Cassandra VS RDBMS
Cassandra:
Apache Cassandra is a distributed in a NoSQL database management system. Mostly deals with high amount of data stored across various machines. The large scale data is handled with the help of the architecture.

Same data is stored across various machines i.e, replica of data which enables high availability and no single point failure.
Cassandra Architecture:
- Dynamo: It has a ring-type structure. All the nodes are connected to each other and have no master node. If the request is given it hits one of the nodes and that node processes the request and writes on to the database.
- Gossip: The node after writing signals other nodes to update the data as well. This way of interaction between nodes is known as Gossip.
- Failure Detection: Due to absence of central node, failure of the node to update is usual which is detected and recovered.
- Replication: As the requirement the replication of data can be done in the nodes.
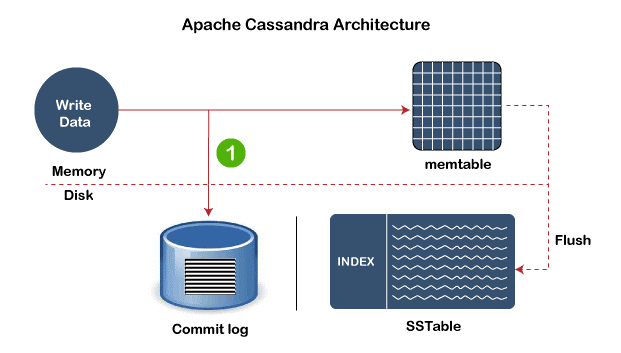
Storage Engine:
- Commit-Log: Any data in Cassandra is written before in commit-log then in mem-tables. This improves the durability of data and risk of shutdown.
- Mem-tables: These are memory structures where Cassandra buffer writes the data.
- SSTables: Themem-tablesare further flushed into the disk and converted into SStables. These are immutable data files used for prevention of risk.
Cassandra’s core objective to accomplish large scalability, availability, and having storage requirements accordingly is achieved through the architecture of Cassandra.
RDBMS:
RDBMS viz, Relational Database Management System is a software which is controlled with the help of SQL (Structured query language) for maintaining and manipulating data.
It deals with data at moderate velocity and structured data. The data is represented in row and column paradigm. The row represents the records and the column represents the attributes.
RDBMS Architecture:
One of the first multi-server, multi-user systems was the relational database management system (RDBMS).RDBMS (Relational Database Management Systems) have been in use for more than two decades. It is still used are major tool for many applications in today’s time.
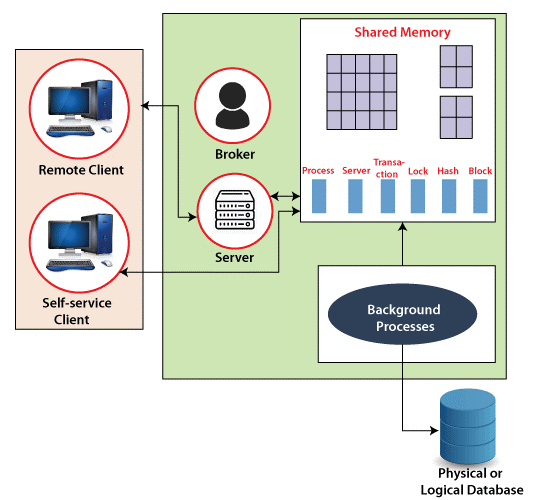
- Process Manager:When the client requests, the process manager launches a processing thread. It links the data and controls the thread output to the right communication management customer. The process manager must first assess the availability of sufficient system resources to perform the query or postpone it until later.
- Client Communication Manager: An application must establish a network connection with a database in order to communicate with it. A link is established between an application and the Client Communication Manager. Through both local and distant protocols, this component allows communication between multiple database clients. Its major job is to keep track of communication status, return data.
- Transaction and Storage Manager: After a query is processed, the Transaction and Storage Manager obtains the desired data. It acts as a checkpoint for all data access and modification requests. The transaction and storage manager also guarantees that the ACID properties of a transaction are respected, thereby avoiding the lock and log management need.
- Common Components and Utilities - A database must have a number of shared components and utilities in order to function.
- Relational Query Processor:When a request to execute a query is received, the Relational Query Processor checks to see if the user is permitted to run the query. The query is then compiled into an intermediate data structure that is further optimized. Which, finally uses the transaction and storage monitor, executes the resultant plan.
Differences between Cassandra and RDBMS:
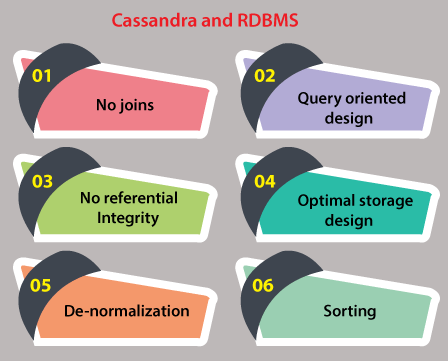
- No Joins:
One cannot perform joins in Cassandra. In Cassandra if a data model needs joins one has to create a de-normalized second table or has to do someclient side work to get the target results. It is a very rare case in Cassandra to perform joins. In RDBMS joins can be performed for implementing complex queries.
- No Referential Integrity:
Cassandra supports feature such as batches and transactions which are light weight, but Cassandra has no feature of referential integrity. In relational databases, for the reference of another table, one could create a foreign key referencing with primary of that another table.
- De-normalization:
The concept of normalization is very important in relational databases as the data on which queries are performed is normalized data. In case of Cassandra there an advantage as the best performance is obtained on de-normalized data. Usually companies tend to de-normalize data in relational databases as well. Though joins is very useful it fails to give output on year’s worth of data.
Relational databases sometimes tend to get de-normalized data for structuring which implements retention.
In simple words, de-normalization in relational database is a bane as it violates codd’s normal forms. While in the case of Cassandra de-normalization is normal.
- Query Oriented Design:
The conceptual domain which represents nouns in domain in tables is known as relational modeling.
In model relationships one assigns foreign keys and primary keys for many-to-many relationship interaction between tables. These joins does not appear in real world cases.
In relational database first all the tables are put forward and then queries are applied all together. While in case of Cassandra, the task won’t start until on query is not implemented. Hence, writing tables first and applying queries is done in relational database. While model the queries and data be organized by them is done in Cassandra.
- Optimal Storage Design:
The tables are stored on disks in relational databases and it is transparent to the user. Hence the question was never really argued how tables are stored in disks in relational database.
In Cassandra the tables are stored in each separate file on disk. Therefore, keeping related columns defined together in the same table is very important.
- Sorting:
One can easily change the order (sorting) of the records in relational database by using ORDER BY function in RDBMS.
Usually with using that query the default result records returned in same order they are written.
In case of Cassandra sorting is considered as design decision which is very different to conventional relational database. The sorting in Cassandra queries are default and it is entirely dependent upon selection of clustering columns given in the create table.
Comparison Table:
|
CASSANDRA |
RDBMS |
|
|