Data Mining Tasks
Data Mining Tasks
Data Mining can be defined as the process of extracting important or relevant information from a set of raw data.
In data mining, tasks can be categorized into two kinds:
- Predictive
- Descriptive
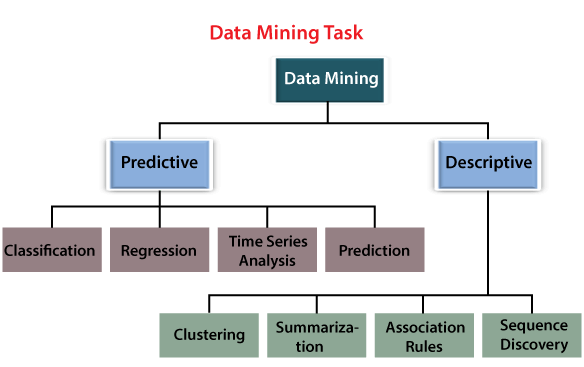
Predictive:
With the help of this approach, the user is able to make predictions about the values of data used in various databases with the help of the results that were already known from either of some different data or on the basis of historical data. Predictive can be further characterized into four other parts which are listed below:
- Classification
- Regression
- Time Series Analysis
- Prediction
Classification: It is basically responsible for discovering the function that classifies a data item into one of those several pre- defined classes. This can be further understood like this:
Say, there is given a collection of records and each record consists of attributes. Here, one of the attributes is the class.
For example, pattern recognition: Pattern recognition can be defined as the process of recognizing patterns with the help of using the algorithms in machine learning. In other words, Pattern recognition can also be defined as the process of classification of data on the basis of the knowledge that was already obtained or collected. This classification also occurs on the basis of analytical information that was extracted from patterns or their representation. One of the important parts of the pattern recognition is that it has many applications in real life.
Regression: Regression is a datamining function that is used to predict a number. For an instance, a regression model can be used to predict the value of a certain antique item on the basis of its look, how many additions or deletions were done to it, condition it was kept in, and the other factors. Generally, a regression task starts with a set of data in which the target values are familiar or studied.
The regression function can be further divided into two types:
The first one is linear regression and the second is logistic regression. These are two types of regression analysis techniques that are used to solve the regression problem with the help of using machine learning.
These two can be considered as the most prominent techniques of regression.
Time Series Analysis: A time series can be defined as a series or course of data points that were taken down at different points of time. This was usually taken down in regular time intervals such as seconds, hours, days, months, years and so on.
It is well known that different organizations collect a large amount of data every single day – that data could be in the form of sale figures, revenue collected, traffic observed, or the operating costs. In addition to that, the time series data mining can also be used to generate important or relevant information for long – term decisions affecting the organization and business. However, this technique is often not well used in most of these organizations.
Prediction: Prediction is a data mining technique that can be used to extract a model and represent the data classes in order to predict future data trends. Prediction can be defined as the output of an algorithm after it has been instructed to operate on a historical set of data and then it is applied to new data. For example, forecasting the weather is the most popular example of data mining’s prediction. In other words, it can also be defined as forecast or a prophecy. Another example of a prediction can be a psychic telling a person his/her future.
Descriptive:
The second type of data mining tasks is Descriptive tasks. This type includes the following functions:
- Association Rules,
- Clustering,
- Summarization,
- And Sequence Discovery
Association Rules:
In data mining, association rules can be used to uncover the association or the connection among various different set of items. Association can also be used to obtain the relationships between different objects.
The association analysis is a technique that is commonly used for the purpose of commodity management, advertising, catalog design, direct marketing and others.
With the help of this rule, a shopkeeper in a grocery store can find the products that are normally bought together by the customers. In addition to that, it can also be found which type of customers acknowledge the promotions of the same kind of products.
There are many examples of association rules in data mining such as scanning the item barcodes by point-of-sale systems. In this methodology, machine learning models can be used to find the co – occurrence in this data to determine which of the products are most likely to be purchased together by which customers. This way, the shopkeepers can take advantage of this and perform sales strategy in accordance to that.
Clustering:
In data mining, the process of clustering can be used to obtain the data objects that have some similarities. Those similarities can be manifested on the basis of different factors such as the purchasing behavior, responsiveness to certain actions, geographical locations and so on. By grouping this information, it will be very helpful to understand the customers better and consequently give better services to the customers.
Summarization:
Summarization can be defined as the process of generalization of data. In this process, a set of relevant and important data is summarized which is then resulted in a smaller set of data that gives gathered information of the data. This summarized information can be useful for sales or customer relationship.
Sequence Discovery:
Sequence discovery or sequential pattern mining, is a data mining technique that is used to find relevant and important patterns in sequential data. This mining program assesses certain criteria which are the frequency of occurrence, duration, or values in a set of sequences in order to find concealed or hidden patterns.