DFS Algorithm in C
Introduction DFS Algorithm
DFS, short for Depth First Search, is a graph traversal algorithm used to search all the vertices of a graph in a systematic and structured way. It works recursively by visiting points in the graph and going as far as possible on each branch before returning. The DFS algorithm starts by visiting an arbitrary vertex in the graph, marks it as visited, and then recursively examines all its unvisited neighbors. This process continues until all vertices of the graph have been visited. DFS can be implemented with either recursion or an explicit stack. When using recursion, the algorithm calls itself recursively for each unvisited neighbor of the current vertex. When using an explicit stack, the algorithm pushes each unvisited neighbor onto the stack and jumps from the top of the stack to the next visited vertex. DFS is commonly used for various graph-related problems, such as detecting cycles in a graph, finding connected components, and traversing trees. It can also solve other problems, such as generating permutations, combinations, and subsets. One important thing to note is that DFS may not visit all the vertices of a graph when the graph is disconnected. The algorithm must be run separately for each connected component in such cases. Additionally, DFS can be used to find a path from one vertex of a graph to another, but it may need to find the shortest path between them.
History of the DFS Algorithm
The DFS algorithm has a long and exciting history dating back to the early days of graph theory and computer science. The first recorded use of DFS comes from the work of French mathematician Charles Pierre Trémaux in the 19th century. Trémaux used a variation of DFS to solve the famous "maze problem," which involved finding a path through a maze without dead ends. In the early 20th century, the DFS algorithm was further improved and formalized by several prominent mathematicians and computer scientists, including Edsger Dijkstra, John Hopcroft, and Robert Tarjan. Dijkstra's algorithm, a variant of DFS, is widely used today to find the shortest path in a graph. DFS became even more popular with the rise of computing in the mid-20th century. It was widely used in developing early programming languages and operating systems and helped develop many classic algorithms, including binary search and topological sorting. Today, DFS is a fundamental algorithm in computer science and is used in many applications, including network analysis, social network analysis, and natural language processing. Its simplicity, efficiency, and flexibility make it a powerful tool for exploring and analyzing complex data structures.
How DFS Algorithm works?
Depth First Search, works in depth first when traversing a graph, meaning it searches as far as possible on each branch before returning. The DFS algorithm typically works as follows:
1. To begin, select any vertex as the starting point in the graph.
2. Mark the starting point as visited and add it to the stack or queue to track the current path.
3. Visit each unvisited neighbor of the current vertex in turn. For each neighbor, mark it as visited, add it to the stack or queue, and recursively visit its unvisited neighbors.
4. If the vertex has no neighbors, return to the previous vertex of the stack or queue and continue visiting its neighbors.
5. Repeat this until all vertices of the graph have been visited. A simple example can illustrate the process.
Consider the following undirected graph:
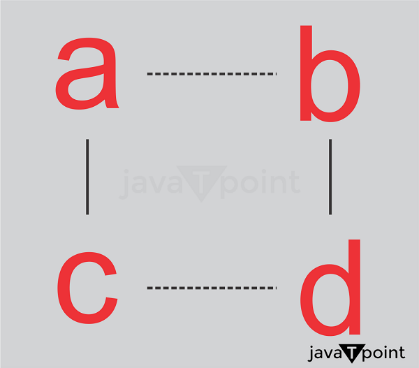
Suppose we start at a. The DFS algorithm works as follows:
- Visit vertex a, mark it as visited, and add it to the stack or queue.
- Visit the unvisited neighbor b, mark it as visited, and add it to the stack or queue.
- Visit an unvisited neighbor d, mark it as visited, and add it to the stack or queue.
- Since d has no neighbors, return to b.
- Visit an unvisited neighbor c, mark it as visited, and add it to the stack or queue.
- Since c has no neighbors, return to a.
- Since a has no neighbors, the algorithm terminates. This example results in the path a -> b -> d -> c.
This is one of many possible paths; DFS can visit the points in any order. DFS can be implemented using either recursion or an explicit stack or queue. The choice of application depends on the specific requirements of the problem to be solved.
C program for DFS algorithm with output
#include <stdio.h>
#include <stdlib.h>
#define MAX_VERTICES 100
typedef struct _graph {
int num_vertices;
int adj_matrix[MAX_VERTICES][MAX_VERTICES];
} Graph;
void DFS(Graph* graph, int vertex, int visited[]) {
visited[vertex] = 1;
printf("%d ", vertex);
for (int i = 0; i < graph->num_vertices; i++) {
if (graph->adj_matrix[vertex][i] == 1 && visited[i] == 0) {
DFS(graph, i, visited);
}
}
}
int main() {
Graph graph;
int visited[MAX_VERTICES] = {0};
printf("Enter the number of vertices: ");
scanf("%d", &graph.num_vertices);
printf("Enter the adjacency matrix:\n");
for (int i = 0; i < graph.num_vertices; i++) {
for (int j = 0; j < graph.num_vertices; j++) {
scanf("%d", &graph.adj_matrix[i][j]);
}
}
printf("DFS traversal starting from vertex 0: ");
DFS(&graph, 0, visited);
return 0;
}
This program takes input for the number of vertices and the adjacency matrix of a graph and then performs a DFS traversal starting from vertex 0. The output is the list of vertices visited during the traversal.
Here's an example output for a sample input graph:
Sample Output
Enter the number of vertices: 5. Enter the adjacency matrix: 0 1 1 0 0 1 0 0 1 1 1 0 0 1 0 0 1 1 0 1 0 1 0 1 0 DFS traversal starting from vertex 0: 0 1 3 4 2
In this example, the input graph has five vertices, and the adjacency matrix indicates the edges between them. The DFS traversal starts from vertex 0 and visits the vertices in the order 0, 1, 3, 4, 2.
Applications of the DFS algorithm
DFS, or Depth First Search, is a versatile algorithm that can be used in many applications involving graph traversal and analysis. Here are some of the more common applications of DFS:
- Finding Connected Components: DFS can be used to identify all connected components in a diagram. The algorithm starts at an arbitrary vertex and explores all connected vertices in this application. All unvisited vertices are used as starting points for new DFS searches until all connected components are identified.
- Identifying Cycles: DFS can identify cycles in a chart. This is done by keeping a list of vertices visited during the search and checking for cycles identifying possible back edges (edges connecting a vertex to an ancestor in the DFS tree). If a trailing edge is found, it indicates the presence of a cycle.
- Topological sorting: DFS can be used for topological sorting of a directed acyclic graph (DAG). In this application, the algorithm gives each vertex a temporary label when it is first visited and a permanent label when all its neighbors have been visited. The vertices are then sorted in reverse order of their fixed signs, resulting in a topologically ordered list.
- Path Find: DFS can be used to find a path between two graph vertices. For this purpose, the list of visited points during the search and the journey record from the starting point to the current high point is kept. The stored path is returned as the solution if the destination is reached during the search.
- Network Flow Analysis: DFS can analyze network flows in a graph. This involves assigning capacity to the graph's edges and then using DFS to find additional paths (flow-increasing paths) from the source to the sink. This can be used to find the maximum current in the network.
- Maze creation and solving: DFS can be used to create and solve mazes. When creating a maze, the algorithm starts at a random cell and uses DFS to traverse the maze until all cells have been visited. In the maze solution, the algorithm explores the maze using DFS until the target cell is found.
Advantages of the DFS algorithm
The Depth First Search (DFS) algorithm has several advantages, making it popular for graph traversal and analysis.
- Simplicity: DFS is a relatively simple algorithm, requiring only basic data structures such as stacks or queues to keep track of visited vertices and the current path.
- Memory efficiency: DFS uses less memory than graph traversal algorithms such as BFS (breadth first). This is because DFS only needs to store the current path, while BFS needs to store all points at each level.
- Versatility: DFS is a versatile algorithm that can be used in many applications, including connection component finding, cycle detection, topological sorting, pathfinding, network flow analysis, and maze generation and solving.
- Time efficiency: In some cases, DFS can be faster than other algorithms, such as BFS, for certain types of graphs. This is because DFS explores the graph along a single path, which can be more efficient for specific problems.
- Flexibility: DFS can be implemented using recursion or an explicit stack or queue, providing flexibility in choosing the best implementation for a given problem.
- Spatial complexity: DFS can have better spatial complexity in specific scenarios than other graph traversal algorithms. DFS is a robust algorithm that can be applied to many problems and balances efficiency, simplicity, and flexibility.
Disadvantages of the DFS algorithm
Although the DFS (Depth First Search) algorithm has several advantages, it also has some disadvantages that must be considered when choosing the appropriate algorithm for a given problem. Here are some of the main disadvantages of DFS:
- Completeness: DFS cannot find the shortest path between two vertices. Sometimes, it may find a longer path before finding the shortest one, which can be a problem for specific applications.
- Complexity of dense graphs: DFS can be inefficient for dense graphs because it can explore many unnecessary paths and vertices. As a result, runtime and memory usage may increase.
- Danger of infinite loops: DFS can get stuck in infinite loops if the algorithm does not detect cycles in the graph. This can be a severe problem, especially for large graphics.
- Sensitivity to starting point: The order in which DFS vertices are explored depends on the starting point. Different starting points can produce different results, which can be problematic for some applications.
- Stack Overflow Vulnerability: A recursive implementation of DFS can cause stack overflow errors if the graph depth is too large. This can be mitigated by using an explicit stack instead of recursion, but it makes the implementation more complex.
DFS is a robust algorithm with many advantages, but its disadvantages must be carefully considered before applying it to a specific problem. In some cases, other algorithms, such as BFS or Dijkstra's algorithm, may be more suitable.
The Complexity of the DFS algorithm
The time and space complexity of the DFS (Depth First Search) algorithm depends on the
size and structure of the graph. The time complexity of DFS is O(|V| |E|), where |V| is the number of vertices, and |E| is the number of edges in the graph. This is because the algorithm visits each vertex and edge at most once, and the time required to visit each vertex or edge is constant. But in the worst case, if the graph is complete (i.e., every vertex is connected to every other vertex), the time complexity of DFS becomes O(|V|^2).
The space complexity of DFS is O(|V|), where |V| is the number of vertices in the graph. This is because the algorithm uses a stack to track the current path, and the maximum size of the stack is equal to the depth of the recursion tree, which is equal to the number of vertices in the graph. In some cases, such as when an explicit stack is used instead of recursion, the DFS state complexity can be reduced to O(|E|), where |E| is the number of edges in the graph. The worst-case time and space complexity of DFS may not always be the most important factor when analyzing an algorithm. In practice, the structure of the graph and the specific problem to be solved can significantly affect the actual runtime and memory usage of DFS.
Conclusion
Depth First Search (DFS) is a popular algorithm for traversing a graph or tree data structure. The algorithm starts at the root node (or any other node) and explores as many branches as possible before returning. DFS uses the stack data structure to track which nodes are visited. One of the main advantages of DFS is that it requires very little memory compared to other routing algorithms, as it only needs to store nodes in the current path. However, it may need to find the shortest path between nodes because it explores deeper graph levels before moving to lower levels. The DFS algorithm can be implemented recursively or iteratively. In the recursive version, the algorithm calls itself to visit neighboring nodes, while in the iterative version, it uses the stack to keep track of the visited nodes.
In summary, DFS is a powerful and versatile algorithm that can be used to solve various problems involving graph or tree data structures. Its simple implementation and low memory requirements make it popular among developers and can be easily adapted to different needs. However, its suboptimal nature for finding the shortest path may make it unsuitable for specific applications.