NFA to Regular Expression
What is NFA?
An NFA (Nondeterministic Finite Automata) is a type of automata used in computer science and formal language theory to recognize regular languages. It is similar to a DFA (Deterministic Finite Automaton) in that it is a mathematical model for a machine that can recognize a language. Still, it has some differences in the way it operates.
In an NFA, at any given point during the machine's operation, it can be in one or more states and transition from one state to another based on the input it receives. This nondeterministic behavior means that the same input may lead to different states, or a single state may have multiple possible transitions for the same input.
To accept a string as part of its language, an NFA must reach an accepting state by following a path through its state transitions corresponding to the input string. An NFA can recognize the same set of languages as a DFA but may require more states and transitions.
The NFA is a useful tool for understanding the theory of regular languages and for designing and analyzing regular expressions, which are used in many programming languages and applications to search for patterns in text.
What is Regular Expression
A regular expression, often abbreviated as regex, is a pattern or sequence of characters that specify a search pattern. It matches and manipulates text based on certain rules, such as finding specific character sequences or validating input.
Regular expressions are widely used in computer science and programming, particularly for text search, input validation, and data parsing. They are supported in many programming languages and tools, including Perl, Python, Java, JavaScript, and many others.
A regular expression can include a combination of literals (characters or strings that match themselves) and special characters that represent patterns or classes of characters. For example, the dot (.) character matches any single character, and the asterisk (*) character matches zero or more occurrences of the preceding character or group.
Here's an example of a regular expression that matches any string containing the word "apple":
This regular expression can match the string "I like apples" or "The apple is red" but not "Bananas are my favorite fruit."
Regular expressions can be very powerful and flexible, but they can also be complex and difficult to read and understand. It's important to carefully test and debug regular expressions to ensure they work correctly and efficiently.
NFA to Regular Expression
A Non-Deterministic Finite Automata (NFA) is a type of automata in computer science that recognizes a regular language. A regular language is a language that can be expressed using regular expressions, which are strings of characters that represent a pattern of text.
To convert an NFA to a regular expression; there are a few steps that need to be taken:
1. Convert the NFA to a system of equations: This is done using the state elimination method, which involves creating equations representing the transitions between states in the NFA.
2. Solve the system of equations to obtain a regular expression. This is done by manipulating the equations to eliminate all but one variable and then solving for that variable.
3. Simplify the regular expression: Once the regular expression has been obtained, it may be possible to simplify it using various techniques, such as removing unnecessary parentheses, combining like terms, etc.
The process of converting an NFA to a regular expression can be complex, but it is an important tool in computer science and is used in a variety of applications,
such as pattern matching and text processing. Converting an NFA to a regular
expression, it becomes possible to understand and analyze the language that is recognized by the NFA and to use that knowledge to create more efficient algorithms for working with that language.
Algorithm
The algorithm to convert a Non-Deterministic Finite Automaton (NFA) to a Regular Expression (RE) is called the state elimination method. The basic steps of the algorithm are:
1. Create a new start state and add an epsilon transition to the old start state.
2. Create a new final state and add epsilon transitions from all old final states to the new final state.
3. For each pair of states (excluding the start and final states), create a new state representing the set of all paths between those two states. Add transitions between the new and old states that are represented by paths from one of the old states to the other.
4. Repeat step 3 until only the start, and final states remain. The regular expression representing the language recognized by the original NFA is obtained by concatenating the regular expressions along the paths connecting the start and final states.
To make this algorithm clearer, here's an example:
Suppose we have the following NFA:
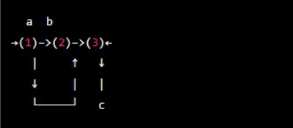
To convert this NFA to a regular expression, we follow the state elimination method:
- Add a new start state, s0, and an epsilon transition to the old start state. Diagram
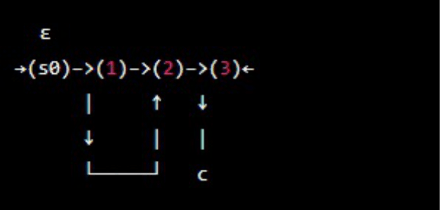
- Add a new final state and f and epsilon transition from all old final states to the new final state.

- Create a new state q12 representing the set of all paths from state 1 to state 2, and add transitions between q12 and the old states represented by paths from state 1 to state 2.

- Create a new state q23 representing the set of all paths from state 2 to state 3, and add transitions between q23 and the old states represented by paths from state 2 to state 3.

- Eliminate the intermediate states q12 and q23 by replacing the transitions between q12 and q23 with the regular expression representing the language recognized by the paths connecting them. In this case, the regular expression is "ABC."