Cassandra Query Language Basic Queries
This module of the Cassandra query language will give you the basic command and queries used in CQL. Although, it mostly resembles the SQL basic commands, but Cassandra has it’s own unique advantages, especially on distributed data. This can be accomplished creating table which is entirely oriented/ dedicated towards a single command.
Here are the commands we will be illustrating,
- Insert
- Truncate
- Update
- Delete
- Cassandra Where Clause
Insert:
The 'Insert into' command inserts data into Cassandra columns in a row format. This will only save the columns that the user specifies. Only the primary key column must always be specified.
It will not take any space for not given values. No results are returned after insertion.
Syntax:
Insert into KeyspaceName.TableName(ColumnName1, ColumnName2, ColumnName3 . . . .)
values (Column1Value, Column2Value, Column3Value . . . .)
Example
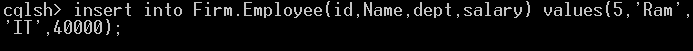
Insert into Firm.Employee(id,Name,dept,salary) values(5,'Ram','IT', 40000);Once the command 'Insert Into' has been successfully executed, a row with Id 5, IT department, Name RAM and salary 40000 will be placed at the Cassandra Employee table.
Below is the screenshot of the present Keyspace Firm.

Truncate:
This helps us in removing the basic data. Viz, the rows of the table will be entirely be removed yet, the structure, columns, constraints will remain as it is.
Syntax:
Truncate KeyspaceName.TableName;Example:
Below is a screenshot that demonstrates truncate in Cassandra.

After successfully implementation of the truncate on table Employee.
Below is the screenshot after the implementation of truncate.

Update:
The Update command is used in Cassandra Table for updating the data. If after changing the data no results are returned, then the data will be properly updated else an error will be returned. The 'Set' clause will modify column values, whereas the 'Where' clause filters data.
Syntax:
Update KeyspaceName.TableName
Set ColumnName1=new Column1Value,
ColumnName2=new Column2Value,
ColumnName3=new Column3Value,
.
.
.
Where ColumnName=ColumnValue
Example:
Below is the screenshot demonstrating the condition of the Keyspace before updating the data.

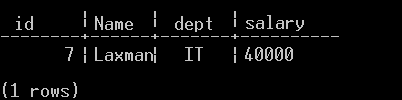
Below is the screenshot of the 'Update' command executed, which updates the Employee table's record.

Update Firm.ZEmployee
Set name='Laxman'
Where id=7;
Once the command 'Update employee' has been successfully executed, the employee name is changed from 'Ram' to 'Laxman' and also the id changes to 7.
Below is a screenshot demonstrating the status of the Keyspace Firm following the updates of data.
Delete:
The Delete command removes from the Employee Table the whole row or certain columns. If data is erased, it is not instantly deleted from the table. Instead, the removed data is marked with a gravestone and then deleted following compaction.
Syntax:
Delete from KeyspaceName.TableName
Where ColumnName1=ColumnValue
Data filtration is a function in which the above syntax will remove one or more rows.
Delete ColumnNames from KeyspaceName.TableName
Where ColumnName1=ColumnValue
Some columns will be deleted from the table using the syntax above.
Example
Below is a screenshot showing the present status of the Keyspace before the data is deleted.
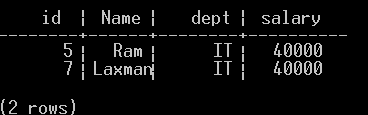
Below is the command screenshot that removes a row from the Employee Table.
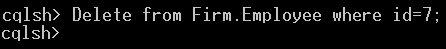
Delete from Firm.Employee where rollno=7;After the 'Delete' command has been executed successfully, one record from the Employee database with id values of 7 is removed.
This is the screenshot demonstrating the status of the Keyspace Firm after removing the information.
Cassandra opposes the following:
Cassandra query language has the following constraints (CQL).
- Joins are not supported by CQL.
- Only the clustering column supports greater than (>) and less than () queries.
- OR queries are not supported in CQL.
- Union and intersection searches are not supported by CQL.
- Aggregation queries such as max, min, and average are not supported by CQL.
- Group by queries are not supported in CQL.
- Wildcard queries are not supported in CQL.
- Filtering table columns is impossible without first building an index.
Because to its various restrictions, the Cassandra query language is not appropriate for analytics.
Where Clause:
Data retrieval is a delicate problem in Cassandra. The column is filtered in Cassandra to provide an index of columns that are not primary.
Syntax:
Select ColumnNames from KeyspaceName.TableName Where ColumnName1=Column1Value AND
ColumnName2=Column2Value AND
.
.
.
Example
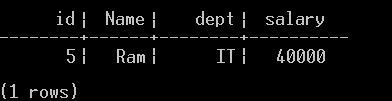
Below is a screenshot of data retrieval from the Employee database without any data filtering.
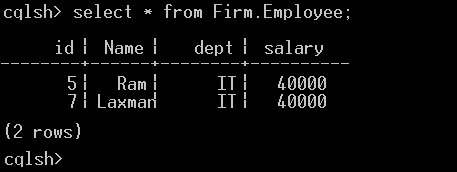
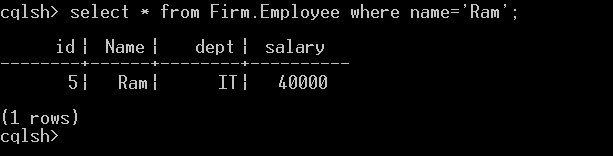
select * from Firm.Employee;From the Employee table, two entries are obtained.
The data retrieval from Employee with data filtering is shown in below screenshot. A single record is obtained.
The name column is used to filter the data. All records with a name equal to Ram are retrieved.
select * from Firm.Employee where name='Ram';