Ways to filter Pandas DataFrame by column values
Pandas DataFrame is a two-layered size-impermanent, possibly heterogeneous, even information structure with marked tomahawks (lines and sections). A Data outline is a two-layered information structure, i.e., information is adjusted in an even design in lines and sections. Pandas DataFrame comprises three head parts, the data, rows, and columns.
Elements of DataFrame
- Possibly sections are of various sorts
- Size - Mutable
- Marked tomahawks (lines and sections)
- Can Perform the Arithmetic procedure on lines and segments
- Fedata: It comprises various structures like ndarray, series, map, constants, records, and exhibit.
- File: The Default np.arrange(n) record is utilized for the column names in the event that no list is passed.
- Columns: The default language structure is np.arrange(n) for the section names. It shows possibly obvious, assuming no file is passed.
- dtype: It alludes to the information kind of every section
- copy(): It is utilized for replicating the information.
Pandas support multiple ways of separating by section esteem; DataFrame.query() strategy is the most used to channel the lines in light of the articulation and returns another DataFrame subsequent to applying the segmented channel. On the off chance that you needed to refresh the current or alluding DataFrame, use inplace=True contention. On the other hand, you can likewise utilize DataFrame[] with loc[] and DataFrame.apply().
Example
import pandas as pd
import numpy as np
technologies= {
'Courses':["C","C++","HTML","Python","Pandas"],
'Fee' :[22000,25000,23000,24000,26000],
'Duration':['30days','50days','30days', None,np.nan],
'Discount':[1000,2300,1000,1200,2500]
}
df = pd.DataFrame(technologies)
print(df)
Output
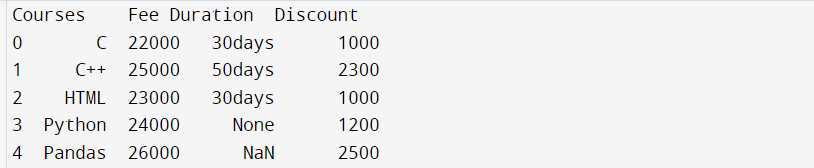
Note: The above DataFrame likewise contains None and Nan values on Duration section that i would use in my models beneath to choose columns that has None and Nan esteems or select overlooking these qualities.
Using a query() to Filter by Column Value in pandas:
DataFrame.query() capability is utilized to channel lines in view of segment esteem in pandas. In the wake of applying the articulation, it returns another DataFrame if you have any desire to refresh the current DataFrame, use the inplace=True param.
Example
df2=df.query("Courses == 'C'")
print(df2)
Output
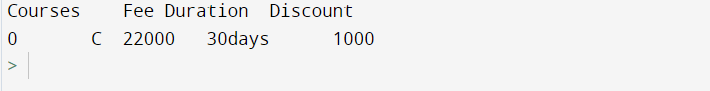
In the event, you need to involve a variable in the articulation, use @ character, as shown in the below:
value='C'
df2=df.query("Courses == @value")
print(df2)
On the off chance that you notice the above models return another DataFrame subsequent to separating the columns. If you have any desire to refresh the current DataFrame, use inplace=True.
df.query("Courses == 'C'",inplace=True)
print(df)
If you had any desire to choose in light of section esteem not approaches then, at that point, use != operator.
Example
# not equals condition
df2=df.query("Courses != 'C'")
Output
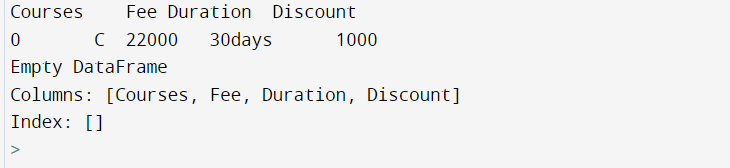
Filtering Rows Based on List of Column Values
On the off chance that you have values in a python list and need to choose the lines in light of the rundown of values, use an administrator.
Example
# Filter Rows by list of values
print(df.query("Courses in ('C','C++')"))
Output:
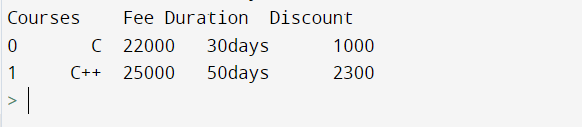
You can likewise make a rundown of values and use it as a python variable.
# Filter Rows by list of values
values=['C','C++']
print(df.query("Courses in @values"))
Utilize not an administrator to choose lines that are not in that frame of mind of segment values.
# Filter Rows not in list of values
values=['C','C++']
print(df.query("Courses not in @values"))
Assuming you have segment names with extraordinary characters utilizing section name encompassed by tick ' character .
# Using columns with special characters
print(df.query("`Courses Fee` >= 23000"))
pandas Filter by Multiple Columns
In pandas or any table-like designs, more often than not we would have to channel the lines in light of different circumstances by utilizing numerous sections, you can do that in Pandas DataFrame as underneath.
# Filter by multiple conditions
print(df.query("`Courses Fee` >= 23000 and `Courses Fee` <= 24000"))
Using DataFrame.apply() & Lambda Function:
pandas.DataFrame.apply() technique is utilized to apply the articulation line by column and return the lines that matched the qualities.
# By using lambda function
print(df.apply(lambda row: row[df['Courses'].isin(['C','C++'])]))
Output:
Filter Rows with Nan using dropna() Method
On the off chance that you needed to channel and disregard pushes that have None or nan on section values, use DataFrame.dropna() strategy.
# filter rows by ignoring columns that have None & Nan values
print(df.dropna())
Output:

In the event that you needed to drop sections when segment values are None or nan. To erase segments, I take care of certain models on the best way to drop Pandas DataFrame sections.
Example
# Filter all column that have None or NaN
print(df.dropna(axis='columns'))
Output

Using DataFrame.loc[] and df[]
Some other examples you can try to filter rows
df[df["Courses"] == 'C']
df.loc[df['Courses'] == value]
df.loc[df['Courses'] != 'C']
df.loc[df['Courses'].isin(values)]
df.loc[~df['Courses'].isin(values)]
df.loc[(df['Discount'] >= 1000) & (df['Discount'] <= 2000)]
df.loc[(df['Discount'] >= 1200) & (df['Fee'] >= 23000 )]
# Select based on value contains
print(df[df['Courses'].str.contains("C")])
# Select after converting values
print(df[df['Courses'].str.lower().str.contains("C")])
#Select startswith
print(df[df['Courses'].str.startswith("P")])