Artificial Neural Network Tutorial
Artificial Neural Network or Neural Network was modeled after the human brain. Human has a mind to think and to perform the task in a particular condition, but how can the machine do that thing? For this purpose, the artificial brain was designed, which is called a neural network. Similar to the human brain has neurons for passing information; the same way the neural network has nodes to perform that task. Nodes are mathematical functions.
A neural network is based on the structure and functions of biological neural networks. A neural network itself changes or learn based on input and output. The information that flows through the network affects the structure of the artificial neural network because of its learning and improving the property.
Dr. Robert Hecht-Nielsen explains the neural network as:
"The computing system made up of several simple, highly interconnected processing elements, which process information by their dynamic state response to external inputs."
Components of an Artificial Neural Network
Neurons
Neurons are similar to the biological neurons. Neurons are nothing but the activation function. Artificial neurons or Activation function has a "switch on" characteristic when it performs the classification task.
We can say when the input is higher than a certain value; the output should change state, i.e., 0 to 1, -1 to 1, etc. The sigmoid function is commonly used activation function in Artificial Neural Network.
F (Z) = 1/1+EXP (-Z)
Nodes
The biological neuron is connected in hierarchical networks, with the output of some neurons being the input to others. These networks are represented as a connected layer of nodes. Each node carries multiple weighted inputs and applies to the neuron to the summation of these inputs and generates an output.
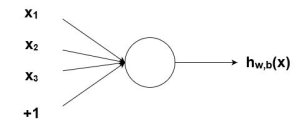
The Bias
In the neural network, we predict the output (y) based on the given input (x). We create a model, i.e. (MX + c), which help us to predict the output. When we train the model, it finds the appropriate value of the constants m and c itself.
The constant c is the bias. Bias helps a model in such a manner that it can fit best for the given data. We can say bias gives freedom to perform best.
Algorithm
Algorithms are required in the neural network. Biological neurons have self-understanding and working capability, but how an artificial neuron will work in the same way? For this, it is necessary to train our artificial neural network. For this purpose, there are lots of algorithms used. Each algorithm has a different way of working.
There are five algorithms which are used in training of our ANN
- Gradient Descent
- Newton’s Method
- Conjugate Gradient
- Quasi Newton’s
- Levenberg Marquardt
Types of Artificial Neural Network
Neural Network works similarly as the human nervous system works. There are several types of neural network. These networks implementation are based on the set of parameter and mathematical operation that is required for determining the output.
1. Feedforward Neural Network (Artificial Neuron)
FNN is the purest form of ANN in which input and data travel in only one direction. Data flows only in a forward direction; that's why it is known as the Feedforward Neural Network. The data passes through input nodes and exit from the output nodes. The nodes are not connected cyclically. It doesn't need to have a hidden layer. In FNN, it doesn't require multiple layers. It may have a single layer also.
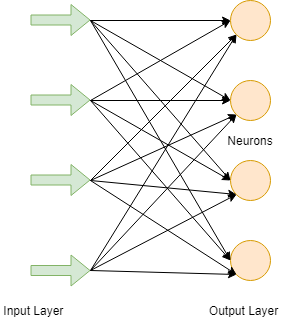
It has a front propagate wave that is achieved by using a classifying activation function. All other types of neural network use backpropagation, but FNN can't. In FNN, the sum of the product's input and weight are calculated, and then it is fed to the output. Technologies such as face recognition and computer vision are used FNN.
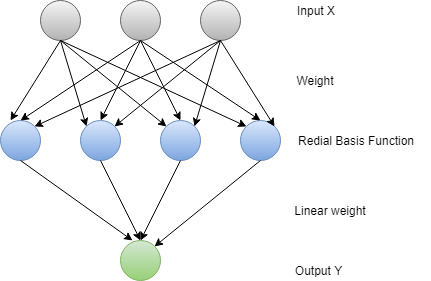
2. Redial basis function Neural Network
RBFNN find the distance of a point to the center and considered it to work smoothly. There are two layers in the RBF Neural Network. In the inner layer, the features are combined with the radial basis function. Features provide an output that is used in consideration. Other measures can also be used rather than Euclidean.
Redial Basis Function
- We define a receptor t.
- Confronted maps are drawn around the receptor.
- For RBF Gaussian Functions are generally used. So we can define the radial distance r=||X-t||.
Redial Function=?(r) = exp (- r²/2?²), where ? > 0
The Neural Network is used in power restoration system. In the present era power system have increased in size and complexity. It's both factors increases the risk of major power outages. Power needs to be restored as quickly and reliably as possible after a blackout.
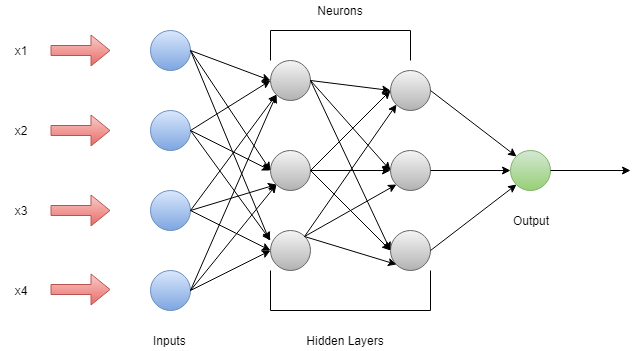
3. Multilayer Perceptron
A Multilayer Perceptron has three or more layer. The data that cannot be separated linearly is classified with the help of this network. This network is a fully connected network that means every single node is connected with all other nodes that are in the next layer. A Nonlinear Activation Function is used in Multilayer Perceptron. It’s input and output layer nodes are connected as a directed graph. It is a deep learning method so, for training the network it uses back propagation. It is extensively applied in speech recognition and machine translation technologies.
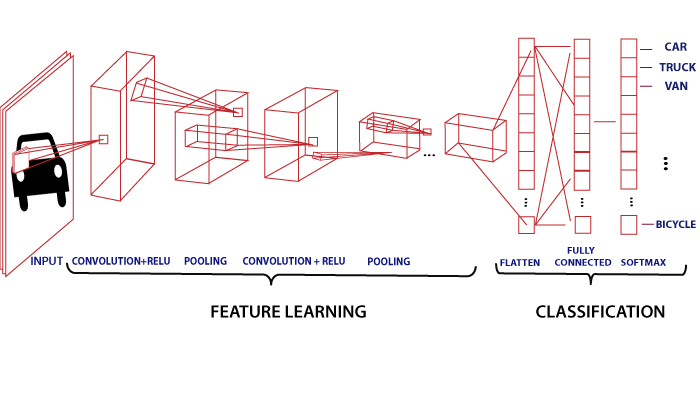
4. Convolution Neural Network
In image classification and image recognition, convolution Neural Network plays a vital role, or we can say it is the main category of CNN. Face recognition; object detection, etc., are some areas where CNN are widely used. It is similar to FNN, learn-able weights and biases are available in neurons.
CNN takes an image as input that is classified and process under a certain category such as dog, cat, lion, tiger, etc. As we know, the computer sees an image as an array of pixel and depends on the resolution of the picture. Based on image resolution, it will see h * w * d, where h= height w= width and d= dimension. For example, An RGB image is 6 * 6 * 3 array of the matrix, and the grayscale image is 4 * 4 * 3 array of the matrix.
In CNN, each input image will pass through a sequence of convolution layers along with pooling, fully connected layers, filters (Also known as kernels). It can apply Soft-max function to classify an object with probabilistic values 0 and 1.
5. Recurrent Neural Network
Recurrent Neural Network is based on prediction. In this neural network, the output of a particular layer is saved and fed back to the input. It will help to predict the outcome of the layer. In Recurrent Neural Network, the first layer is formed in the same way as FNN's layer, and in the subsequent layer, the recurrent neural network process begins.
All the inputs and outputs are independent of each other. In some cases, RNN is required to predict the next word of the sentence, and it will depend on the previous word of the sentence. RNN is popular for its main and most important feature, i.e., Hidden State. Hidden State remembers the information about a sequence.
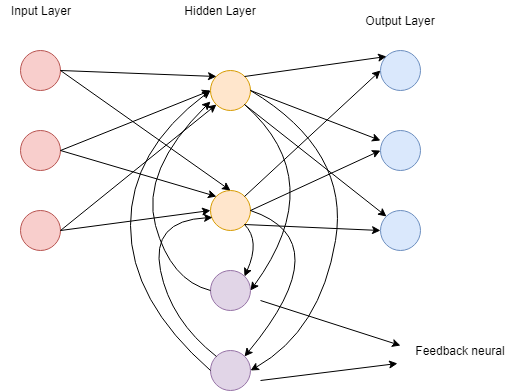
RNN has a memory to store the result after calculation. RNN uses the same parameters on each input to perform the same task on all the hidden layers or inputs to produce the output. Unlike other neural networks, RNN parameter complexity is less.
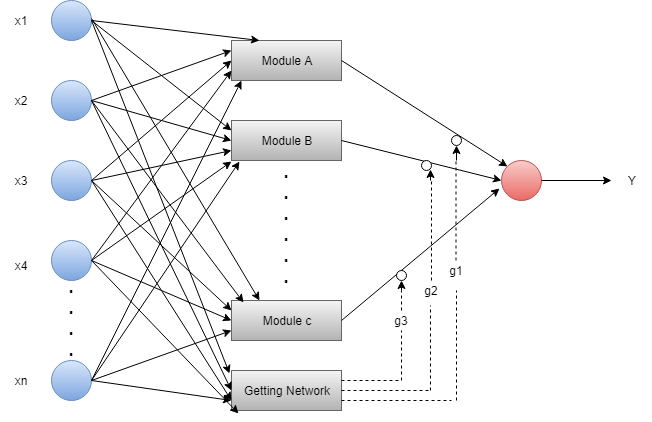
6. Modular Neural Network
In Modular Neural Network, several different networks are functionally independent. In MNN the task is divided into sub-task and performed by several networks. During the computational process, networks don't communicate directly with each other.
All the networks work independently towards achieving the output. Combined networks are more powerful than flat and unrestricted. Intermediary takes the output of each network; process them to produce the final output.
Training of a Neural Network
Training Strategy is the process which is used to carry out the learning process. For obtaining minimum possible loss, we apply a training strategy to the neural network. It is done when we search for a set of parameters that fit the neural network to the dataset.
There are two different concepts in training of a neural network.
- Loss Index
- Optimization Algorithms
Loss Index
Loss Index is one of the important concepts which plays a vital role in the training of a neural network. Loss index defines a task which is required to do by a neural network. A neural network is required to learn the measure of the quality of the representation. The loss index provides this measure.
We have to choose two different terms, i.e., error term and regularization_term, to set-up a loss index.
Loss_Index=Error_term+Regularization_term
- Error_term
In the loss expression error is the most important term which measures how a neural network fits the training instances in the dataset. There are several errors which are used in the neural network.
- Mean squared error
Its main task is to calculate the average squared error between targets in the dataset and the output from the neural network.

- Normalized Squared Error
NSE main task is to divide the squared error between the targets in the dataset and the output from the neural network using the normalization coefficient. The neural network predicts the data 'on the mean' only if, NSE has a value of unity. If the value is zero, that indicates a perfect prediction of the data.
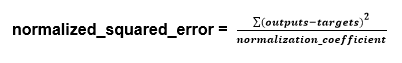
- Weighted Squared Error
In binary classification application, WSE is used with unbalance targets. Its main task is to give different weight to positive and negative instances when the numbers of positives and negatives are very different.
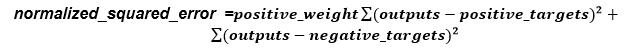
- Minkowski Error
Over the training instances, the sum of the difference between targets elevated to an exponent (vary between 1 and 2) the output. The exponent is called as the Minkowski parameter, and the default value of the exponent is 5.
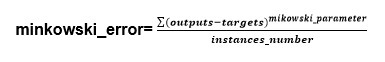
- Regularization Term
After doing small changes in the input variables, it leads to small changes in the output; the solution is said to be regular.
- L1 Regularization
This method contains the sum of the absolute values of all the parameters in the neural network.
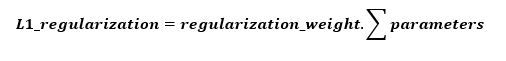
- L2 Regularization
This method contains the squared sum of all the parameters in the neural network.
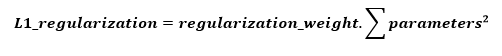
Loss function in the network depends on the Adaptative parameters. These parameters group into a single n-dimensional weight vector w.
Let see a diagram that describes the loss function f (w).
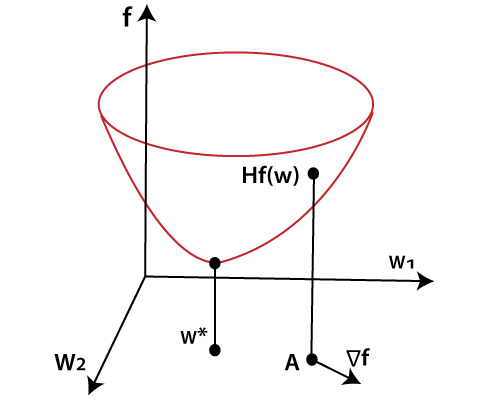
In the above diagram, at the point, w* minimum loss function occurs. We can find the first and second derivatives of the loss function at any point A. The elements of the first derivatives which are grouped in the gradient vector can be written as
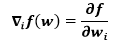
For i= 0, 1, n.
Similarly, the elements of the second derivatives which are grouped in the Hessian matrix can be written as
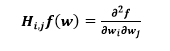
For i, j= 0, 1…..
Optimization Algorithms
The optimization algorithm is the procedure which is used to carry out the learning process in a neural network. It is also known as the optimizer. There are different types of the optimization algorithm. Each algorithm has different characteristics and performance in terms of speed, precision, and memory requirements.
Gradient Descent
Gradient descent algorithm is also known as the steepest descent algorithm. It is the simplest algorithm which requires information from the gradient vector. GD algorithm is a first-order method.
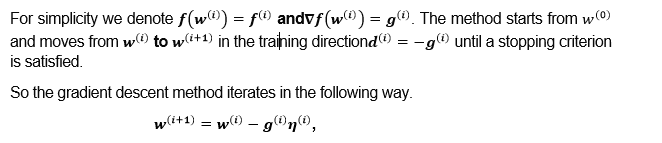
For i= 0, 1...
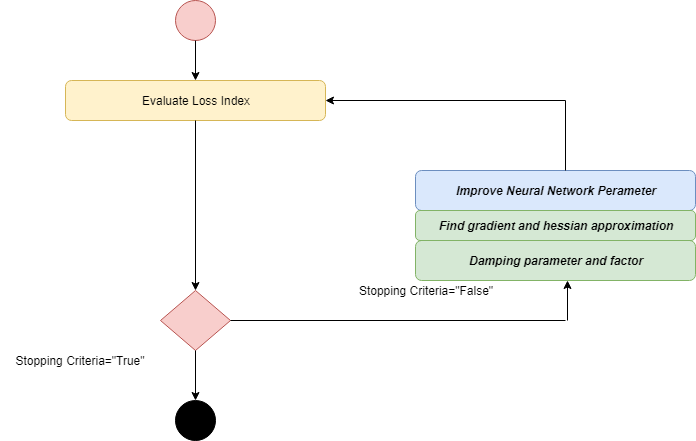
Activity diagram of the training process is given below.
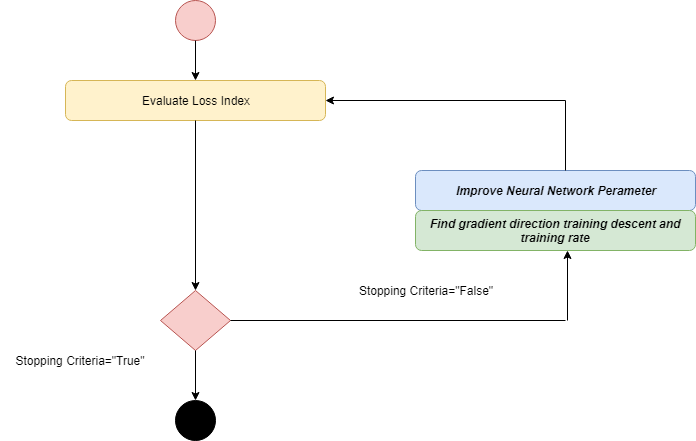
GD algorithm is recommended when we have a big neural network along with thousands of parameters. The reason behind this is GD stores the gradient vector, not a Hessian matrix.
Newton’s Method
Newton's method is a second-order algorithm. It makes use of the Hessian matrix. Its main task is to find better training directions by using the second derivatives of the loss function.
Newton's method iterates as follows.
w(i+1) = w(i) - H(i)-1.g(i)
For i = 0, 1.....
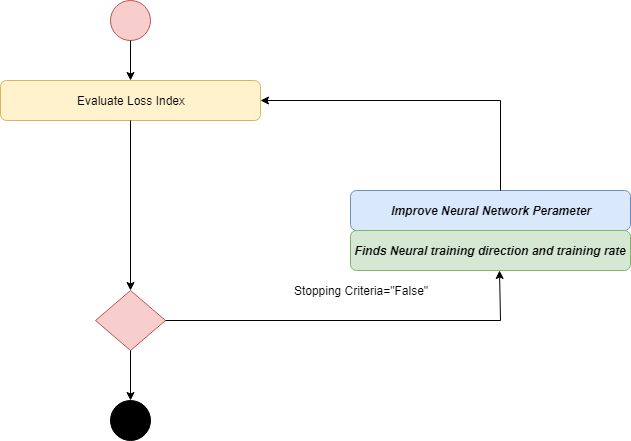
Here, H(i)-1.g(i) is known as Newton's step. The change for parameters may move toward a maximum rather than a minimum. Below is the diagram of the training of a neural network with Newton's method. The improvement of the parameter is made by obtaining the training direction and a suitable training rate.
Conjugate gradient
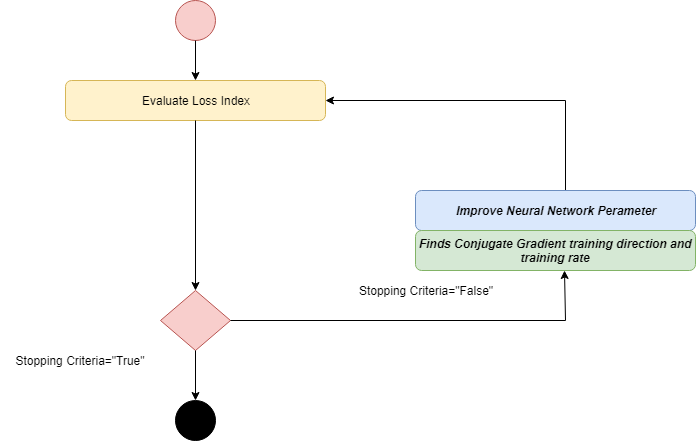
Conjugate gradient works in between gradient descent and Newton’s method. Conjugate gradient avoids the information requirements associated with evaluation, inversion of the Hessian matrix, and storage as required by Newton's method.
In the CG algorithm, searching is done in a conjugate direction, which gives faster convergence rather than gradient descent direction. The training is done in a conjugate direction in concern with the Hessian matrix. The improvement of the parameter is made by computing the conjugate training direction and then suitable training rate in that direction.
Quasi-Newton Method
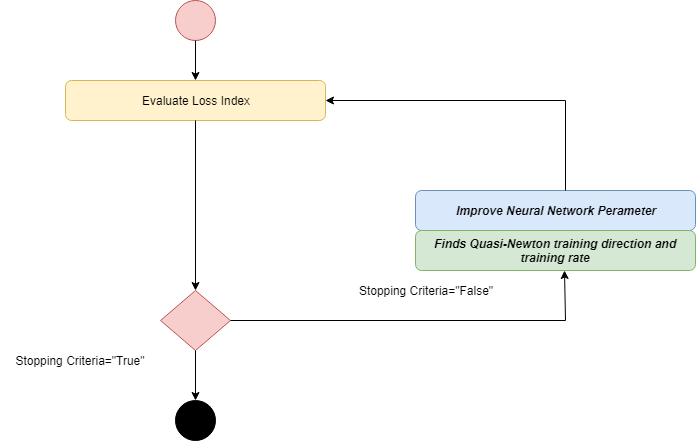
Applications of Newton's method are very expensive in terms of computation. To evaluate the Hessian matrix, it requires many operations to do. For resolving this drawback, Quasi-Newton Method was developed.
It is also known as a variable matrix method. At each iteration of an algorithm, it builds up an approximation to the inverse hessian rather than calculating the hessian directly. Information on the first derivative of the loss function is used to compute approximation.
The improvement of the parameter is made by obtaining a Quasi-Newton training direction and then finds a satisfactory training rate.
Levenberg Marquardt
Levenberg Marquardt is also known as a damped least-squares method. This algorithm is designed to work with loss function specifically. This algorithm does not compute the Hessian matrix. It works with the Jacobian matrix and the gradient vector.
In Levenberg Marquardt, the First step is to find the loss, the gradient, and the Hessian approximation, and then the dumpling parameter is adjusted.
Advantages and Disadvantages of Artificial Neural Network
Advantages of ANN
- It stores the information on the entire network rather than the database.
- After the training of ANN, the data may give the result even with incomplete information.
- Even if one or more cell of ANN is corrupted, the output still gets generated.
- ANN has distributed memory that helps to generate the desired output.
- ANN can make a machine learnable.
- ANN has a parallel processing capability, which means it can perform more than one task at the same time.
Disadvantages of ANN
- It requires a processor with parallel processing power according to their structure.
- Unexplained behavior of the network is the main problem of ANN. ANN doesn’t give a clue when it produces a probing solution.
- There are no specific rules provided to determine the structure of ANN.
- There is no information about the duration of the network.
- It’s too typical to show the problem to the network.
Conclusion
In this tutorial, we explained only the basic concepts of the Neural Network. In Neural Network, there are many more techniques and algorithms other than backpropagation. Neural Network works well in image processing and classification.
Currently, on the neural network, very deep research is going on. Once you have sufficient knowledge about the basic concepts and algorithms, you may want to explore reinforced learning, Deep learning, etc.