Different Types of Deep Learning Algorithms
Introduction
Artificial neural networks are used in deep learning to process massive amounts of data and carry out complex calculations. This particular kind of machine learning is predicated on the composition and operations of the human brain.
Machines are trained by deep learning algorithms through example-based learning. Deep learning is frequently used in healthcare' e-commerce' entertainment' and advertising sectors.
In artificial intelligence' deep learning is a branch that processes and comprehends data by modelling human brain networks. It uses deep neural networks to extract intricate patterns and features from unprocessed data' which comprise several interconnected layers. Natural language processing' computer vision' and speech recognition are just a few fields this technology has completely transformed. Deep learning has made advances in linguistic translation' image identification' and recommendation systems possible. It continues to spur innovation' offers enormous promise for resolving challenging issues' and advances our knowledge of complicated data structures by utilizing massive volumes of data and strong processing capabilities.
How Deep Learning Works?
Though self-learning representations are a hallmark of deep learning algorithms' they rely on artificial neural networks (ANNs) that mimic how the brain processes information. Algorithms utilize unknown input distribution factors during training to categorize objects' extract features' and identify meaningful data patterns. This is multi-level' with the models being built using algorithms' much like when robots are trained for self-learning.
Deep learning models employ multiple algorithms. Specific algorithms are better adapted to carry out particular jobs' even though no network is thought to be flawless. A thorough understanding of the primary algorithms will help you make the appropriate decisions.
What is Neural Network in Deep Learning?
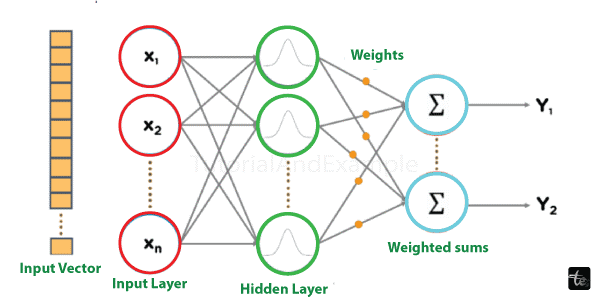
The above figure can be used to graphically depict the basic structure of a neural network' which consists of three primary components:
1. Input Layer
2. HiddenLayer
3. Output layer
A neural network' also known as an artificial neural network' is depicted in the above figure as having only one hidden layer. Deep neural networks' on the other hand' derive their name from the fact that they have multiple hidden layers. Our model learns to produce the final product through the interconnectedness of these hidden layers.
Information is provided to each node in the form of inputs' which are then multiplied by random weight values and added with a bias before being calculated. The output-determining node is then identified by applying a nonlinear or activation function.
Design of Deep-Learning Neural Networks
Artificial neural networks employ activation functions that function similarly to logic gates. Let's say we have an OR gate' and we need the output to be 1. The input values must be passed in either 0'1 or 1'0. Various activation functions' such as Sigmoid' ReLU (Rectified Linear Unit)' and occasionally a combination of activation functions' are used by different deep learning models. We have looked at the parallels between deep learning architectures and neural networks. However' neural networks are unsuitable for handling unstructured data' such as pictures' videos' sensor data' etc. Deep neural networks are used for the many hidden layers —sometimes as many as thousands — that these kinds of data require.
Types of Algorithms Used in Deep Learning
1. Convolution Neural Networks
A Convolutional Neural Network (CNN) is a specific type of deep learning model for visual data. CNNs utilize convolutional layers inspired by the human visual system to automatically extract features from images and perform tasks like object detection and image recognition. With uses in facial identification' medical image analysis' and other fields' they have transformed computer vision and are now an essential component of contemporary machine learning for visual data.
How CNN Works?
Three fundamental components make up a CNN.
1. Convolution layers
2. Pooling layer
3. Full-Connected Layers
The most critical component of convolutional neural networks is the convolutional layer. The parameters of each layer use a set of filters' or kernels' which can be thought of as the layers' neurons. They produce the output with weighted inputs based on the input size (a fixed square)' also known as a receptive field.
Feature maps are produced when these filters are applied to the input image. One filter's output was applied to the layer before it. A particular filter is drawn over the whole prior layer by moving each pixel of the image one at a time. A specific neuron is triggered for every point' and the results are gathered intoafeaturemap.
The below diagram describes the working of CNN

2. Long Short-Term Memory Networks (LSTMs)
Recurrent neural networks (RNNs) can learn and retain long-term dependencies' and LSTMs are one kind of RNN that can do this. The default setting is to have past knowledge for extended periods.
Throughout time' LSTMs hold onto information. Because they can recall prior inputs' they are helpful in time-series prediction. Four interacting layers in an LSTM are arranged in a chain-like arrangement that allows for unique communication between them. LSTMs are commonly employed in speech recognition' music creation' pharmaceutical research' and time-series prediction tasks.
How does it work?
A kind of recurrent neural network (RNN) utilized in natural language processing and machine learning is called Long Short-Term Memory (LSTM). The vanishing gradient issue with conventional RNNs is the focus of LSTM design. They have an information-controlling memory cell with self-regulating gates. These gates comprise an input gate for incoming data' a forget gate for outgoing data' and an output gate for the output in its final form. Because of their capacity to learn and retain patterns over lengthy periods' long-range dependencies in sequential data can be captured by LSTMs' which makes them useful for tasks like language modeling' time series prediction' and speech recognition.
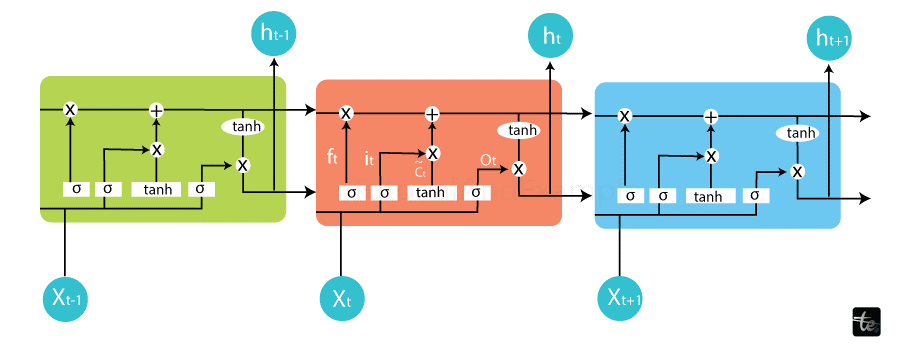
3. Recurrent Neural Network
One kind of artificial neural networks called recurrent neural networks (RNNs) is made to process sequential input' where the elements' order is essential. RNNs can preserve and update a hidden state that contains information from past time steps because they have connections that loop around on themselves' in contrast to feedforward neural networks. This makes speech recognition' natural language processing' and time series data problems a good fit for RNNs.
Text generation' sentiment analysis' and machine translation are just a few of the applications that RNNs are useful for due to their ability to process inputs of random length. Every time each element in the sequence is applied' they update the hidden state by iteratively using the same set of weights and biases.
However' classical RNNs are limited by the vanishing gradient problem to capture long-range dependencies in data. More sophisticated RNN designs' such as the Gated Recurrent Unit (GRU) and Long Short-Term Memory (LSTM)' have been created to solve this problem. These structures include memory cells with gating strategies.
How does it work?
- Sequential Processing: RNNs are made for sequential data where order is necessary' such time series or natural language text.
- Recurrent Connections: They have a hidden state that represents the current context' allowing information to flow from one time step to the next through recurrent connections.
- Weight Sharing: RNNs can handle sequences of different lengths since they use the same weights and biases at every time step.
- Forward Pass: RNNs use an input and the prior hidden state at each time step to generate an output and update the secret state.
- Vanishing Gradient: Long-range dependencies are difficult for traditional RNNs to capture because of vanishing gradients.
- Gating Mechanisms: In order to handle the vanishing gradient issue' advanced RNN architectures like LSTM and GRU include gating mechanisms to regulate the information flow.
- Long Short-Term Memory: To store and recover information over lengthy sequences' LSTM memory cells have input' forget' and output gates.
- Gated Recurrent Unit: By integrating the input and forget gates' GRU streamlines and improves the computational efficiency of LSTM.
- Flexible Uses: RNNs can be applied to a wide range of tasks' including sentiment analysis' speech recognition' translation' and text production.
- Challenges: Recent models' such as Transformers' have gained popularity for many sequence-related tasks due to their enhanced efficiency and performance; nonetheless' RNNs are sensitive to the choice of hyperparameters and can be computationally expensive.
4. GANs' Generative Adversarial Networks
The generative deep learning algorithms known as GANs produce new data instances that bear similarities to the training data. A generator that learns to create fictitious data and a discriminator that gains knowledge from it make up the two parts of a GAN.
Over time' more and more GANs are being used. For dark-matter studies' they can be employed to simulate gravitational lensing and enhance astronomical views. By using image training to recreate low-resolution' 2D textures in older video games in 4K or higher resolutions' game makers can employ GANs to improve such textures.
How does it work?
Generative Adversarial Networks (GANs) are neural network algorithms that are used to generate realistic data. They use a two-network configuration:
It generates data samples from random noise.
It is a discriminator because it distinguishes between actual and fabricated data.
The GAN algorithm works via ten steps:
- Initialization: Set the generator and discriminator weights at random.
- Data Generation: The generator creates fictitious data out of noise.
- Real Data: The discriminator is given real data.
- Discrimination: The discriminator assesses both genuine and fictitious data.
- Losses: Compute the losses for both networks.
- Update Generator: Reduce generator loss by adjusting generator weights.
- Update Discriminator: Adjust the weights of the discriminator to maximize its loss.
- Repeat: Iteratively train the neural networks.
- Convergence: Stop when the desired degree of quality is obtained.
- Generation: The trained generator generates high-quality data.
As a result of this adversarial process' the generator generates data that is more realistic.
A sample of Generative Adversarial Networks architecture can be found below:
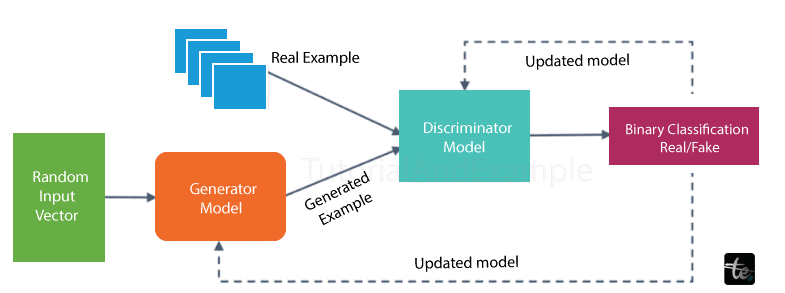
5. Multilayer Perceptrons
Multilayer Perceptrons (MLPs) are a fundamental concept in the field of deep learning' making them an excellent starting point for understanding this technology. An MLP is a type of feedforward neural network distinguished by its several layers of perceptrons' each of which has activation functions.
An MLP is made up of an input layer and an output layer' with each layer fully coupled to the next. Surprisingly' while the input and output layers normally contain the same number of neurons' MLPs can have one or more hidden layers in between. This adaptability enables MLPs to simulate complex' nonlinear relationships within data' making them useful for a wide range of applications.
MLPs are adaptable and have led the way for more sophisticated deep learning architectures' proving the capability of neural networks in a variety of domains. They serve as the base for many cutting-edge AI systems' serving as a solid platform for delving deeper into the field of deep learning technologies.
How does it Works?
- Multilayer Perceptrons (MLPs) are multilayer feedforward neural networks. Their operations can be summed up in ten points:
- MLPs are made up of input and output layers' which have the same number of neurons as the data's input and output dimensions.
- Hidden Layers: The model may capture complex patterns by having multiple hidden layers between input and output.
- Neuron Interactions: Neurons in one layer communicate with all neurons in the following layer.
- Weighted Sum: Neurons use a weighted sum of their inputs to calculate their output.
- Activation Function: To introduce non-linearity' the weighted sum is routed via an activation function.
- MLPs are trained using labelled data to learn the underlying patterns.
- Errors are backpropagated across the network to alter weights.
- A loss function evaluates the performance of a model.
Optimization methods are used to fine-tune the model by minimizing the loss function.
A sample of Multilayer Perceptron's architecture can be found below:
MLPs make predictions or classifications for new input data after they have been trained.
6. Radial Basis Function Networks
Radial Basis Function Networks (RBFNs) are a subset of feedforward neural networks that are distinguished by their successful usage of radial basis functions as activation functions. There are three basic layers in this neural architecture: an input layer' a hidden layer' and an output layer.
The input layer acts as a data entry point' accepting features or patterns to be processed. It has a direct connection to the buried layer' which contains the substance of RBFNs. Radial basis functions' which are specialized non-linear functions' make up the hidden layer. These functions' which are centred on specified data points' calculate the degree of similarity between input patterns and these centres. This trait enables RBFNs to capture intricate non-linear correlations in data.
Radial basis functions are particularly intriguing since they activate when the input pattern closely fits their centre and gradually lose influence as the distance from the centre grows. This characteristic allows RBFNs to model complicated and non-linear patterns.
RBFNs are a distinct alternative to traditional neural networks in that they emphasize interpretability and localized decision boundaries.
How does it Works?
- Input Reception: RBFNs begin by receiving input data through the input layer.
- Hidden Layer Activation: The input is coupled to the hidden layer' which comprises radial basis functions. These functions are centred on certain data points.
- Similarity Computation: Radial basis functions compute activation values by measuring the similarity between the input data and their corresponding centres.
- Weighted Sum: The activation values are then weighted and totalled within the hidden layer.
- Non-Linear Transformation: The weighted total is subjected to a non-linear transformation' which improves the network's ability to capture complicated patterns.
- Output Layer: The transformed information is sent to the output layer' which typically contains neurons for prediction or regression.
- RBFNs are trained on labelled data' with the centre positions and weights of the radial basis functions adjusted.
- Error Minimization: Using optimization techniques' the network minimizes mistakes by fine-tuning the centres and weights.
A sample of Radial Basis Function Networks architecture can be found below:
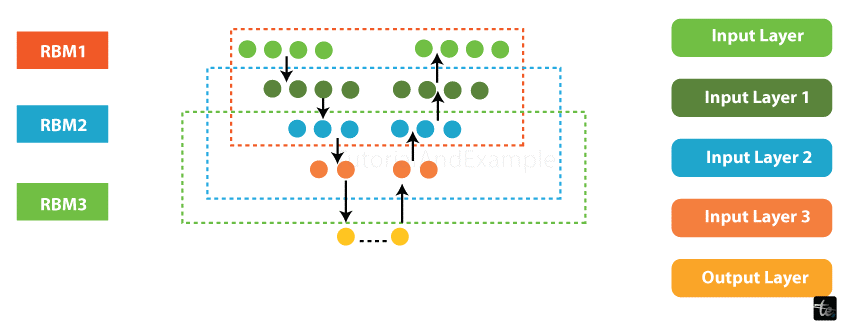
7. Deep Belief Networks
DBNs are generative models with numerous layers of stochastic' binary-valued latent variables known as hidden units. They are made up of stacked Restricted Boltzmann Machines (RBMs) linked together by inter-layer connections. Each RBM layer communicates with the layers above and below it' providing for efficient information flow.
Image recognition' video recognition' and motion-capture data processing all benefit from DBNs.
How does it Works?
- Intense learning techniques are used to train DBNs. The layer-by-layer method used by the greedy learning algorithm is how the top-down' generative weights are learned.
- On the top two hidden levels' DBNs execute the Gibbs sampling processes. In this step' a sample is taken from the RBM that is represented by the top two hidden layers.
- DBNs use a single iteration of ancestral sampling through the remaining parts of the model to extract a sample from the visible units.
- DBNs discover that their values may be deduced from a single' bottom-up pass for all latent variables in every layer.
- A sample of DBN architecture can be found below:
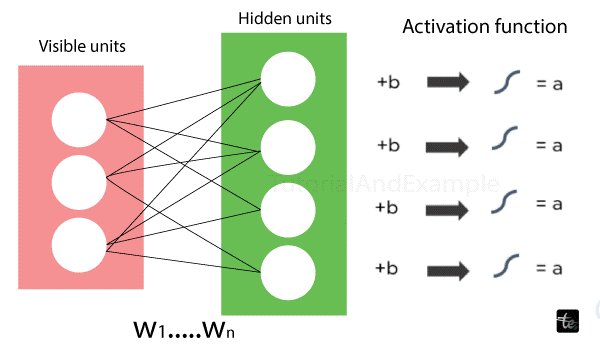
8. Restricted Boltzmann Machines (RBMs)
Geoffrey Hinton's Restricted Boltzmann Machines (RBMs) are stochastic neural networks designed to learn from a probability distribution across input data. They are divided into two layers: visible and hidden units with limited linkages between them. RBMs are adaptable and can be used to reduce dimensionality by effectively capturing important features in high-dimensional data. They perform well in classification' regression' and collaborative filtering tasks' which makes them useful in recommendation systems. RBMs also function as feature learners' discovering informative representations from raw data. They are also employed in topic modelling to aid in the extraction of latent topics from text corpora. Deep Belief Networks (DBNs) are built on RBMs' which contribute to their power in deep learning applications.
How does it work?
RBMs consist of two layers:
- Visible units
- Hidden units
- All hidden units are related to every visible unit. RBMs lack output nodes and have a bias unit that is coupled to every visible and hidden unit.
- The forward pass and backward pass phases comprise RBMs.
- After receiving the inputs' RBMs convert them into a string of numbers that are used to encode the inputs for the forward pass.
- RBMs mix a single overall bias and each input's unique weight. The output is sent to the hidden layer by the algorithm.
- RBMs translate that set of numbers to create the reconstructed inputs during the backward pass.
- Reconstruction-by-mixing (RBM) combines individual weight and general bias with each activation' then sends the output to the visible layer.
- In order to assess the quality of the output at the visible layer' the RBM compares the reconstruction with the original input.
- An illustration of how RBMs work is shown below:
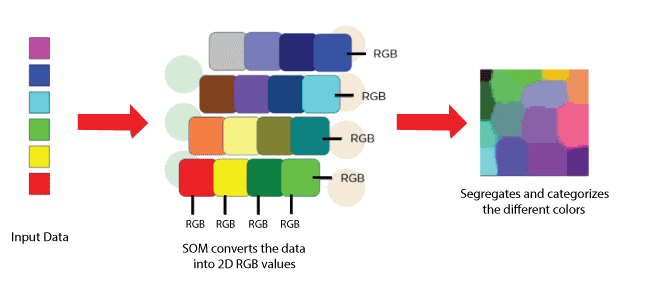
9. Self-Organizing Maps
SOMs were developed by Professor Teuvo Kohonen and allow data visualization by using self-organizing artificial neural networks to reduce the dimensions of the data.
The challenge of high-dimensional data being difficult for humans to see is one that data visualization aims to address. SOMs are designed to aid users in comprehending this high-dimensional data.
How does it work?
- After setting each node's weights initially' SOMs select a random vector from the training set.
- To determine which weights are the most likely input vector' SOMs look at each node individually. The Best Matching Unit (BMU) is the name given to the winning node.
- SOMs learn about the BMU's neighborhood' and as time goes on' there are fewer neighbors.
- The sample vector receives a winning weight from SOMs. A node's weight varies more with proximity to a BMU.
- The neighbor learns less the farther it is from the BMU. For N iterations' SOMs repeat step two.
An illustration of how Self-Organising Maps work is shown below:
View a diagram of a multicolored input vector below. A SOM receives this data and transforms it into 2D RGB values. Ultimately' it divides and sorts the different colors.
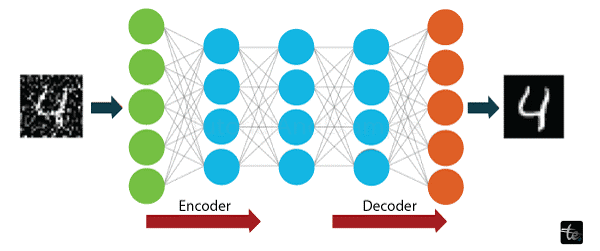
11. Autoencoders
Developed by Geoffrey Hinton in the 1980s' autoencoders are a unique kind of feedforward neural networks in which the input and output layers are mirror images of one another. These networks operate within an unsupervised learning environment and are used in various applications. Autoencoders' which are trained to accurately replicate input data at the output layer' are essential in many different industries. They help with medication creation in pharmaceutical discovery by deciphering intricate molecular structures. Autoencoders are used in popularity prediction to identify patterns and correlations in data' hence predicting trends. These networks are very good at image processing tasks like feature extraction and denoising. Autoencoders are fundamental to fields that require effective unsupervised learning' data reconstruction' and pattern recognition because of their capacity to learn robust representations of data via an encoding-decoding process.
How does it Works?
Autoencoders work by taking in an input and using encoding to convert it into a more compact representation. The autoencoder neural network receives the input when it comes to ambiguous images. The picture is first compressed into a smaller representation by the autoencoder. The network then decodes this condensed representation with the goal of accurately reconstructing the initial input. Autoencoders are helpful for tasks like picture denoising and dimensionality reduction because they enable the network to learn relevant features and patterns in the input. The model's overall data representation skills are improved by the iterative cycles of encoding and decoding' which improve the model's ability to collect crucial information.
An illustration of how Autoencoders work is shown below:
Pros Of Deep learning algorithms
- Deep learning algorithms provide unmatched capacity to process large and intricate datasets' allowing for enhanced feature extraction and pattern detection.
- They are excellent at identifying complex correlations among data' which promotes increased precision in tasks such as voice and image recognition.
- Deep neural networks' hierarchical nature makes hierarchical feature learning easier' enabling models to automatically pick up on and adjust to a variety of representations.
The adaptability of deep learning drives disruptive advances across multiple domains' such as natural language processing' healthcare' and finance. Because of their versatility' scalability' and constant performance enhancement' deep learning algorithms are indispensable instruments in modern machine learning applications.
Cons Of Deep learning algorithms
Deep learning algorithms have several disadvantages despite their advantages.
- They frequently need a lot of processing power' which raises the cost of training and energy usage.
- Large' labelled dataset requirements might be a barrier' particularly in fields where obtaining such data is difficult.
- Interpretability is still a problem since sophisticated neural networks can operate as "black boxes'" making it difficult to comprehend how they make decisions.
- Another prevalent problem is overfitting' in which models function well on training data but poorly on fresh' unexplored data.
- Furthermore' adjusting hyperparameters can take a lot of time.
- Deploying deep learning algorithms also presents significant issues related to potential biases in the training data' privacy concerns about data' and ethical considerations.