Netflix - System Design
System design questions are common in many technical rounds for huge tech companies like Amazon, Google Flipkart. Candidates get confused about how they should answer the system doesn't question in such interviews. But I take to do so is to just focus on the main components and try to clarify the approach that you would use in such real-case scenarios instead of just mentioning the tools used for developing the software. One of the most common questions asked in system design interviews is to design a system similar to Netflix.
In this article, we will discuss how you should answer a question to design a system similar to Netflix in just 45 minutes.

Netflix's High-level System Architecture
Everyone today would have used for at least heard about one of the largest ott platforms, Netflix:
Such platforms have a wide variety of movies, web series, and television shows and users have to pay a monthly fee or a monthly rent to access content over these platforms.
Today as per the records, Netflix has more than 18 million subscribers in almost 200 + countries.
It works basically on two clouds, namely AWS and Open Connect. These two cloud services are primarily responsible for the best-known service by Netflix.
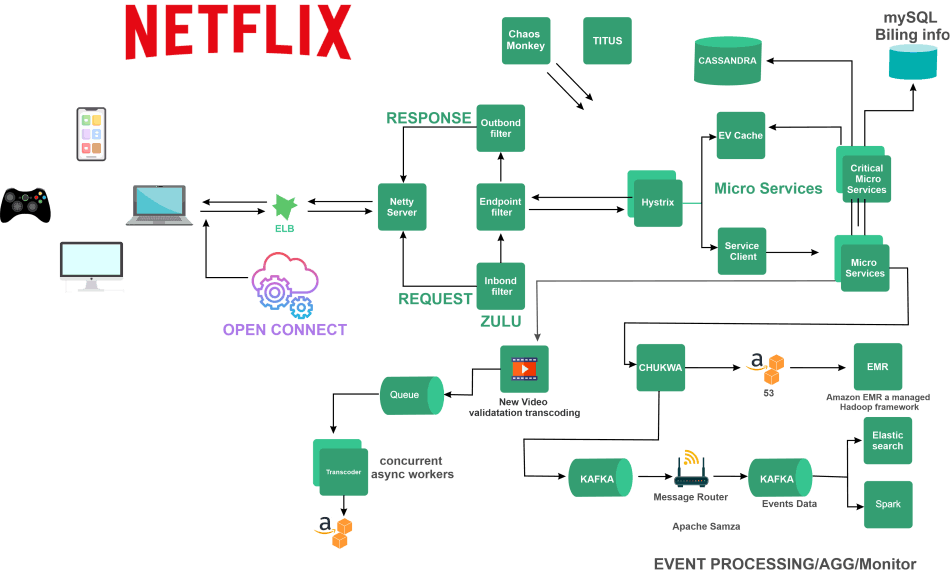
Some of the significant components of Netflix are:
- Client
This component deals with the user interface or device which would be used to browse the content of Netflix
Ex. Tv, Laptops, mobile phones etc. - Netflix CDN or OC ( Open Connect )
CDN is the network of distributed services in different geographical locations. The content delivery network used by Netflix is known as open connect. Open Connect is responsible for handling and managing all the tasks, including video streaming for each movie or web series. The content is distributed all over, and whenever the client hits the play button, the video stream is then sent over to the client.
For example, if any client from India tries to play a video on Netflix, it would be made possible by the nearest open connection. This approach helps to reduce the latency while browsing through the videos. - Backend
The database part is responsible for handling all the features of Netflix besides streaming the video. Before the user hits the play button, the Backend service manages every element. The backend drives the network traffic on the website; it onwards the new content on the site and distributes it all over the network of servers of Netflix. Amazon Web services handle most of the tasks performed by the backend for Netflix. - The frontend Design
For Netflix is developed using the JavaScript framework known as ReactJS. Since ReactJS provides comparatively higher runtime speed, runtime performance and the ability to module different components, this was proved to be the optimal choice for designing Netflix.
How does Netflix Onboard a Movie or Video?
Whenever Netflix receives high-quality video content from several production houses, the overall content is firstly preprocessed instead of directly serving the users.
Netflix, an extensive system, supports more than 2000 devices, and each unique device would need video content in different resolutions and formats.
Platforms like Netflix are also expected to create file optimization for different network speeds.
Netflix creates almost 1000 to 1200 copies or replicas of the same video for different resolutions. The process of creating the replicas requires a lot of preprocessing and transcoding.
Netflix divides large videos into smaller parts of chunks. It then uses the parallel workers available in the Amazon Web service to convert the fragments into different resolutions and formats.
Some of the resolutions and formats available with Netflix are (4k, 1080p, etc. ) and ( MP4, 3gp, etc. ), respectively.
After all these preprocessing and transcoding, we get multiple replicas of the same video. These copies are transferred to every CDN or Open Connect server at different Netflix offices worldwide.
Once the user loads the Netflix app or goes to the website on their device, the first page, such as the login page or home page, including the recommendations or users history, account information etc., is also handled primarily by Amazon Web Services.
After the homepage is loaded and the user plays any video, Netflix tries to analyze the internet connection's bandwidth (speed and stability). Depending on the device used by the user, video with the correct format is streamed using the nearest Open Connect Server.
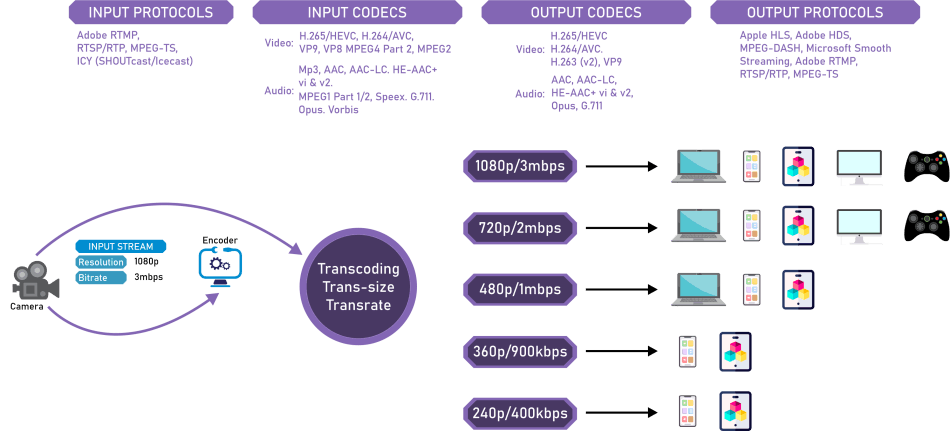
You might have noticed that sometimes while browsing a video, the screen resolution decreases at some bits and gets back to the HD resolution; this is because Netflix constantly analyzes the network speed and renders the chunks with the resolution, which would minimize the buffering latency.
The search history, location viewing history reviews etc. are also in the AWS for each user, and Netflix movie recommendations for users are made by using this data in any machine learning model or Hadoop.
Advantages of using Open Connect in Netflix,
- Affordable
- Adaptable
- Provides better quality
- Scalable
Components that help Netflix work smoothly
Now let us discuss some of the essential components that help extensive systems like Netflix work smoothly.
1. Elastic load balances
ELbs in Netflix are responsible for routing the traffic from each user to the front-end services. Elastic load balances in Netflix implement load balancing in two primary stages to balance or distribute the traffic over the different zones and then instances.
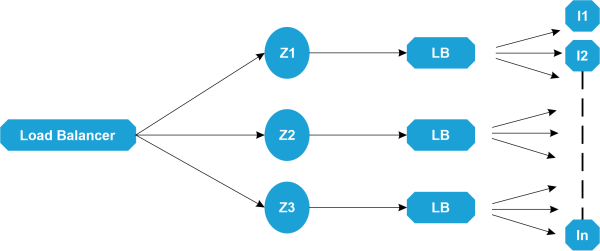
- The first load balance level consists of the DNS-based Round Robin technique. Once the first load balancer encounters the user request, it is distributed across the zones using the round Robin algorithm.
- The second level of load balancing takes place by storing all the instances of a load balancer from the same zone in an array, and then the requests are distributed across all the instances in the array by the Round Robin algorithm.
2. ZUUL
This kind of gateway service is used to route the request dynamically and monitor the request and provides residency and security for your system; ZUUL lets you route requests easily through query parameters, URLs and paths.
The primary working components of ZUUL are:
- The Netty Server
It is responsible for managing the connections, web server and network protocols and proxying work. Whenever the requests hit the Netty server, it would directly proxy the request to any inbound filter.
- The inbound filter
Once the Netty server forwards the request to the inbound filter, it is now responsible to authenticate, decorate and route the request. After this, it is then passed on to the endpoint filter.
- The endpoint filter
This is used to return the static response directly or forward the request to the backend service if it wants any dynamic output. Once the endpoint filter receives the backend service's dynamic response, it sends the result/request to the outbound filter.
- The Outbound filter
This is basically used just to zip the content and calculate the metrics or to add/remove the custom headers.
After this, the response is then sent back to the Netty server, and at the end, it is forwarded to the client.
Advantages
- Traffic can be distributed easily just by distributing different parts of the traffic to the different servers. You can define some rules to share the traffic among different servers.
- Developers are also allowed to do load testing on newly deployed clusters in some of the machines. Some of the existing traffic can be easily routed on such clusters to check the capability of the load they can handle.
- New services can be checked. Whenever you feel like upgrading your service, you can check how it behaves with the real-time APIs. In such cases, any particular service would be deployed on any server, and some parts of the traffic can be redirected to any newly available service.
3. Hystrix
Hystrix is a type of complex distributed system. In hystrix, a server can rely on the response generated by any other server. However, there is a chance that the dependencies among the servers may lead to latency, and also, the entire system may stop working if any one of the servers in the hystrix server fails at any point. The simple fix for this issue could be to isolate the host server of our application completely so that it doesn't get affected by the status of all the other connected servers.
The Hystrix Library is designed in such a way that it is responsible for this job, and also it enables you to trace the interactions or communications between the distributed services such that it distributes the services by adding the latency and fault tolerance logic in it. Hystrix basically isolates all the access points between the remote system, services and any 3rd party libraries.
The Hystrix library is helpful for
- Stopping the Cascading failures in any complex distributed system.
- Controlling the failure and latency due to the third-party client libraries.
- Recovering fastly after any failure
- Gracefully degrading and fallback when needed.
- Real Time monitoring and Operational Control
- Automating the batches through the collapsed requests.
- Caching requests concurrently
- Alerting
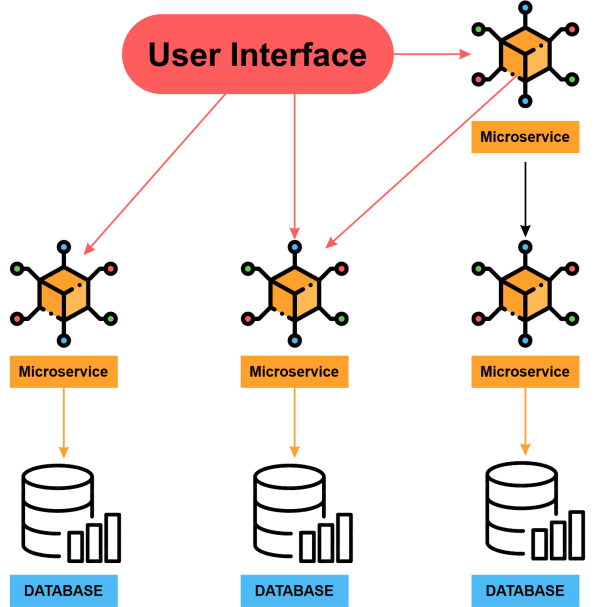
4. Micro-service Architecture of Netflix
The architecture style used to create Netflix is basically a collection of services, and this architecture supports every API that would be used for developing applications or web apps. Once the request arrives at the end of the Micro-service Architecture, it calls any other micro-service to get the required data. After all this, a systematic and complete responsibility for the API request is forwarded to the endpoint.
In a micro-service architecture, the services used are supposed to be independent of each other; for example, the video storage service would be completely separated from the service used to transcode the videos in different formats.
How can we enhance the reliability of Micro-service Architecture?
- Use Hystrix
- Isolation of Critical Microservices
As we have already mentioned, the different Microservices are supposed to be independent, which would also help us to make the architecture more reliable. We can isolate some complex but primary APIs and try to make them lesser dependent on other services. By isolation of service, we mean that you should ensure that the endpoints are highly available and that the user can do the basic tasks even in any worst scenario. For example, while choosing a critical microservice, you could include the basic functionalities like searching / navigating to a video or hitting the play /pause button etc.
- Treat Servers as Stateless
Let's try to understand this concept in a real-life situation. Assume that you are a caretaker at a poultry farm; now, you collect a certain amount of eggs daily. If someday you find out that one of the hens is not producing the right amount of eggs, you just need to replace the particular hen with a healthy one.
Similarly, if any of the servers in your application is unable to produce the correct results due to some reasons and runs into errors again and again, you need to switch to any other endpoint to get your work done quickly. That means instead of being struck on a specific server and letting it preserve the state in that server, you are supposed to spin up to a new node or end point so that if any server stops working, it can be replaced.
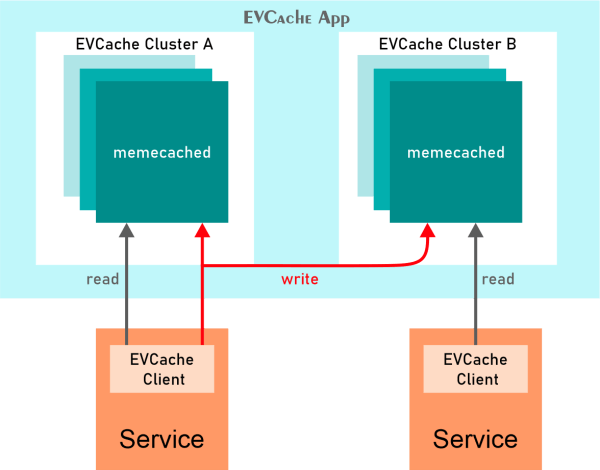
- EV Cache
We already know how we can use the standard cache in our applications. In many applications, some of the data is used repeatedly or frequently. And To reduce the latency, such information is stored in a special kind of storage location called a cache. Retrieving data from these points instead of the original server is easier and faster.
But the problem here is that if the node goes down for some reason, the cache goes down too, which can affect your application's performance. To solve this problem, Netflix has designed a specific caching layer called EV Cache. EV cache is nothing but a kind of simple wrapper around the Memcached.
- Database
To manage its data, Netflix uses two separate databases, i.e. MySQL ( RDBMS) and Cassandra (No SQL), to deal with different tasks.
- EC2 Deployed MySQL
Netflix is responsible for saving the data of all users, billing, and transaction details. Netflix also needs ACID compliance. Netflix uses a master-to-master setup for its MySQL database, which is then deployed using the InnoDB on Amazon's large EC2. EC2 stands for Elastic Compute Cloud.
Master to master type of setup is "Synchronization replication protocol", where if anything is written over the primary master node, it is replicated in the other master node too. The write operation acknowledges only when the data is written over the local and remote master nodes.
The synchronization process makes sure that the database is reliable and highly available. The read replica is also set up for each node in Netflix, which enables it to access data more easily. This process ensures that the database system is highly available and scalable too.
In this technique, all the write queries are redirected towards the master nodes. However, the read requests are redirected towards the read replicas only.
In case when the primary master node in MySQL fails for some reason, then the secondary master can easily take the place of the primary node as the complete data was synchronized and replicated on the second database node too. To do so, the route53 ( DNS configuration) will be then switched to this node, and it would also redirect the new write queries towards it.
- Cassandra
It is a NoSQL database that handles much reading and writing on Netflix. It is primarily known for handling large amounts of data simultaneously. When Netflix became popular, and millions of people subscribed, keeping track of each user's viewing and search history became more complex.
Handling this Increasing amount of data was tough for Netflix, so they scaled the storage view of historical data. Netflix primarily focused on two goals while scaling its system.
- Consistency in reading/writing performance per growing members.
- Smaller Storage Footprint.
The basic De-normalized Data Model in Cassandra consists of the following:
- More than 50 Cassandra Clusters
- Biggest Clusters having around 70+ nodes.
- 500+ nodes in total.
- Around 30TB of data is backed up daily.
- Each cluster with the ability to perform over 250k writes operations per second.
.
In the initial phase, the viewing history of each user was stored in a single row in Cassandra. But as the number of users increased and time elapsed, the row sizes, as well as the number of rows, increased too. As an outcome of this growth, the application's performance degraded, cost increased and required High storage.
To enhance the storage system, Netflix classified the data into two parts
- Live Viewing of History
In this section, there were fewer recent viewing historical data; usually, Live Viewing History was stored in an uncompressed form. - Compressed Viewing History
A large amount of data with lesser updates was compressed and stored separately. This data was held as a single column per row key, and the data was compressed to minimize the data footprint.
Data Processing in Netflix
Netflix usually takes less than a nanosecond to process various data as soon as you click on a video, and it uses Kafka and Apache Chukwa to do so. Let us try to understand the working of this evolutionary pipeline on Netflix.
Netflix provides around 500B+ events that may consume about 1.3 Peta Bytes of data daily and 8 million events that may even consume 24 GB per second.
These events may include information such as:
- Error Logs
- Performance Events
- Diagnostic events
- Troubleshooting
- Video streaming events
- UI activities
Apache Chukwe is a kind of Open source data collection system. It's primarily known for handling logs or events from a distributed system. There are various advantages of Apache Chukwe like
- Robust and Scalable (Hadoop's features)
- Flexible Toolkits
- Able to do monitoring and analysis of dashboard
- Writes data in Hadoop's file sequence
- Provides traffic to Kafka to upload the events to EMR/S3
- Routing process is done using Apache Samja
- Elastic Search
Netflix has grown drastically in recent years in Elastic Search. Today, Netflix is known for running around 150 + clusters hosting around 3500 instances.
Netflix uses this feature for data visualization, customer support, and error detection techniques.
Besides troubleshooting, Elastic Search is also used to keep track of the information by the admin. Elastic search also aids in keeping track of resource usage and detecting login or signup problems.
- Apache Spark For Movie Recommendations
Movie recommendations and personalization on Netflix are made possible by Apache Spark and Machine Learning. Let's understand how this works; the machine learning pipelines in Netflix are executed on the large Apache Spark clusters. Then these are used to do the row sorting and title relevance ranking and then sort the data according to the relevance of recommendations and show it to the users.
- Artwork Personalization
You would have seen thumbnails of various recommended videos on the Netflix front page. Netflix wants a large number of users to interact with videos, and hence for that, they need to choose the most appealing thumbnail (also known as header image). To determine the best header image, Netflix creates various artworks and depending on the viewing history, the thumbnails or header images for each user can be different. Based on the viewing history, Netflix tries to predict which header image would be best for you. And according to the user's taste, the thumbnails are chosen for them.
Netflix also calculates the number of clicks and views associated with each picture to perform the data analytics with the data-driven approach. And the images selected by this approach are used for your header images.
- Video Recommendations on Netflix
The Netflix platform also helps the user to find their favourite content. To build up the recommendation system, Netflix tries to predict the user's tastes and interests. To do so, it collects various data from users:
- Type of content the user interacts with.
- Other users with similar interests.
- Titles, genre, categories etc., of Previously Watched videos.
- Device used by the user.
- Average active time of the user.
Netflix uses two algorithms to build the recommendation system, namely,
- Collaborative Filtering
- Content-based Filtering
By keeping these points in mind, you can quickly answer a question about designing a massive System like Netflix.