Twitter - System Design
You might have heard of Twitter, a widely used social media platform. Everybody tends to check it every few minutes. Imagine what you would do if you were asked to design this massive system with this much user traffic within 45 minutes. Yes, this could happen in any system design interview.
You are expected to tell the approach you would follow to handle such projects; let us discuss what steps you should follow while answering such questions and the primary topics you should focus on.

How would you design Twitter?
In such questions, you are not expected to design the entire system, and the interviewer would only be expecting to understand the approach you will follow to solve this kind of real-life problem. Many candidates directly start to name the tools and technologies that they would use, for example, frameworks like bootstrap or MySQL, but you should know that the interview expects high-level realistic ideas to solve the problem instead of technical terms.
Firstly you should take your time to understand the problem statement and then clarify the same with your interview. In this question, we will compress the gigantic Twitter application to its minimum Viber project and work on designing it.
It would be best if you understood that no one is expecting you to design the complete service that has been made possible by thousands of software engineers working for decades, so we will only be discussing the core features of our application instead of jumping on everything.
Step 1: Examine the core features.
So firstly, divide the complete system into several primary parts and discuss some important properties of each. For the sake of clear understanding, let us consider only some of the basic features of Twitter like
- An application user can post any "tweet" in a few seconds.
- The user should access the tweets from the people they follow on their timeline.
The timeline can be classified into three parts:- User Timelin
The account holder sees their tweets and replies on this Timeline that would be displayed to any user when they visit their profile. - Home Timeline
This timeline would contain the tweets from the people or pages you follow. - Search Timeline
Whenever the user searches for any keyword or hashtag, they would see the tweets related to that particular keyword in this timeline.
- User Timelin
- Users can follow or unfollow someone.
- Tweets of the user should be broadcasted to every follower under a few seconds, even when they have millions of followers.
Naive Approach
Before directly moving towards the high-level solution to design a system like this, we should first understand the Naive approach and discuss the problems that could arise when we follow it.
- Data Modeling
When can you create a relational database management system like my SQL and can manage the whole data with the help of two tables, namely,
User Table ( ID, username )
Tweet Table (ID, Content, User)
Whenever a new user registers, its data get stored as a record in the user table; similarly, every tweet posted by a user would be stored in the tweets table along with the user ID of the user that posted it.
There would be two relations here, one for the owner of each field and the other for when the users follow each other. And clearly, the first would be a one-to-many relationship between the user and tweets table and a one-to-one relationship between two users. - For the Home timeline
You would need to get all the tweets from all the people the account follows and then display them in a particular sequence. - Limitations of this architecture
For this approach, there would be a requirement to write a substantial 'select' query in the tweet table to fetch the data from all the users the account is following. Even after that, you would need to display the tweets in chronological order. You are also expected to optimise this solution, as fetching the data from the table again and again would result in a delay in execution, as there are many records in each table.
Let us first discuss the characteristics of Twitter before moving toward the high-level solution:
Twitter is a gigantic platform with millions of daily active users (approximately 300M), which may result in around 5000+ tweets every second. So, there would be about 5000+ queries made in the tweet table for each unique tweet every second.
Let us assume that an average Twitter user has 200 followers, and along with this, some influencers or celebrities have millions of followers; from this, you should note that:- Twitter would have a lot of read operations compared to the write operations, so we should make sure that the system we design should be more available, and we should scale the application to be reliable for massive read requests simultaneously.
We should also consider that even if the user tweets a bit late, the data should be consistent throughout the system, meaning the number of likes on a Tweet or comments should be synchronised. - Storage space won't be an issue since there is already a limit of 140 characters for each tweet.
- Twitter would have a lot of read operations compared to the write operations, so we should make sure that the system we design should be more available, and we should scale the application to be reliable for massive read requests simultaneously.
High-Level Solution
After discussing the characteristics of Twitter, we now know that Twitter is a heavy system, so we would need to read or fetch data from the database faster, and we would prefer horizontal scaling if required. Here Redis can be proved to be an optimal choice to store the data, but we cannot depend on it solely.
To keep the data consistent, we should consider the architecture of our application with these three tables, namely,
- User Table
- Tweet Table
- Followers Table
When a new user registers, the profile will be recorded in the user table
The tweets from every user would be stored in the tweets table along with the username of respective users
As a single user can tweet many times, there would be a one-to-many relationship between the user and the tweet table.
When any user follows any other user, its data gets stored in the follower's table.
The user table would have a one-to-many relationship with the followers table too.
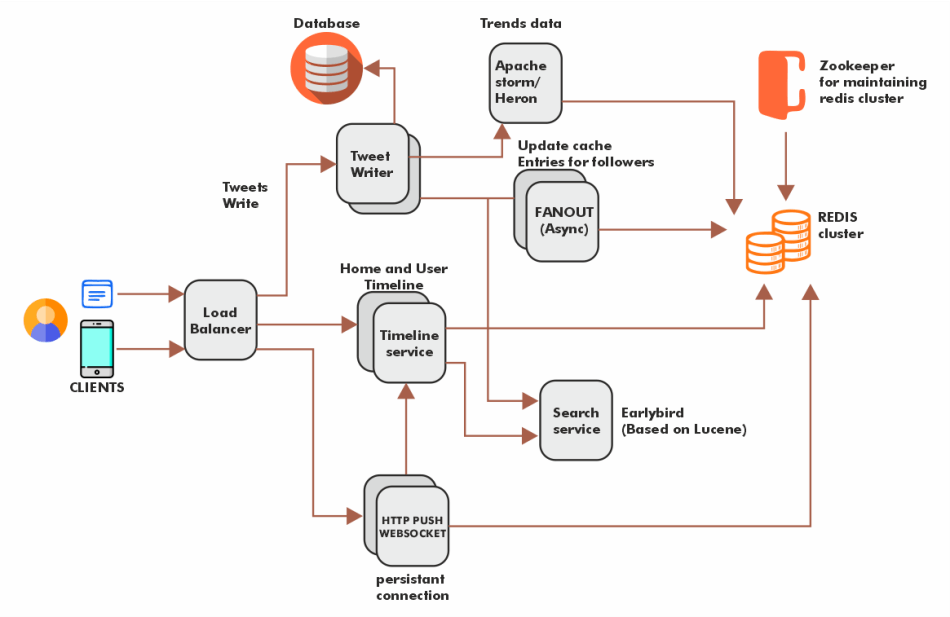
User Timeline Architecture
The user timeline contains all the tweets retweets with original tweet references of a specific user, so here to get the user timeline, we would simply fetch the user ID from the user table and then set all the respective tweets against the same user id once we get all the tweet we can merely sort it according to the date and time and then display it on the timeline in chronological order.
Remember that Twitter would have heavy read requests, so the above approach won't work every time; hence, to execute the system properly, we would need to add a caching layer and save the user's data. Since the data accessed once gets stored in a cache, it would not be that difficult to access, and the overall process would be much faster.
Home Timeline Architecture
The home timeline of any account contains all the latest tweets from all the pages and users followed by the particular account. For this, a system would need to get all the entries from the followers table and then fetch the respective tweet of every user and sort them in chronological order to display them all together on the Home timeline.
Although this looks pretty simple, this approach has some drawbacks too.
Since these queries are heavier, this would create an unnecessary latency while refreshing the timeline, as it would take much more time when the tweet table gets larger and larger. We can solve this drawback using one of the two approaches
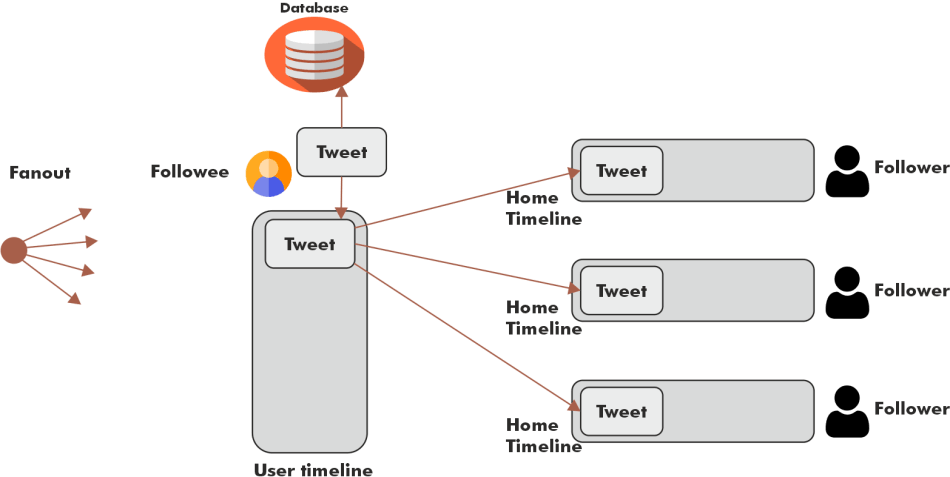
- Fanout Approac
In this approach, instead of accessing the data again and again from the database, which is distributed or fan out every new tweet to every follower's home timeline and this technique, we go to the cache by user id and access the home timeline data in Redis and add the new tweet to it.
The complete flow of this method would look somewhat like this.
- Assume that if three uses follow any particular user X, the tweets from user X get stored in a cache named user timeline.
- When the user x tweets something, the new tweet flows into the backend service through the load balancers.
- Backend Servers would store the tweet in the database.
- The server would not get the data of every follower and will inject the new tweet into the memory timeline of every follower
- Followers of user X will soon find the new tweet of X in their respective home timelines.
Now let us consider when an account with millions of followers tweets something. Will the above approach still be optimal?
Since updating millions of timelines from this approach is not scalable and hence a solution for this problem that could be used would be:
Update the user's home timeline first without considering the account with huge followers (celebrity).
The celebrities that a user follows are stored separately in the cache, and whenever a new request or tweet from a celeb is received, you can get that celebrity from the list in the cache and get the tweets from the user timeline of the star and with the new tweets are then displayed on the home timeline of the user at the run time.
We can also optimize our system by not considering refreshing a computer and the timeline of inactive users.
(People who don't log in to their account for two or more weeks can be classified as inactive)
Search Timeline Architecture
You would have noticed that tweets on Twitter, whenever searched, also appear if they even have only one similar keyword. This is because Twitter handles the search operations on his fields and hashtags using the early bird. Early bird is a real-time reverse index based on Lucene, and the early bird does full-text inverted indexing. By this, we mean that the tweet posted is considered as a whole document rather than just a string.
We get split into various tags, and then these unique tags are the index and stored in a big or distributed table.
Each tag would be able to reference or point out all the treats with that particular word.
Since the index can be searched easily, this would optimize the search operation for search timeline architecture.
Twitter can handle thousands of tweets every second, so we cannot expect anyone big system or table to work solely.
Twitter uses scatter and gather, where the data is scattered across multiple servers for data centres that enable indexing.
Whenever Twitter gets a query, it will send the query to all the data centres, and they return all the early bird shards.
The shards that match the search output are then sorted in rank based on the number of retweets/ replies and the tweet's popularity.
This way, we can design a massive system like Twitter.
You can even talk about other significant components like handling trending sections or notifications etc, if you wish in your interview.