LSTM PyTorch
LSTM Library
The LSTM library is the Long Short-Term Memory network; this network will predict future values by considering the previous memory. This LSTM library is based on the time model; it will predict the change of the dataset with time. The LSTM will perform the operations on the dataset with the help of the recurrent neural network method; it is a technique in which the nodes will be connected cyclically; any change in the node will affect the operation of the next node. Let us use this library to predict the future values of the stock with the help of the past values of the stock values. The data prediction will be performed with the use of machine learning.
Recurrent Neural Networks
The recurrent neural network is a process which sequentially takes the input. Here, we must consider the previous input's information to compute the current step's output. This process will allow the neural network to carry the information simultaneously rather than keeping all inputs independent. The main problem while dealing with recurrent neural networks is the problem of vanishing.
This problem will occur while backtracking the training process of the recurrent neural networks due to the chain rule. This will cause either the gradient to shrink exponentially or blow up exponentially. If the gradient is very small, it will prevent the weights from updating themselves and learning themselves, and if the gradient is very large, it will cause the model to be very unstable. So, we can finally conclude that the recurrent neural networks cannot work with long sequences of data and cannot hold the data for the long term, so these recurrent neural networks are "short-term memory" holders.
Working of LSTM
The working of the LSTM is similar to the RNN's, but the only difference is its gating mechanism. The Long Short-Term Memory network works with long-term memories, whereas the recurrent neural networks are designed to work only with short-term memory. Long-term memory is very important when dealing with Natural Language Processing (NLP) or time-series and performing sequential tasks. Let us consider an example of the data dealing with the car. He will mention that he “has an Inova car” after some other steps, adding irrelevant information, and finally mention that “the Inova is-------”.
The RNN is a short-term memory which will not be able to obtain the starting memory that “Inova is a car” this information will get erased, but the LST is a long-term memory; it can give the final output that “the Inova is a car". The Long Short-Term Memory network will filter the irrelevant text and give the relevant text to the final data.
Internal Working of LSTM:
The LSTM can hold the long-term data compared to the RNN network; it's a gating mechanism; the internal structure of the LSTM is that it will connect every gate very accurately so that it can hold the data for a long time.
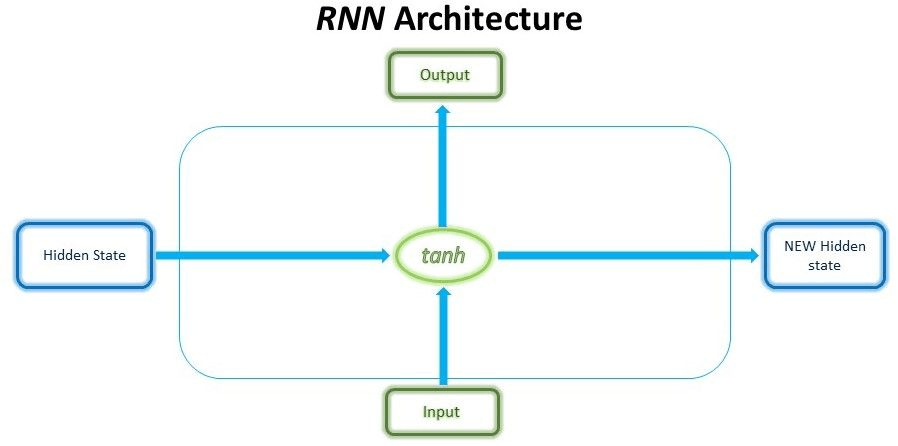
Here, we can observe that the data given at the input is passed through the tanh state, which is the activation step that will produce the new hidden state and the output. Whereas the internal architecture of the LSTM is somewhat complex at each time step in the LSTM internal architecture, we need to pass the information to each step in 3 different ways, the first data is the short-term memory which is collected from the previous cell, and the next information is current input data.
Finally, we need to pass the long-term memory. Short-term memory is generally referred to as the hidden state, while long-term memory is generally referred to as the cell state. With the help of the gates, the cell will regulate the information that must be passed and discarded before passing the long-term and short-term memory information to each cell in the Long Short-Term Memory network architecture.
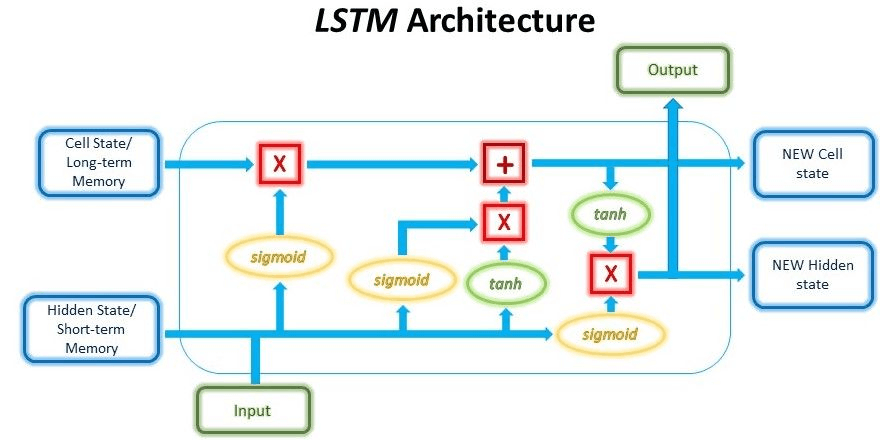
The working of each cell in the LSTM is very similar to the working of the water filter. The water filter first collects the water, and then it will filter it and pass the purified water to the output. Similarly, each gate in the LSTM will collect the data and filter the data and removes the irrelevant information, and allows only the required data in the final output. Each cell in the LSTM architecture will be trained first to filter which data is useful and which is not.
Input Gate:
The input gate will decide which new information must be stored in the long-term memory. This gate will work only with the information based on the current state and the short-term memory obtained from the previous time step. Therefore we can say that the input gate will filter out the information which will be used and the information which is not helpful.
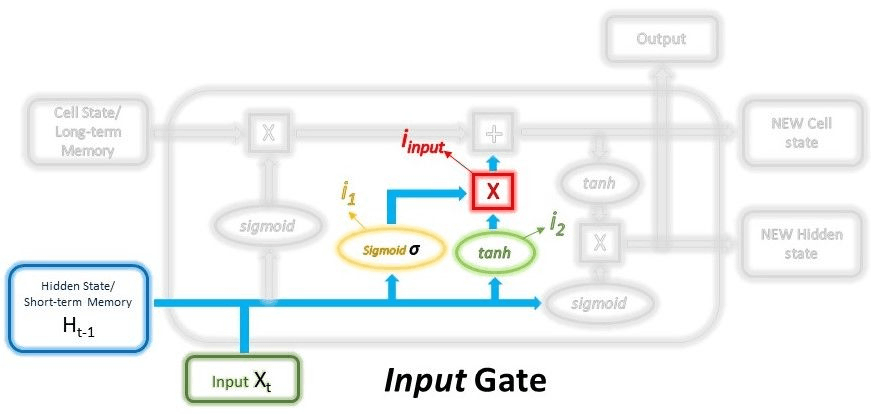
The input layer consists of generally two steps, the first step will act as the filter, which will select the required information, and this step will select which data should also be neglected. To this layer, we will pass the short-term memory and also need to pass the current memory into the sigmoid function. This sigmoid function filters the required and the irrelevant information with the help of 0 and 1.
Here 0 will indicate that the data is unimportant, and 1 indicates that the data is important and must be passed to the next state. Each layer in the input is trained with the help of the back-propagation, and the weights in the sigmoid function are trained in such a way that the model will be trained in such a way that only the relevant data is passed, and the less important features are discarded.
input_1 = &(Wi1.( H t-1, Xt) + biasi1)
The second input stage will take the short-term memory and the current input to the second layer and then pass through the activation function, which will regulate the process. Generally, the tanh function will be used as an activation layer.
input_2 = tanh(Wi2.( H t-1, Xt) + biasi2)
Then finally, these two inputs are added together, and the outcome will represent the final data that must be stored as long-term memory and then used as the output.
i_final = input_1 * input_2
Forget Gate:
The forget gate will act as the deciding gate; it will decide which information should be kept and which must be discarded in the long-term memory. This operation can be performed by multiplying the incoming long-term memory with the forget vector, which has been created with the help of the current input and the incoming short-term memory.
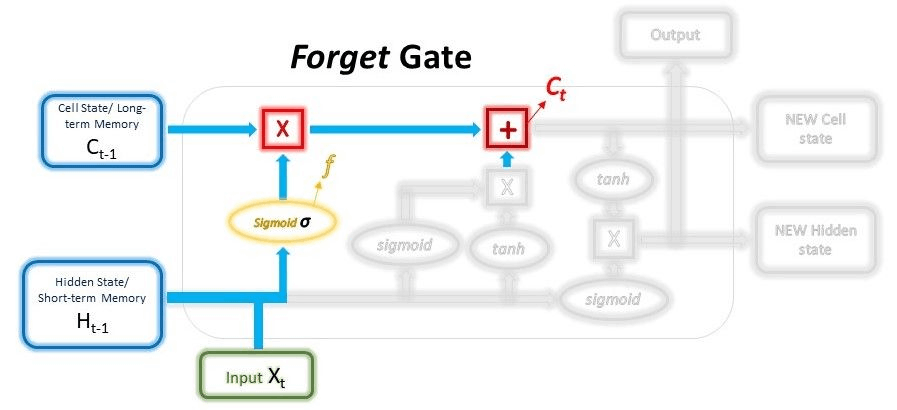
The forget gate also contains the first layer as the selective filter layer same as in the input layer. To generate the forget vector, the short-term memory and the current input must be passed through the sigmoid function, but here we need to pass the inputs with different weights. This forgets memory also contains the 0s and 1s; if the value is marked as 0, we must neglect the irrelevant data from the long-term memory. If the value is 1, we need to consider the relevant data from long-term memory.
forget_1 = &(Wforget.( H t-1, Xt) + bias_forget)
The output, which is obtained from the Input gate and the Forget gate, will undergo the point-wise addition, and we will obtain the new version of the long-term memory, and then it is passed into the next cell. This new version of the forget vector is passed into the output gate's final gate.
Ctot = Ctot-1* f +i_final
Output Gate:
The output gate will collect the previous short-term memory, and the new version of the long-term memory is also collected; this data will be used to create the new short-term memory it is also known as the hidden state, which is passed to the cell which is present in the next time steep. We can also obtain the output of the current step using the hidden state.
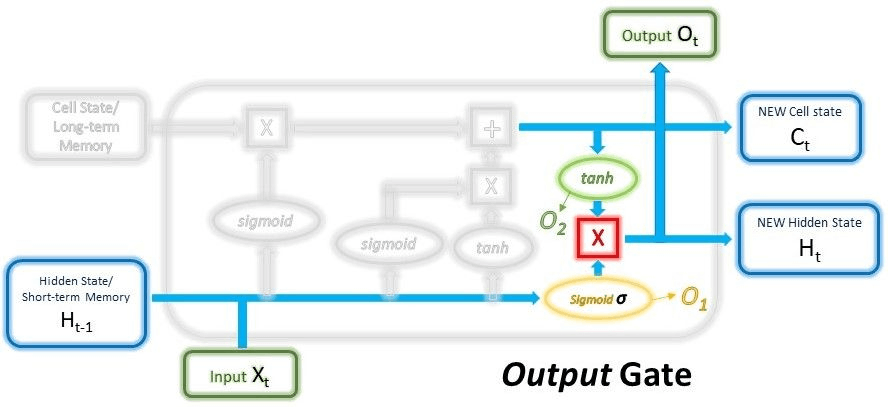
To the output gate, first, we need to pass the short-term memory along with the current input with the different weights; it will filter the data with the help of 0s and 1s; this is the final filtration process. Then this new version of the long-term memory must be passed through the tanh, which acts as the activation function. Then finally, these two output data must be multiplied to get the new short-term memory.
O_1 = &(Wout_1.( H t-1, Xt) + biasout_1)
O_2 = tanh(Wout_2.Ctot+ biasout_2)
Ht,Ot = O_1*O_2
These short-term and long-term memory produced is carried over to the next cell, and the process is then repeated. The output from each state is obtained in the form of short-term memory, also known as the hidden state.
Implementation of Code to Run the LSTM
With the help of the PyTorch library we can implement the code to run the LSTM for this first we need to check whether each and every layer in the LSTM is working properly or not. For this we need to implement the following commands:
#importing the libraries
import torch
import torch.nn as nn
Here first, we need to initiate the LSTM layer and to perform this operation we need to provide the required arguments. Let us consider an example in which we are going to define the input dimensions, hidden dimensions and the total number of layers in the operation.
- Input dimensions: We need to provide the size of the input network at each step while we are inputting the data.
Example: If the input of the data is 6 the input will look like [2,3,6,8,9,12]
- Hidden dimensions: This will represent the total size of the hidden state and also represent the state of cell at each time step.
Example: If the hidden state size and the cell state is 4 it will have a shape [9.4, 6, 3]
- Number of layers: This will provide the information about the total number of LSTM layers are stacked one above the other.
Code:
input = 6
hidden = 3
total_layers = 1
lstm = nn.LSTM(input, hidden, total_layers, batch_start = True)
Now let us create a data to find how the layer will take the input. Let us consider the input data dimension ids 4 and we shall create a tensor of the shape (2,3,4) this generally represents the( batch size, length of sequence , dimension of the input)
For the first cell creation generally, we need to initialize the hidden state and the cell state for the LSTM layer. The created hidden state and the cell state which is created is stored inside a tuple with the format(state_ hidden , state_cell).
Code:
batch_size = 1
len_seq = 1
input = torch.randn(batch_size, len_seq, in_dim)
state_hidden = torch.randn(t_layers, batch_size, dim_hidden)
state_cell = torch.rndn(t_layers, batch_size, dim_hidden)
hidden = ( state_hidden, state_cell)
Output:
input_shape : (1, 1, 6)
hidden_shape : ((1,1,3), (1,1,3))
Now we need to provide the data into the hidden states and the input states and after giving the input and we shall observe the input we have provided:
Code:
Output, hidden = lstm_layer(input, hidden)
print(“output values:”, output.shape)
print(“hidden values:”, hidden)
Output:
Output values: torch.size(1,1,3)
Hidden values: (tensor([[[ 0.1453, 0.6573, -0.2367]]], grad_fun =<StackBackward>))
Here we have observed that how the data has been given as the input to the input state and hidden state at each time step. Generally in LSTM we will process the larger data at once. The LSTM (Long Short-Term Memory network) layer can also take the sequences in the variable length and we can produce the output at each time step. Here let us try the LSTM layers by changing the sequence length:
Code:
len_seq = 2
input = torch.randn(batch_size, len_size, dim_size)
output, hidden = lstm_layer(input, hidden)
print(output.shape)
Output:
torch.size([1,2,3])
Here we can observe the second dimension in the LSTM layer is set as 2, it will indicate that the total number of outputs in the LSTM are 2. This will be taken as the length of the input sequence. Here we need to consider the input at each time step same as the text generation, the output of the each time step can be easily received from the 2nd dimension and then it will be provided to the next layer with is present in the stack layers of LSTM (Long Short-Term Memory network).
Conclusion:
The LSTM library is the Long Short-Term Memory network; this network will predict future values by considering the previous memory. This LSTM library is based on the time model; it will predict the change of the dataset with time. The LSTM will perform the operations on the dataset with the help of the recurrent neural network method; it is a technique in which the nodes will be connected cyclically; any change in the node will affect the operation of the next node with the help of the pytorch we can analyze our working of the LSTM based on the inputs we have provided. Generally, the pytorch is used to analyze the future data based on the data which is collected in the past.