Python | Pandas Dataframe.to_dict()
Pandas in Python: Pandas is an open-source library made primarily for working with social or marked information both effectively and instinctively. It gives different information designs and activities for controlling mathematical information and time series. This library is based on top of the NumPy library. Pandas is quick, and it has superior execution and efficiency for clients. Pandas simplify it to do a significant number of the tedious, redundant errands related to working with information, including:
- Data cleansing
- Data fill
- Data normalization
- Merges and joins
- Data visualization
- Statistical analysis
- Data inspection
- Loading and saving data
Benefits
- Simple treatment of missing information (addressed as NaN) in drifting point as well as non-drifting point information
- Size impermanence: segments can be embedded and erased from DataFrame and higher layered objects
- Informational index blending and joining.
- Adaptable reshaping and turning of informational indexes
- Gives time-series usefulness.
- Strong gathering by usefulness for performing the split-apply-consolidate procedure on informational indexes.
Python is an excellent language for doing information research, owing to the fantastic biological system of information-driven Python packages. Pandas is one of those packages, and it makes importing and analyzing data much easier. Pandas .to_dic() strategy is utilized to change over a dataframe into a word reference of series or rundown-like information type contingent upon a situate boundary.
Syntax
DataFrame.to_dic(orient='dic', into=<class 'dic'>)
The kind of the key-esteem matches can be tweaked with the boundaries
Parameters:
Orient : str {‘dic’, ‘list’, ‘series’, ‘split’, ‘records’, ‘index’}
Determines the type of the values of the dicionary.
- ‘dic’ (default) : dic like {column -> {index -> value}}
- ‘list’ : dic like {column -> [values]}
- ‘series’ : dic like {column -> Series(values)}
- ‘split’ : dic like {‘index’ -> [index], ‘columns’ -> [columns], ‘data’ -> [values]}
- ‘tight’ : dic like {‘index’ -> [index], ‘columns’ -> [columns], ‘data’ -> [values], ‘index_names’ -> [index.names], ‘column_names’ -> [column.names]}
- ‘records’ : list like [{column -> value}, … , {column -> value}]
- ‘index’ : dic like {index -> {column -> value}}
Note: s indicates series and sp indicates split.
into : class, default dic
The collections.abc.Mapping subclass utilized for all Mappings in the bring esteem back. Can be the genuine class or an unfilled occasion of the planning type you need. On the off chance that you need a collections.defaultdic, you should pass it instated.
Return type: Dataframe converted into Dicionary
- Using the DataFrame occurrence method to dic, a pandas DataFrame may be converted into a Python word reference (). Using the boundary arrangement, the outcome may be indicated in a variety of directions.
- In dictionary orientation, the section esteem is stored against the line name in a word reference for each segment of the DataFrame. This high number of word references is surrounded by another word reference, which is documented with section marks. For the boundary position, the string strict "dic" indicates the word reference direction. The word reference direction is the change yield's default direction.
- In list orientation, each section is converted to a rundown, and the rundowns are appended to a word reference against the segment names. For the boundary arrangement, the string strict "list" indicates the list direction.
- In series orientation, each segment is converted to a pandas Series, and the series examples are listed in the returned word reference object against the line marks. For the boundary position, the string stringent "series" indicates the series direction.
- In split orientation, each line is transformed into a rundown, which is then surrounded by another rundown and recorded with the key "information" in the returned word reference object. The column names are saved in a list against the key "record." The section markers are saved in a rundown next to the main "segments." The string strict "split" for the border arrangement determines the part direction.
- Each section is given a word reference in records orientation, and the segment components are kept next to the segment name. Each and every word reference is returned as a list. The string parameter "records" for the boundary arrangement defines the direction of the records.
- Each segment is given a word reference in index orientation, with the section components stored next to the section name. Each word reference is returned as a word reference organized alphabetically by a line name. The string exacting "list" is used to indicate the record direction for the boundary situation.
Example of Convert DataFrame to Dicionary
# Use DataFrame.to_dic() to convert DataFrame to dicionary
dic = d.to_dic()
# Use dic as orient
dic = d.to_dic('dic')
# Convert DataFrame to dicionary using dic() and zip() methods
dic = dic([(i,[x,y,z ]) for i, x,y,z in zip(d.Courses, d.Fee,d.Duration,d.Discount)])
# Using dic() and zip() methods
dic=dic([(i,[x,y,z]) for i,x,y,z in zip(d['Courses'], d['fee'],d['Duration'],d['Discount'])])
Presently, we should make a DataFrame with a couple of lines and segments, execute these models and approve results. Our DataFrame contains segment names Courses, Fee, Duration, and Discount.
import pandas as pd
technologies = [
("java", 10000,'60days',1200.0),
("c++",25000,'40days',2000.0),
("HTML",3000,'20days',1500.0)
]
d = pd.DataFrame(technologies,columns = ['Courses','Fee','Duration','Discount'])
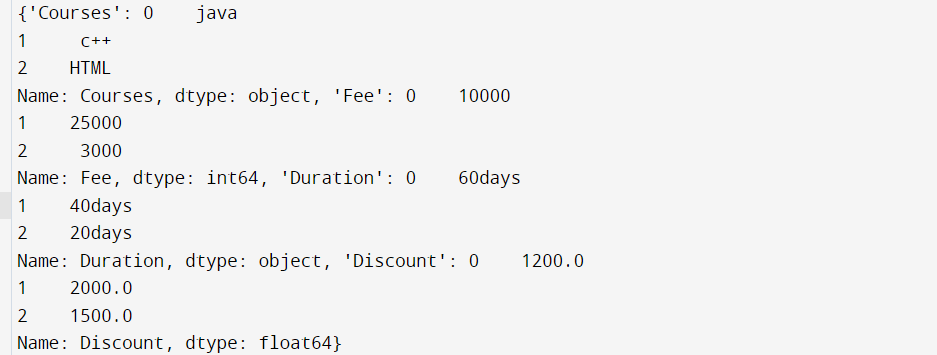
print(d)
Output
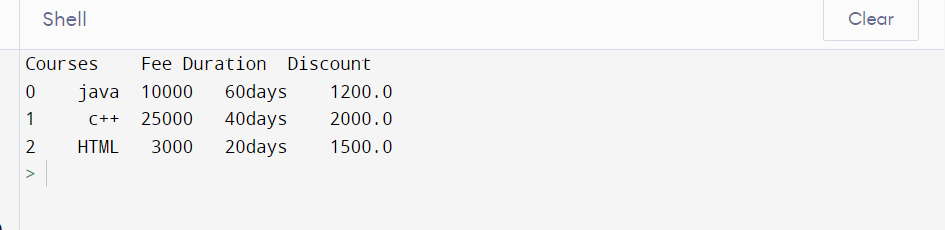
Use DataFrame.to_dic() to Convert DataFrame to Dicionary:
To change pandas DataFrame over completely to Dicionary object, use to_dic() technique, this accepts arrange as dic naturally which returns the DataFrame in design {column - > {index - > value}}. At the point when no situate is determined, to_dic() returns in this configuration
# Use DataFrame.to_dic() to convert DataFrame to dicionary
dic = d.to_dic()
print(dic)
# Using orient as dic
dic = d.to_dic('dic')
print(dic)
Output
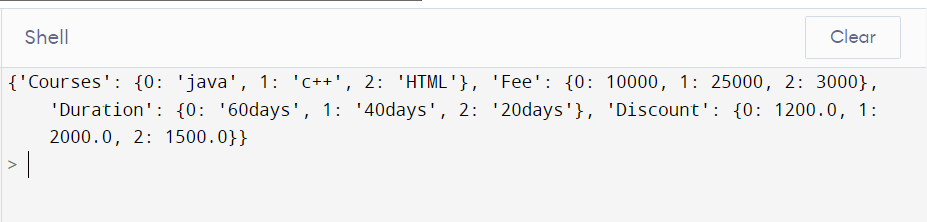
Converting DataFrame to Dicionary With Column as Key
list situate - Each section is changed over completely to a rundown and the rundowns are added to a word reference as values to segment marks. To get the dic in design {column - > [values]}, determine with the string exacting "list" for the boundary arrange.
dic = d.to_dic('list')
print(dic )
Output
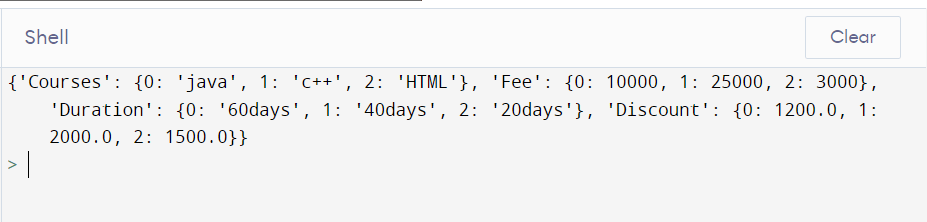
Converting DataFrame to Dicionary of Series
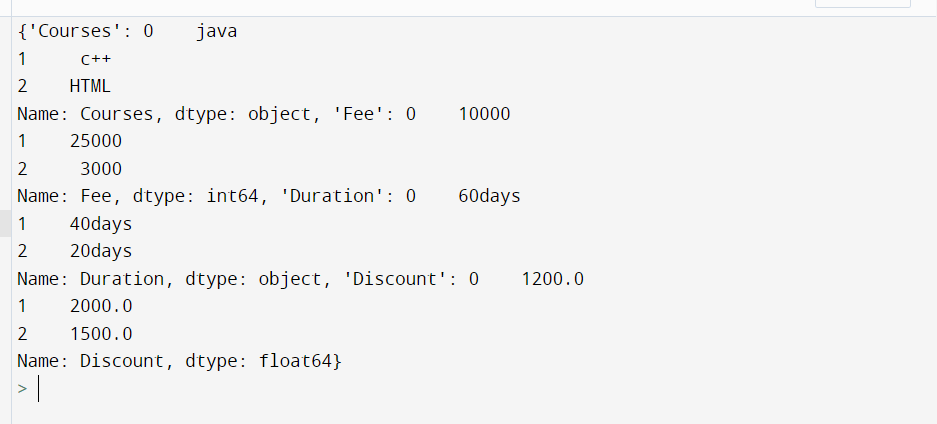
series situate - Each segment is switched over completely to a pandas Series, and the series are addressed as values. To get the dic in design {column - > Series(values)}, determine with the string strict "series" for the boundary situate.
d2 = d.to_dic('series')
print(d2)
Output
Converting DataFrame to Dicionary of Split
split orient - Each column is changed over completely to a rundown and they are enclosed by one more rundown and recorded with the key "information". To get the dic in design {'index' - > [index], 'sections' - > [columns], 'information' - > [values]}, determine with the string exacting "split" for the boundary arrange.
d2 = d.to_dic('split')
print(d2)
Output

Convert DataFrame to Dicionary of Records
records situate - Each segment is changed over completely to a word reference where the section name as key and section an incentive for each column is a worth. To get the rundown like configuration [{column - > value}, … , {column - > value}], determine with the string exacting "records" for the boundary arrange.
d2 = d.to_dic('records')
print(d2)
Output

Converting DataFrame to Dicionary by Index
index orient - Each section is switched over completely to a word reference where the segment components are put away against the section name. To get the dic in design {index - > {column - > value}}, determine with the string strict "file" for the boundary situate.
d2 = d.to_dic('index')
print(d2)
Output

Converting DataFrame to Dicionary Using dic() and zip() Methods
# Convert DataFrame to dicionary using dic() and zip() methods
d2 = dic([(i,[x,y,z ]) for i, x,y,z in zip(d.Courses, d.Fee,d.Duration,d.Discount)])
print(d2)
# Using dic() and zip() methods
d2 = dic([(i,[x,y,z]) for i,x,y,z in zip(d['Courses'], d['Fee'],d['Duration'],d['Discount'])])
print(d2)
Output

Example For Converting DataFrame to Dicionary
import pandas as pd
technologies = [
("java", 10000,'60days',1200.0),
("c++",25000,'40days',2000.0),
("HTML",3000,'20days',1500.0)
]
d = pd.DataFrame(technologies,columns = ['Courses','Fee','Duration','Discount'])
print(d)
# Use DataFrame.to_dic() to convert DataFrame to dicionary
dic = d.to_dic()
print(dic )
# Use dic orient
dic = d.to_dic('dic')
print(dic )
# Use list orient
dic = d.set_index('Courses').T.to_dic('list')
print(dic )
# Use series orient
dic = d.to_dic('series')
print(dic )
# Use split orient
dic = d.to_dic('split')
print(dic )
# Use list orient
dic = d.to_dic('list')
print(dic )
# Use records orient
dic = d.to_dic('records')
print(dic )
# Use index orient
dic = d.to_dic('index')
print(dic )
# Convert DataFrame to dicionary using dic() and zip() methods
dic = dic([(i,[x,y,z ]) for i, x,y,z in zip(d.Courses, d.Fee,d.Duration,d.Discount)])
print(dic )
# Using dic() and zip() methods
dic = dic([(i,[x,y,z]) for i,x,y,z in zip(d['Courses'], d['Fee'],d['Duration'],d['Discount'])])
print(dic )
Output