What is Apache Empire-DB?
Apache Empire-DB is an open-source Java library which provides a high-level object-oriented API for accessing data from RDBMS (Relational Database Management System) through JDBC (Java Database Connectivity). So, when we need to access the data from the database in any java module or project, make use of Apache Empire-DB. It allows developers to focus more on SQL centric approach than the traditional OMR, i.e., a programming technique used for converting data between incompatible type systems using object-oriented approach.
It was developed by Apache Software Foundation under Apache License 2.0 which supports cross-platform operating systems (the computer software which can be implemented on multiple computing platforms).
Why Apache Empire-DB?
There are several data persistence solutions such as Hibernate, iBATIS, etc. which are popularly used for accessing the data in approx thousands of projects.
So, what is the reason that we need Empire-DB?
Let's understand by comparing the traditional OMR approach with SQL centric approach, i.e., Empire-DB with the help of following comparison points:
- Database Schema Definition
Generally, to work with something, we need to understand it. So, in order to work with each relational data persistence, we need to understand the data model. To do so, Hibernate uses two ways, i.e., XML files and Java annotations. Annotations have recently been introduced, which are used to simplify the object relational mapping by providing the metadata or information about data. The metadata provided by the annotations helps Hibernate to know how and where the object persists in the database. This information is also helpful for our application logic so that we may access it through our code rather providing the same information redundantly. For example, sometimes, a user tries to understand the flow of the code through the comment section as it becomes easy for the user to understand the code.
Note: We cannot directly reference a particular annotation property from Java code in contrast to Java object ‘s property.
Following example shows how to access metadata using annotations:
Method field = Employee.class.getDeclaredMethod(“getFirstname”, new Class(0));
javax.persistence.Column col= field.getAnnotation(javax.persistence.Column.class);
int length=col.length();
Same code using Empire’s DB will be written as:
Int length = mydb.EMPLOYEES.FIRSTNAME.getSize();
Annotation has the following issues that make it complex:
- Lack of Compile-time safety
- Code complexity on the client side
- Cannot be used for application logic
- Redundancy of metadata(data about data)
- Metadata provided is sometimes not sufficient
- Hibernate Validator is also required that makes mapping and accessing of code less manageable and readable.
Therefore, Empire-DB seems to be a better option to define the database schema.
- Data Object Definition
Hibernate, and JPA (Java Persistence API) uses JavaBeans or POJO (Plain Old Java Object) to access and store data. JavaBeans or POJO contains member fields as well as a getter and a setter method for each of the columns of the corresponding table. But, it leads to complex code for large data models. Although, Hibernate generates the code automatically using reverse engineering (a path followed from final to initial) but for large projects or code, the problem arises if we make any change manually in the mapping code or in bean and want to keep that change, hence automatic tools becomes problematic. So, it is rare to maintain the code manually. Another problem arises when we need to copy some amount of code from one object to another, then what's the need for having these getter and setter at first?
For resolving the above problems, Empire-DB offers dynamic beans where we have only one generic getter and setter method for each entity that has already been implemented. Furthermore, there is no need to create multiple classes; the same class will be enough. So, we suggest you to create individual data object class for each database entity because our first requirement is type safety as we want our internal code to rely on certain entities.
Secondly, when our project will be in the growing phase, we may override some methods or implement some new methods. Therefore, Empire-DB is a better option for defining data object.
- Dynamic Queries
Hibernate offers a query language known as Hibernate Query Language(HQL) and a criteria API for handling dynamic queries, but it becomes complicated and unsafe when we use joins or constraints. Thus, criteria API is better from the respect but has some limited capabilities. Hibernate works with full database entities that require far more attributes that need to be loaded from the database, so it becomes difficult for HQL and criteria API to handle.
Therefore, Empire-DB provides string free literals as well as intuitive API. It enables the user to build any SQL statement including the select clause and can be used with any POJO not necessarily with full-featured entity set.
Features of Empire-DB
- Zero configuration needed
- No need to learn XML schemas or annotations as everything is in Java
- Metadata is accessed through standard Java code
- It also supports data model changes (DDL) at runtime with full dynamic bean support.
- It works with dynamic and type-safe field access.
DAO Pattern
Over several years, many business applications rely on RDBMS, which is easily available to Java code using JDBC. JDBC is simple to use at a lower cost, but its maintenance is not an easy task. Extensively, Sun Microsystems introduced
Data Access Object (DAO) that describes an interface for abstraction and encapsulation to access the data source. DAO provides some specific data operations without exposing the private information of the database. It maps the application calls to the persistence layer. However, the main target of DAO and other persistence solutions such as Hibernate is on data but what about metadata that includes information about value precision, maximum field length, etc. and is often necessary for displaying data?
Empire-DB tackled the situation by taking both data and metadata into consideration. For metadata support, Empire extended the traditional DAO by pioneering a new
Data Info Object (DIO).
What is DIO?
A DIO is a container that contains all the detailed information (metadata) about a particular entity attribute and enables the user to add on some specific metadata according to their requirements.
Empire’s Extended DAO Design (DIO)
The below diagram represents how DAO looks like:
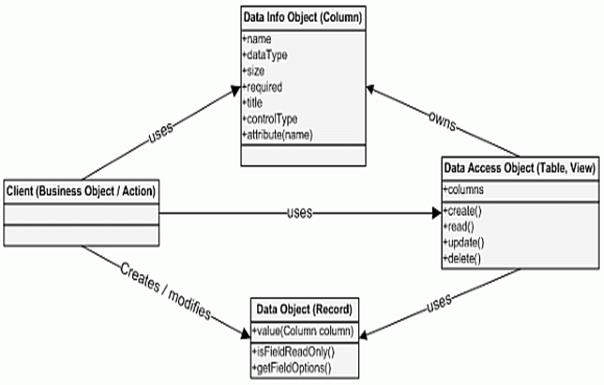
As we have already seen that Empire-DB works with dynamic JavaBeans, which gives the advantage to easily override the getter and setter methods and implement some new methods. Another important point about Empire-DB is that it uses data objects rather creating them.
Handling data and metadata
Many persistence solutions are designed to work with full database entities, but sometimes it seems undesirable and inefficient to work with the full database. Fortunately, Empire-DB supports working with full database entities as well as working with complex and varying query results. As a result, Empire-DB distinguishes between read-only data and the full entity records which are updateable. This distinguishing behavior affects access to both data as well as metadata. However, for updateable more metadata is required, so, the distinction is also made on the metadata side that distinguishes a column expression for read-only data and a full column for updateable data. For implementing such behavior/column, Empire DB describes four interfaces and their relationships, which can be understood by the below matrix:
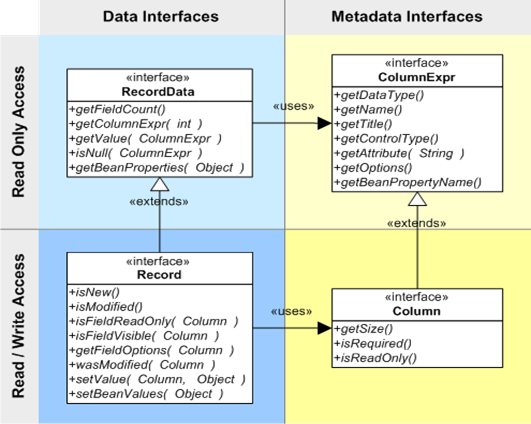
In Empire-DB, Record and Column are two different things where the Record holds data, and Column holds the metadata. For accessing data, Empire-DB distinguishes between record data which is read-only data, SQL query result, and a full entity record which is returned by a Data Access Object via tables or views. Correspondingly, it distinguishes between a column expression that enables a display for displaying a value metadata and a full-featured column which provides the information needed for data input.
While working with Empire-DB, the following classes will be used for implementing the interface.
| Interface |
Implementations provided By Empire-DB |
| Record Data |
DBRecordData, DBReader |
| Record |
DBRecord |
| Column Expr |
DBColumnExpr, DBAliasExpr, DBConcalExpr,etc. |
| Column |
DBColumn, DBTableColumn, DBViewColumn |
Note: We can also implement our own objects using these interfaces.
The principle of string-free coding
The following issues introduced the principle of string-free coding:
- Use of string literals in data persistence led to various code quality issues. It lamed the developers while developing the code, maintaining the code, and required extensive and expensive testing for balancing the code.
- A compiler is the most powerful tool for detecting and revealing errors; thus no XML file should be used, and code should be perfectly written so that compiler may compile the code in the best possible manner.
Practically, to understand the above two points, users need to work with object references rather than string literals. For example,
Instead of writing this code:
StringBuilder cmd = new StringBuilder();
…
cmd.append(“Employee.lastname like ‘ ” +name+ “%’ “);
We can write it as:
DBCommand cmd = db.createCommand();
…
cmd.where(EMPLOYEES.LASTNAME.like( name+”%” ));
Downloading Apache Empire-DB
Following steps will help you get started with Apache Empire-DB:
- Download the Empire-DB distribution package :
- Unzip the file.
- Open Eclipse, choose File/import then select any of your existing projects into the workspace, when prompted for a root directory, choose "…/empire-db-2.0.0(or any version)/examples/DBSample".
- Open DBSampleApp.java file and set a breakpoint over the first line of the main method.
- Now, from Run menu, select Debug as/Java Application and when prompted for a Java application class, select the SampleApp-de.esteam.sample.db.
The sample execution must begin now and will stop at the breakpoint.
Finally, the user will be able to work with the code.
Note: To build and run the examples make use of
Apache Maven.
Advantages of Empire-DB
- Empire-DB provides maximum compile-time safety via the principle of string free coding, which leads to better code quality and maintainability.
- Reduce redundancy due to metadata support
- Generation of dynamic SQL queries for SELECT, UPDATE, INSERT or DELETE statements.
- Provides type-safety and avoids the use of string literals
- Easy to learn through SQL command API.