Python Iterator Design Pattern
Definition: This is one of the variations of behavioral design patterns. It helps you to traverse through a collection of various elements without exposing the multiple layers of elements. It is used to solve a particular problem.
It makes navigation simple and easy. We can easily decompose the existing data from the algorithm. It is a simple and frequently used design pattern. Each database consists of huge information in a structured format. Then, it must require an iterator for traversal. It is assumed that internal implementation is not shown. Suppose we are constructing an IOS app for managing the notifications. If we want to access all the notifications, then an iterator is required for traversal, and the way of iteration changes if the data structure is queue, tree, or graph. Still, the basic logic of traversing through each element remains the same.
Problem statement :
Data collection can be a collection of objects, and different databases store them differently. Some stores it as array lists or in tabular form, but there are complex data structures where data is stored, such as a tree, graph, queue, and stacks. No matter how data is stored and structured, it must provide some reliable way of accessing the data so that code can use those data. We must not go through a plethora of elements again and again to access some particular object. All of this might sound easy, and you may think that we can implement this and access all the data whenever we want by just forming a loop in the database, but think once how the sequential traversal within the complex structure will be done? Let it be a tree, one day, you might get desirable data through breadth-first traversal, the next day, you might need depth-first traversal to get the desirable data quickly, or you may need level order traversal. Then after some day, you may need something else to get your data randomly. So just for the tree, you must add various data collection algorithms. Adding this many algorithms just for one structure may make our code bulky and less efficient because the data collection might also consist of some other structure. Hence, you must add various algorithms again, forming an endless cycle of adding techniques because data will grow from time to time. There is a limitation, and you cannot use this much algorithm again because you have to make changes in the basic structure of the code, which may spoil the basic terminology. Our code will become ugly and blurry, which will be tough to understand, and each algorithm works for a specific structure. They cannot be used everywhere, so including them in our generic collection is not good.
Conversely, the client's code must work on each collection irrespective of its structure because the client only wants to access all data. They are not interested in implementing the structure, and the client does not care how the data is stored until and unless any bug occurs. So it's your responsibility to add the most reliable feature for accessing the elements irrespective of their structure. As per your algorithmic technique, there are no other options than some collections, so how would you solve this problem?
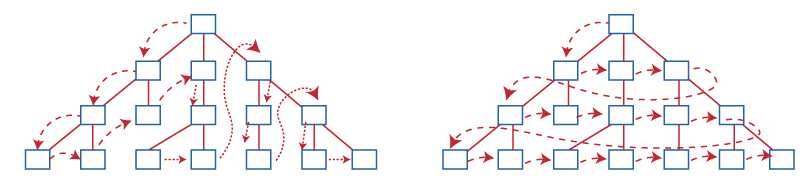
[Above image displays two ways of accessing elements in the tree]
Solution statement :
The best possible way of solving this problem is encapsulation. We will store all the information while traversal, such as how many objects were there, how many are left, current positions, etc., and then we will store these details so once it is done, we can assign several iterators for several tasks and all of them now can access the desirable objects easily because of stored information. The stored information plays the role of a game changer, and it helps all the iterators to get their particular objects simultaneously and independently of each other. Now iterators will not depend on any previous interaction. Each can work individually.
Usually, the primary traversal method is only one, and the client would run dissent until it returns something. Once returned, it assures that all the elements are traveled, and information is kept. And there is a need for a special method to access the information, then you can make a new class rather than interfering in the client class, and it will work efficiently. All existing iterators must implement the same interface, making the software compatible with the user so that the user can use it easily.
Real-world problem example of iterator design pattern :
Suppose you decided to visit Spain for a few days. All of the places are new to you. You do not know the best way to travel across the country to visit the most popular places in a few days of your tour. Without any guide you might be roaming around unaware of where to go first and what to visit next. so there are mainly two options first one is you can buy virtual travel assistance, this is inexpensive and a good way to know about the best possible way of traveling and visiting popular places. The second way can be hiring a guide(person) to assist you throughout the journey. This is also a better way to travel, but this might be expensive, the guide will tell you stories about the place, and you may end up visiting the best places, it will be fun.
So from the above text, you must understand the importance of information. You can only travel to the best places if you have good information about distance, time, etc. Both human and virtual guides can assist you as both have information about Spain. So this represents the basic terminology of the iterator design pattern. We will store all the information while traversal and all of the iterators can now access the desirable objects easily because of stored information.
example .py
class Food_Item:
def __init__(self, name, price):
self.name = name
self.price = price
def __str__(self):
return f"{self.name :<6}: $ {self.price}"
class Menu_here:
def __init__(self):
self.items = []
def _add(self, item):
self.items.append(item)
def remove(self):
return self.items.pop()
def _iterator(self):
return Menu_Iterator(self.items)
class Menu_Iterator:
def __init__(self, items):
self.indx = 0
self.items = items
def has_next(self):
return False if self.indx >= len(self.items) else True
def next(self):
item = self.items[self.indx]
self.indx += 1
return item
if __name__ == '__main__':
i1 = Food_Item("Burger", 10)
i2 = Food_Item("Pizza", 9)
i3 = Food_Item("Coke", 4)
i4 = Food_Item("chicken", 7)
i5 = Food_Item("rice", 8)
i6 = Food_Item("sandwitch", 5)
menu_here = Menu_here()
menu_here._add(i1)
menu_here._add(i2)
menu_here._add(i3)
menu_here._add(i4)
menu_here._add(i5)
menu_here._add(i6)
print("hello buyers, i hope you all are doing good, so today we have below dishes for you ----Displaying Menu:")
_iterator = menu_here._iterator()
while _iterator.has_next():
item_present = _iterator.next()
print(item_present)
Output :
hello buyers, i hope you all are doing good, so today we have below dishes for you ----Displaying Menu:
Burger: $ 10
Pizza : $ 9
Coke : $ 4
chicken: $ 7
rice : $ 8
sandwich: $ 5
Explanation of the code :
This is a very simple example of fast food shop database iteration. Here we are at the fast food shop, and we know the menu is a crucial part of it, so we have used iterators to access all the menu items easily and fast. We have defined all the classes, appended food items, and then used iterators to access the data.
Class food item :
class Food_Item:
def __init__(self, name, price):
self.name = name
self.price = price
This is our food item class, which defines the property of food items, and here, the properties are name and price. so whenever we want to add any food item, we will have to pass the name of the food and price as an argument. ex - i1 = Food_Item("Burger", 10) ,you can observe we are passing food item anime and its price.
Iterator class:
def _iterator(self):
return Menu_Iterator(self.items)
class Menu_Iterator:
def __init__(self, items):
self.indx = 0
self.items = items
This is our iterator class, which traverses through all available food items. We have used the indexing property, and the iterator will visit each index if it exists. lastly, we will display the values using iterator such as while _iterator.has_next():
item_present = _iterator.next()
print(item_present)
There are limited values in the list, so before every iteration, it checks whether the next value exists; if it exists, then we will increase our index and visit it else, and the iteration will be terminated.
Advantages of iterator design pattern :
- This method creates a custom travel mechanism. It makes traversal through each element easy.
- This method is less time-consuming.
Disadvantages of iterator design pattern :
- The resources might be overused by this method.
- Adding multiple interfaces might complicate the code.