Outlier Analysis in Data Mining
What are Outliers?
Outliers are an integral part of data analysis. An outlier can be defined as observation point that lies in a distance from other observations.
An outlier is important as it specifies an error in the experiment. Outliers are extensively used in various areas such as detecting frauds, introducing potential new trends in the market and others.
Usually, outliers are confused with noise. However, outliers are different from noise data in the following sense:
- Noise is a random error, but outlier is an observation point that is situated away from different observations.
- Noise should be removed for better outlier detection.

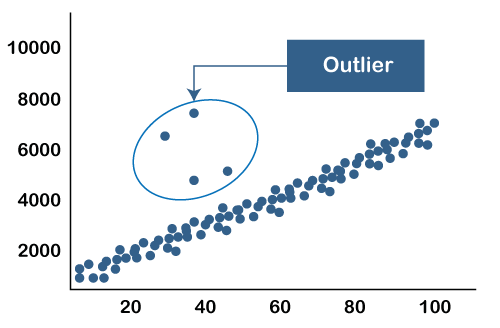
Given below are two graphical examples of outliers:
As shown in this graph, the outliers are points that lie outside the entire pattern of distribution.
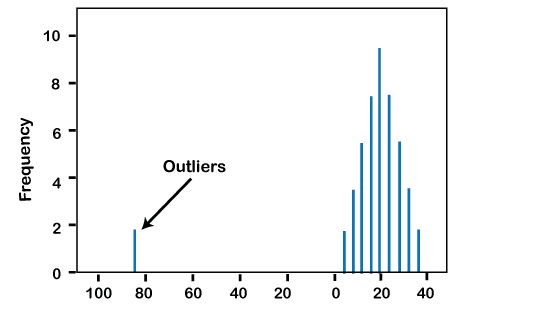
Another illustration of outliers can be seen in the histogram given below. In this, one point lies far away from the remaining, this point is an outlier.
Various causes of outliers in Data Mining
There are various causes of outliers in Data Mining. Some of these causes are given below:
- It is used in identifying the frauds in banking sectors such as credit card hacking or any similar frauds.
- It is used in observing the change in trends of buying patterns of a customer.
- It is used in identifying the typing errors and reporting errors made by humans.
- It is used in discovering the errors or faults in machines or systems.
What is the need of handling the outliers in Data Mining?
There are various reasons to handle the outliers in Data Mining. Some of those reasons are listed below:
- Outliers affect the results of the databases.
- Outliers often give useful or beneficial results and conclusions due to which various trends or patterns can be recorded.
- Outliers can be beneficial in research department also. They can be extremely useful in some discovery.
- Outliers are the key branches of data mining.
Applications of Outlier Detection in Data Mining
In Data Mining, Outlier Detection is extensively used. It is used to obtain patterns or trends in data mining. The applications of Outlier Detection in Data Mining are given below:
- Fraud Detection
- Telecom Fraud Detection
- Intrusion Detection in Cyber Security
- Medical Analysis
- Environment Monitoring such as Cyclone, Tsunami, Floods, Drought and so on
- Noticing unforeseen entries in Databases
What is Outlier Analysis?
Outlier Analysis can be defined as the process in which abnormal or non-typical observations in a data set is identified.
Outlier Analysis can also be called “Outlier Mining”.
The outliers in Outlier Detection have a particular concern. These concerns are usually shown in fraud detection and intrusion detection. In fraud detection, the outliers show the fraudulent activity. Therefore, outlier detection and analysis are very beneficial part of data mining tasks. This process is known as “Outlier Mining” or “Outlier Analysis”.

Different approaches in Outlier Detection
There are majorly three approaches observed in outlier detection. Those approaches are given below:
- The Statistical Approach
- The Distance Based Approach
- The Deviation Based Approach
Outlier Detection techniques
There are four major outlier detection techniques:
- Numeric
- Z-Score
- DBSCAN
- Isolation forest
Numeric:
This is the simplest method in a single dimensional feature space. In this method, the outliers are calculated with the help of IQR (InterQuartile Range) approach. It is also nonparametric.
Z-Score:
Z-score is a parametric outlier detection method in a single or low dimensional feature space. In Z-score technique, it is assumed that there is a Gaussian distribution of the data. Zi is calculated using the formula given below:
Zi = (xi - µ)/ ?
DBSCAN:
This Outlier Detection technique is based on the DBSCAN clustering method. DBSCAN is a nonparametric, density-based outlier detection method in one or more than one dimensional feature space. In this, all the data points are described as Core Points, Border Points or Noise Points.
Isolation Forest:
Isolation Forest is a nonparametric approach that is mainly designed for huge sets of data in a one or more than one dimensional feature space. In this approach, an essential concept is isolation numbers which can be defined as the number of splits required to isolate a data point.