step, you need to go back and reevaluate. This reevaluation is important due to the variations of the predictions. It cannot be determined that the variation will be finalized based on batches or individual levels. Thus, you need to go back and check if the model is following the workflow rule at each step.
Skill Evaluation
DATA SCIENCE
To become a data scientist, one must have a great understanding of data analysis tools and techniques. Not only that, one should be very strong with programming abilities. Since data science is not a proper track for a fresher or one who has just entered the data science industry, it needs experts and experienced individuals who have a research and data-driven mindset and know-how to deal with data in all ways possible. This is one of the main reasons why data scientists are paid so high. Based on the carrier perspective, the skills of a data scientist can be split into two categories.
Technical Skills
A good data scientist must have expertise in Computer Science and Engineering. He must be good with Algebra and Statistics. Other technical skills include programming abilities primarily or Python and R.
Along with programming, he must be aware of analytical tools like Hadoop, Spart, SAS, etc., to become familiar with the nature of data science. Additionally, it is an added advantage to have the ability to handle the unstructured data obtained from the various networking domains.
Non-Technical Skills
Apart from technical skills, a data scientist must have exceptional business handling sense, followed by interacting with the team and clients. He must have the enthusiasm and intuit about data and should deliver great communication skills.
Moreover, being a data scientist, you must be aware of the data generation mechanism at each step of the SDLC maintenance process.
MACHINE LEARNING
To move ahead with machine learning skills, one ought to have strong command over basic computational skills. Those computational skills are enlisted below.
Probability and statistics
An individual's experience has a lot of potentials to comprehend the algorithms used in machine learning. These algorithms come from the basis of probability and statistics. Both of these skills are used to develop a grasp of numbers and occurrences. The emphasis of these two skills is important to move ahead with machine learning and train the models.
Data modeling evaluation
Evaluation is a vital element for various machine learning models expected to deliver results at frequent levels. This is done to ensure the reliability in maintaining the measurement method and computing the approaches like regression and classification. Evaluation solves the problem like the occurrence of error or inconsistency thereby forming a proper assessment plan.
Machine learning algorithms
Algorithms play a vital role in machine learning. They form the operational blocks for different test cases and scenarios. As a machine learning engineer or enthusiast, one must be familiar with various machine learning algorithms like Naive Bayes, differential equation and gradient descent, convex optimization technique, and all other necessary algorithm designing methods to gain an edge.
Programming Languages
Although machine learning can be performed in various languages, the best-suited languages include R, Python, Java, and C++. These programming languages have high competencies in machine learning and are used to design models at various individual levels while developing the machine learning model.
Signal processing techniques
The nature of machine learning is based on feature extraction and imitation. As a machine learning enthusiast, you may need strong fundamental knowledge and hands-on experience in signal processing techniques like bandlets, curvelets, contourlets, and shearlets.
Conclusion
Both data science and machine learning are popular technologies that are spreading their legs enormously across the world of computing. These two technologies have deep roots engraved in statistics and probability, and some experts call it high-end mathematics that has eloped with technology. Data science, in particular, is an interdisciplinary sector that has enormous quantities of data and the power of computing that is used to obtain insights into various aspects like performance, growth of the organization, future business model predictions, and whatnot. On the other hand, machine learning is an exciting technology being one of the technology-driven classifications of Artificial Intelligence. Machine learning in contemporary data science deals with the models or machines that are encouraged to learn from their previous experiences by exposing themselves to a dataset.
While both of these technologies that you studied in this article have a wide range of applications in the real world, but cannot be termed as limitless. On the one hand, data science is strong with data. Still, it cannot be implemented without an expert. On the other hand, machine learning needs highly trained individuals who are skilled in mathematics and have great experience of algorithms and their behavior. Hence, there remains a constant demand for a skilled workforce to develop applications using both of these technologies, and the supply is still low due to less enthusiasm and more hype.