KDD in Data Mining
What is Data Mining and why is it needed?
Data Mining can be defined as the process of extraction of useful and relevant information from a set of raw data.
Data Mining is a very important process because it is a well – known fact that the capacity of the information or data is increasing day by day. For that, it needs to be processed by the help of which the data can be handled easily. Data Mining process can handle business transactions, scientific data, sensor data, Pictures, videos, and so much. In addition to that, it is also capable of extracting the information available and automatically obtaining a report or summary of data for better decision – making. Therefore, data mining process is considered as a very essential and useful process.
What is KDD and how is it helpful in Data Mining?
KDD is an acronym for Knowledge Discovery in Database. It can be defined as a procedure of finding, transforming, and refining meaningful and relevant data and patterns or trends from a set of raw data so as to utilize it in different domains or applications.
In order words, KDD can be defined as the process of discovering and explaining patterns from data that consists of the repeated application of some specific steps.
In data mining, KDD is considered as a statistical approach to form a model of the data from a given database so as to extract useful, relevant and related knowledge.
Data mining is the backbone of process of knowledge discovery in database and therefore, it is very important or crucial part of the entire process.
In addition to that, it also makes use of different algorithms that are self – learning in nature to conclude helpful patterns or trends from the data that was processed. In the process, many iterations take place in between the several steps in accordance to the requirement of the algorithms and pattern interpretations.
Steps included in KDD process:
In KDD process, there are a number of steps that are typically observed.Those steps are listed below:
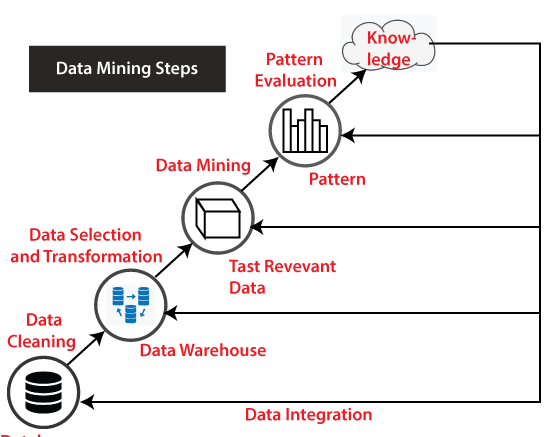
Data Integration:
The first step involved in this process is that the data is gathered and integrated from the different sources such as several databases. Therefore, the process of Data integration can be defined as the process of merging heterogeneous data from several different sources in a common source which is called Data Warehouse.
Data Selection:
The next step is to select the data. After the process of data integration, there is a lot of data gathered. That data is then selected and separated into relevant sets on the basis of quality, significance, accessibility, and convenience. These criteria are very significant for the process of data mining because of the fact that these criteria are responsible for creating the base for it. Moreover, it will also affect the data models that are formed.
Data Cleaning:
In the process of data cleaning, there are several tactics involved such as finding the missing data, removing noise, removing redundant and low – quality data from the data set. These tactics are applied so as to improve the reliability of the data and its effectiveness. In data cleaning, some specific algorithms are also used for finding and deleting the irrelevant or unnecessary data.
Data Transformation:
In this step, the data is put together so that it can be given to the various data mining algorithms. Data Transformation can be defined as the process of transforming data into suitable form that is required by further mining procedure.
The process of Data Transformation has two steps, which are given below:
- Data Mapping: In this step, the elements are assigned from source base to destination so as to capture the transformations.
- Code generation: In this step, the actual transformation program is made.
Data Mining:
The process of data mining is considered as the main process or backbone process of the entire knowledge discovery in database. In this process, the algorithms are used to extract relevant and useful patterns from the transformed data which consequently is helpful in the prediction models.
The analytical tools are used for the purpose of finding various patterns and trends from a set of data. In simple words, intelligent methods such as artificial intelligence, advanced numerical and statistical methods and specialized algorithms are applied on the data so as to extract different patterns and trends.
So, the process of data mining is used to find the important patterns. Therefore, clustering and association analysis are two of the different techniques present in the process.
Pattern Evaluation:
In pattern evaluation, the methods such as visualization, transformation, removing redundant patterns from the patterns that were generated are used.
When the trend and patterns from the previous steps are obtained then these trends and patterns are needed to be represented and for that, graphs such as pie chart, different type of bar graphs, histogram, time plots and so on are used. These graphical visualizations make it easier for the users to study and understand the impact of the data.
Knowledge Representation:
The last steps involved in knowledge discovery in database is representation of knowledge. This step demands the ‘knowledge’ extracted from the previous steps to be applied to a certain application or domain in a visualized format which may be in the form of tables, reports, and so on. This step is essential because it will guide the overall decision – making process for that certain application.
Conclusion:
Data is generated from various different sources of different types and in different formats, such as transactions, revenue, biometrics, scientific, pictures, videos, text and so on. So, with this large amount of information being exchanged every second, a technique that can be used to extract the relevant and important information from those large sets of data and consequently provide authentic and productive data so that it can be used for taking better decision – making seems very much needed and this is where KDD is so helpful.