Data Mining Tutorial
Data Mining Introduction
Generally, Mining means to extract some valuable materials from the earth, for example, coal mining, diamond mining, etc. in terms of computer science, “Data Mining” is a process of extracting useful information from the bulk of data or data warehouse.
In the case of coal or diamond mining, extraction process result is coal or diamond, but in the case of data mining the result is not a data but it is a pattern and knowledge which is gained at the end of the extraction process. Data mining is also known as Knowledge Discovery or Knowledge Extraction.
In 1989, Gregory Piatetsky-Shapiro discovered the term “Knowledge Discovery in Databases”. But the term data mining became more popular. Today Data mining and knowledge discovery are used interchangeably.
Data mining is mostly used in places where a large amount of data is stored and processed. For example, the banking system uses data mining to store huge amounts of data which is processed daily.
In Data mining, hidden patterns of data are analyzing according to the different categories into a piece of useful information. This information is assembled in an area such as data warehouses for analyzing it, and data mining algorithms are implemented. This data helps in making effective decisions which cut cost and increase revenue.
The Evolution of Database System Technology
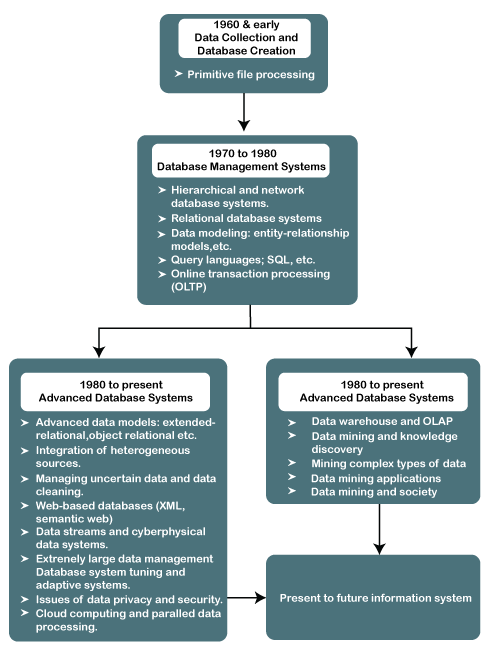
Knowledge Discovery Process (KDP)
Data Mining is also known as knowledge discovery from data, or KDD. The process of knowledge discovery is shown below:
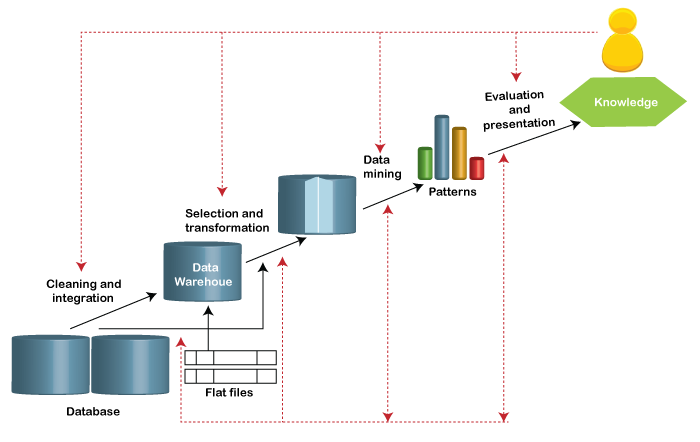
- Data cleaning: In this stage, all the noise of the data and inconsistent data are removed.
- Data integration: In this stage, multiple data from different sources are combined.
- Data selection: In this stage, data that are closely connected are analyzed and retrieved from the database.
- Data transformation: In this stage, data is transformed and make it strong by performing summary or aggregation operations.
- Data mining: It is the most important process in which intelligent methods are applied for extracting data patterns.
- Pattern evaluation: In this stage, interesting patterns which represent knowledge and are based on interestingness is identified.
- Knowledge presentation: In this stage, visualization and knowledge representation techniques are used to present knowledge to the users.
Kinds of data which can be mined
Data mining is a technique that can be applied in any kind of data, but the data should be meaningful for a target application.
Following are the types of mining application which are used for data:
1) Database Data
A database system is also known as database management system (DBMS) which is a collection of interrelated data known as a database, and also it is a set of software programs for managing and accessing the data. For defining database structures and data storage, for specifying and managing concurrent, shared, or distributed data access; and for ensuring consistency and security of the information stored despite system crashes or attempts at unauthorized access many mechanisms are provided by software programs. A relational database is the collection of tables, and each table should have a unique name, each table has a set of attributes, and it can store a large set of records or rows. Each record in a table is identified by a unique key. Data models such as entity-relationship (ER) data models are also constructed for the relational database. Entity-relationship (ER) data models represent the database as a set of entities and their relationships.
For example A relational database for AllElectronics
customer (cust ID, name, address, age, occupation, annual income, credit information, . . .)
item (item ID, brand, category, type, price, supplier, cost, . . .)
employee (empl ID, name, category, group, salary, . . .)
branch (branch ID, name, address, . . .)
purchases (trans ID, cust ID, empl ID, date, time, amount)
items sold (trans ID, item ID, qty)
works at (empl ID, branch ID)
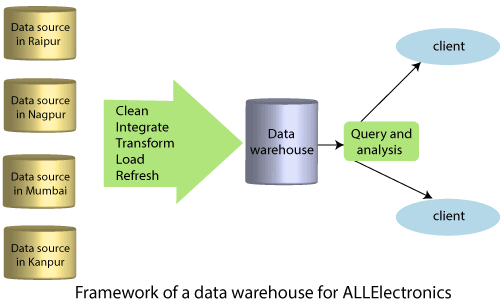
2) Data Warehouses
For example, suppose that AllElectronic is a company that has branches all over India, and each branch has its own databases. The head of the company asked to provide an analysis of the company’s sales per item of every branch for the 3rd quarter. This becomes a very difficult task because the data is present in several databases. If AllElectronic would have a data warehouse, then this task would be very easy.
A data warehouse is a place in which information is collected from multiple sources and then stored in a unified schema and residing at a single site. A data warehouse is constructed in several steps like data cleaning, data integration, data transformation, data loading, and data refreshing. The data in the data warehouse are organized in many parts. Information on Historical data such as of past 6 to 12 months is provided in summarized form.
A data warehouse is modeled by a multi-dimensional data structure known as a data cube. A data cube has attributes or set of attributes in the schema, and each cell contains the value of some aggregates such as sum or count. A data cube has a multidimensional view of data, and it allows fast access to summarized data.
3) Transactional Data
Transactional database records are captured as a transaction, for example, customer purchase, flight booking, click on the web page by a user, etc. a transaction has a unique transaction identification number and list of items that make up the transaction. A transactional database may contain additional tables that have records related to transactions.
4) Other Kinds of Data
There are many kinds of data that have versatile forms and structure and different semantic meanings. This kind of data can be seen in many applications. The following are the kinds of other types of data: time-related or sequence data, data streams, spatial data, engineering design data, hypertext and multimedia data, graph and networked data, and the web.
Technologies used for data mining
1) Statistics
In Statistics, the collection, analysis, explanation, and presentation of data are studied. Data mining has a permanent connection with statistics. A statistical model is a set of mathematical functions that describes the behavior of objects in terms of random variables and their associated probability distributions. Statistical models are used for model data and data classes. In data mining, statistical model is used for tasks like data characterization and classification. On top of the statistical model, the data mining task can be built.
2) Machine Learning
Machine learning is used to investigate how computers can learn based on the data. The main research area in machine learning is for computer programs for learning, recognizing complex patterns and to make intelligent decisions that are based on the data automatically. Machine learning is the fastest growing technology.
3) Database Systems and Data Warehouses
The database system mostly focuses on the creation, maintenance, and use of databases for the organization and the end-users. Database systems have high principles in the data models, query languages, query processing, optimization methods, data storage, indexing, and accessing methods.
4) Information Retrieval
Information retrieval is the process of searching for documents or information in documents. Documents can be in the form of text or multimedia or may reside on the web. The main difference between traditional information retrieval and database system is:
- The data which is searched is unstructured.
- Keywords are used to form queries which do not have complex structures.
The approach used for information retrieval is probabilistic models.
Applications of Data Mining
1) Marketing
The data mining technique is very useful for understanding the behavior of buyers for example how frequently customer purchase the product, total amount of all the purchases and when was the last purchase, etc. using data mining, needs of the buyers can be understand easily, can make the products and services according to the buyer’s requirement. Database marketing is a very popular application of data mining.
2) HealthCare
Data mining has improved very much in the healthcare system. Using data mining, the total number of patients can be predicted, which will help to make sure that each and every patient can receive proper care at the right time and place.
3) Education
In the field of education, educational data mining is done. It is used to address students challenges and also helps to understand how students can learn by creating a student model. The main goal of educational data mining is to predict the students future learning behavior, which will help students to get success. Students results can also be predicted by data mining.
4) Retail Industry
The retail industry has a large amount of data on sales and customer shopping history. Data mining in the retail industry helps in the behavior of the client, the pattern of customer buying, which leads to better customer service.
5) Banking
Data mining is very important in the banking sector. Banking has benefited from digital technology. Data mining is hugely used in the area of finance, credit analysis, fraudulent transactions, cash management, and also in predicting payments.
Data Mining Issue
- Mining Methodology
Researchers and scientists have developed many new data mining methodologies. This methodology involves the investigation of new kinds of knowledge, integrating methods from other disciplines, mining in multidimensional space, and the semantic ties among data objects. The mining methodologies have many issues such as data uncertainty, noise, and incompleteness, etc. following are the various aspects of mining methodology:
i) Mining various and new kinds of knowledge
Data mining covers a very wide range of data analysis and knowledge discovery tasks, from data characterization and discrimination to the association and correlation analysis, classification, regression, clustering, outlier analysis, sequence analysis, and trend and evolution analysis. This task uses the same database in many different ways and requires the development of many data mining techniques.
ii) Mining knowledge in multidimensional space
The data in multidimensional space is used for searching knowledge in large data sets. In this, searching for interesting patterns can be done using a combination of dimension at a high level of abstraction. This kind of mining is known as multidimensional data mining.
iii) Data mining—an interdisciplinary effort
By integrating new methods from multiple disciplines, the power of data mining can be enhanced.
iv) Boosting the power of discovery in a networked environment
Some of the data objects that are permanently stored as linked or in the interconnected environment, it can be in web, database relations, files, or documents. In data mining, semantic links in multiple data objects is a major advantage. Knowledge which is derived from one set of objects can be used to boost the knowledge of another set of objects.
v) Handling uncertainty, noise, or incompleteness of data
Mostly data contains noise, errors, exceptions, or is incomplete. The errors and noise cause confusion in the process of data mining which leads to erroneous patterns. Data cleaning, data preprocessing, outlier detection and removal, etc. are examples of techniques that need to be integrated with the process of data mining.
vi) Pattern evaluation and pattern- or constraint-guided mining
As we know that all the patterns generated by the data mining process are not interesting. Making a pattern interesting always varies from user to user. Therefore techniques are needed for interestingness to discover patterns bases on the subjective measures. These estimate will generate patterns which are based on the user's expectations.
2) User Interaction
In the process of data mining, the user plays a very important role.
i) Interactive mining
The process of data mining should be highly interactive. For building a flexible user interface, exploring the mining environment makes the system user-friendly. A user will 1st check the set of data, explore the data and its characteristics, estimate its potential for mining results. Attractive mining allows the user to change the method of searching dynamically.
Incorporation of background knowledge
In the knowledge discovery process, Background knowledge, constraints, rules, and information about the domain should be known. This knowledge is used for a pattern evaluation and also guides towards interesting patterns.
ii) Ad hoc data mining and data mining query languages
Flexible searching using query languages has become very important because they allow users to pose ad hoc queries. For defining ad hoc data mining tasks, high-level data mining query gives the interface user-friendly.
iii) Presentation and visualization of data mining results
How can data mining systems present the result of data mining and flexibility by which knowledge can be understood easily and directly by humans? This is a very hard process if the process of data mining is interactive. It requires expressive knowledge representation, a friendly interface, and techniques for visualization.
3) Efficiency and Scalability
Efficiency and scalability are used for comparing the data mining algorithms. Because of the amount of data continuously increases. Following are the factors which are critical:
i) Efficiency and scalability of data mining algorithms
The algorithms in data mining should be efficient and scalable in order to extract information from the huge amount of data. The time for an algorithm must be predictable and short and must be accepted by the application. For the development of new data mining algorithms, Efficiency, scalability, performance, and optimization must be the key features.
ii) Parallel, distributed, and incremental mining algorithms
The huge amount of data sets, distribution of data, computational complexity is the factors which motivate the development of parallel and distributed data mining algorithms. This algorithm divides the data into pieces. Then each piece is processed in parallel by searching patterns. These parallel processing pieces interact with each other. These patterns are then merged according to their partitioning. It creates a very high cost in the data mining process.
4) Diversity of Database Types
The huge diversity of database brings many challenges in data mining; they are as follows:
i) Handling complex types of data
Different types of application generate a huge spectrum of new data types from the structured data, for example, relational and data warehouse, semi-structured data to unstructured data, stable data to dynamic data, simple data to temporal data, etc. it is impossible for one data mining system to mine all the kinds of data.
ii) Mining dynamic, networked, and global data repositories
Many data sources are connected by the internet and other kinds of networks. The knowledge discovered by different sources is structured, semi-structured, or unstructured becomes challenging for data mining. Web mining, multisource data mining, and information network mining has become challenging in the field of data mining.
5) Data Mining and Society
How is the impact on society for data mining? How data mining preserve the privacy of individuals? These questions raise the following issues:
i) Social impacts of data mining
As data mining has become part of everyday lives, so it becomes important to study the impact of data mining on society. The improper use of data, the privacy of data, and the protection rights are the areas which are very important to be addressed.
ii) Privacy-preserving data mining
As data mining helps in scientific discovery, business management, economic recovery, and security protection, so the risk of disclosing personal information becomes very high. Research for privacy-preserving is still ongoing.
iii) Invisible data mining:
It is impossible for society to learn data mining techniques. More system needs the data mining functionalities by which people can use data mining results just by mouse clicking without having any knowledge of data mining algorithms.
Difference between Data mining and Big data
| Data Mining | Big Data |
| It is a large set of data available in structure from a predefined source. | It is a large set of data available in structured, unstructured, semi-structured non-defined data sources. |
| It is not capable of giving relations | It is capable of giving relations in the data set |
| It finds interesting patterns and knowledge from the database. | It finds interesting knowledge. |
| It has a centralized database that is based on the mining technique. | It is a distributed database in which mining techniques are used. |
Related Topics
- Data Mining Techniques
- Classification in Data Mining
- Data Mining Applications
- Data Mining Functionalities
- Clustering in Data Mining
- Data Mining Tools
- Apriori Algorithm in Data Mining
- Association Rules in Data Mining
- Data Mining Architecture
- Data Mining Process
- Data Preprocessing in Data Mining
- Decision Tree in Data Mining
- Data Cleaning in Data Mining
- Cluster Analysis in Data Mining
- Major Issues in Data Mining
- Data Mining Tasks
- Difference between Data Warehouse and Data Mining
- KDD in Data Mining
- Data Integration in Data Mining
- Data Mining Algorithms
- Data Reduction in Data Mining
- Data Transformation in Data Mining
- Regression in Data Mining
- Bayesian Belief Networks in Data Mining
- Data Mining Steps
- Outlier Analysis in Data Mining
- Prediction in Data Mining
- Spatial Data Mining
- Types of Data Mining
- Classification Techniques in Data Mining
- Neural Network in Data Mining
- OLAP in Data Mining
- Advantages of Data Mining
- Challenges of Data Mining
- Data Mining Primitives
- Data Mining MCQ
- Data Mining Projects