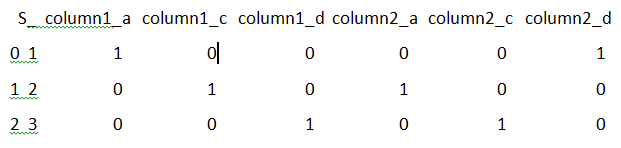get_dummies in Pandas
Pandas :
Pandas is a library in python. It is a open source package in python. Pandas in python are used for data cleaning and data analysis. Data frame mainly consists of data, rows and columns. Pandas package is built on the top of numpy. Pandas is used to handle messy data in an easy manner and it is one of the best tool to handle messy data.
The word pandas is derived from “ panel data “. We can install the python package using the following command that is “ pip install pandas “.
Before the installation of pandas we have to check the version of python. We will store all the data in many formats like CSV , Excel , SQL , etc.
get_dummies :
In pandas get_dummies is a method that is used to manipulate the data in the given category. get_dummies() function is also used to convert categorical data into indicator variables or dummy variables.
Dummy variable is a variable that consists of 0 ‘ s and 1 ‘ s . It is used to encode the categorical values. It also gives equal weightage to the categorical variables. It allows us to encode categorical data easily.
Syntax:
pandas.get_dummies ( data , prefix=None , prefix_sep=’_’ , dummy_na=False , columns=None , sparse=False , drop_first=False , dtype=None )
Parameters :
Data : Data consists of array elements or series of elements or dataframe . We can get dummy variables or dummy indicators for the given data.
Prefix : Prefix mainly consists of string or list of string or dictionary of string or we may have default as none values.
It requires string to append column names of data frame.When we call dummies on a dataframe we need to pass a list with the length that is equal to number of columns in the data frame.
- Prefix_sep : Prefix_sep is a separator or a delimeter that is used to append any prefix. If there is no prefix to add then as default we use ‘ _ ‘ .
- Dummy_na : Dummy_na is used to add a column to indicate whether the value is a NotaNumber (NaN) or not. In default the value is false. If the value is false then the NaN’s are ignored else they are considered.
- Columns : Column is the parameter that needs to be encoded. Column is taken from the column name of the data frame. In default we consider the column value as none. If the columns are none then the columns with object or category datatype will be converted.
- Sparse : It specifies whether the dummy encoded columns are backed by Sparse array that inturn indicates True or may be backed by a Numpy array that indicates False. The default value considered is False.
- Drop_first : We need to remove the first level to get k-1 dummies with k categorical levels.
- Dtype : Dtype is a parameter that is used in dummies as a data typeof new column. Only a single data type can be allowed. The default value of data type in this parameter us np.uint8.
- Returns : It returns the data frame that is encode. It returns dummy coded data.
Example :
Code1 :
Using list we are going to print the dummy values of the data frame.
import pandas as pd
str = pd.Series( list( ‘ abcba ‘ ) )
print( pd . get_dummies (str) )
Output 1 :

Code 2 :
In this code we are using the list with default values of nan as false.
import pandas as pd
import numpy as np
str1 = [ ‘ s ’ , ‘ a ’ , ‘ t ’ , np.nan ]
print ( pd . get_dummies ( str1 ) )
Output :

Here in this example we have declared np.nan but there is no nan column in the output. Because we did not specify any particular value to the nan so by default it takes false so there is no column named nan in the output.
Code 3 :
In this code we are using the list as a data type with the value of nan as true.
import pandas as pd
import numpy as np
str2 = [ ‘ s ’ , ‘ a ’ , ‘ t ’ , np.nan ]
print ( pd . get_dummies ( str2 , dummy_na = True ) )
Output :
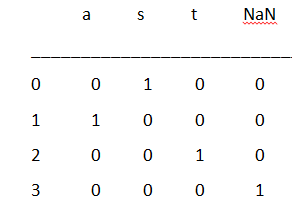
In the above example we have declared np.nan but it has taken the default value as false. We have not specified any particular value to the nan so by default it has taken false and so there was no column named nan in the output.
But here in this example we have declared np.nan but there is nan column in the output.
Because the thing that varies in both the code is in the example 2 it has taken the default value to the nan as false but here in the example 3 we have given a particular input to the nan as true. So that we can see an output of nan in the output of example 3.
Code 4 :
In this code we are using the dictionary as a data type to print the dummy values.
import pandas as pd
import numpy as np
str3 = pd . DataFrame ( { ‘ R ‘ : [ ‘ a ‘ , ‘ c ‘ , ‘ d ‘ ] ,
‘ T ‘ : [ ‘ d ‘ , ‘ a ‘ , ‘ c ‘ ] ,
‘ S_’: [ 1 , 2 , 3 ] } )
print ( pd . get_dummies ( diff . prefix = [ ‘ column1 ‘ , ‘ column2 ‘ ] ) )
Output :