Pandas Read JSON
Pandas is one of the most generally involved Python libraries for information dealing with and perception. The Pandas library gives classes and functionalities that can be utilized to productively peruse, control and picture information and put away in an assortment of document designs.
JavaScript Object Notation (JSON) is an information design that stores information in a comprehensible structure. While it very well may be, in fact, utilized for stockpiling, JSON records are essentially utilized for serialization and data trade between a client and server.
Despite the fact that it was gotten from JavaScript, its foundation is rationalist and is a broadly spread and utilized design - most commonly in REST APIs.
Pandas in Python
Pandas is an open-source Python bundle that is generally utilized for information science/information investigation and AI undertakings. Pandas is a Python open-source toolkit that allows high-performance data manipulation. Pandas is derived from the word Panel Data, which stands for Econometrics from Multidimensional Data. It was created in 2008 by Wes McKinney and is used for data analysis in Python. It is based on top of another bundle named Numpy, which offers help for multi-layered exhibits. Pandas simplify it to do a significant number of the tedious, redundant errands related to working with information, including:
- Data cleansing
- Data fill
- Data normalization
- Merges and joins
- Data visualization
- Statistical analysis
- Data inspection
- Loading and saving data
And much more, truth be told, with Pandas, you can do all that makes world-driving information researchers vote Pandas as the best information investigation and control apparatus that anyone could hope to find.
Panda Characteristics
- It includes a speedy and efficient DataFrame object with default and customized ordering.
- Utilized for reshaping and turning the informational indexes.
- Bunch by information for accumulations and changes.
- It is utilized for information arrangement and a combination of the missing information.
- Give the usefulness of Time Series.
- Process different types of informative collections in distinct organizations, such as lattice information and heterogeneous time series.
- Handle various informative collecting activities such as subsetting, cutting, separating, groupBy, re-requesting, and moulding.
- It collaborates with other libraries like as SciPy and Scikit-learn.
Creating JSON Data by means of Nested Dictionaries
In Python, to make JSON information, you can utilize settled word references. Everything inside the external word reference relates to a segment in the JSON document.
patients = {
"Name":{"0":"John","1":"Nick","2":"Ali","3":"Joseph"},
"Gender":{"0":"Male","1":"Male","2":"Female","3":"Male"},
"Nationality":{"0":"UK","1":"French","2":"USA","3":"Brazil"},
"Age" :{"0":10,"1":25,"2":35,"3":29}
}
Using Lists of Dictionaries to Generate JSON Data
Another way to generate JSON data is by using a list of word references. Everything in the rundown comprises a word reference, and every word reference addresses a line. This approach is significantly more comprehensible than utilizing settled word references. We should make a rundown that can be utilized to make a JSON document that stores data about various vehicles:
cars = [
{"Name":"Honda", "Price": 10000, "Model":2005, "Power": 1300},
{"Name":"Toyota", "Price": 12000, "Model":2010, "Power": 1600},
{"Name":"Audi", "Price": 25000, "Model":2017, "Power": 1800},
{"Name":"Ford", "Price": 28000, "Model":2009, "Power": 1200},
]
Python Data Composition to JSON File
With our settled word reference and a rundown of word references, we can store this information in a JSON document. To accomplish this, we'll utilize the json module and the landfill() technique:
import json
with open('E:/datasets/patients.json', 'w') as v:
json.dump(patients, v)
with open('E:/datasets/cars.json', 'w') as v:
json.dump(cars, v)
Reading JSON Files with Pandas
To peruse a JSON record through Pandas, we'll use the read_json() technique and pass it the way to the document we might want to peruse. The technique returns a Pandas DataFrame that stores information as segments and columns. However, first, we'll need to introduce Pandas:
$ pip install pandas
Reading JSON from Local Files
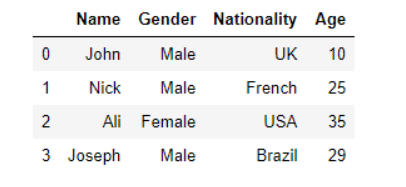
The accompanying content peruses the patients.json record from a nearby framework catalogue and stores the outcome in the patients_df dataframe. The header of the dataframe is then printed by means of the head() technique:
import pandas as pd
patients_df = pd.read_json('E:/datasets/patients.json')
patients_df.head()Output
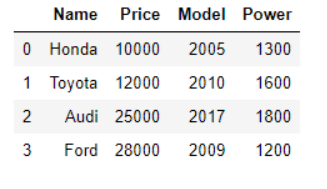
Likewise, the accompanying content peruses the cars.json record from the nearby framework and afterwards calls the head() strategy on the cars_df to print the header:
cars_df = pd.read_json('E:/datasets/cars.json')
cars_df.head()
Output
Composing JSON Data Files through Pandas
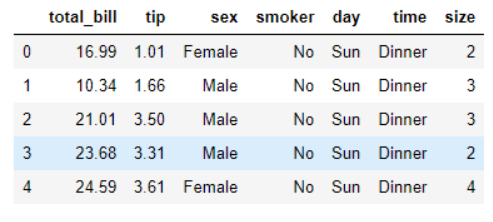
To change over a Pandas dataframe to a JSON record, we utilize the to_json() capability on the dataframe and pass the way to the prospective document as a boundary. We should make a JSON record from the tips dataset, which is remembered for the Seaborn library for information perception. Most importantly, how about we introduce Seaborn:
$ pip install seaborn
import seaborn as sns
dataset = sns.load_dataset('tips')
dataset.head()
Output
Seaborn's load_dataset() capability returns a Pandas DataFrame, so stacking the dataset like this permits us to just call the to_json() capability to change over it. Whenever we've gotten tightly to the dataset, we should save its substance in a JSON document. We've set up the index of a dataset for this:
dataset.to_json('E:/datasets/tips.json')
Exploring the E:/datasets catalogue, you ought to see tips.json. Opening the document, we can see JSON that compares to records in the Pandas dataframe containing the tips dataset:
{
"total_bill":{
"0":16.99,
"1":10.34,
"2":21.01,
"3":23.68,
"4":24.59,
"5":25.29,
...
}
"tip":{
"0":1.01,
"1":1.66,
"2":3.5,
"3":3.31,
"4":3.61,
"5":4.71,
...
}
"sex":{
"0":"Female",
"1":"Male",
"2":"Male",
"3":"Male",
"4":"Female",
"5":"Male",
...
}
"smoker":{
"0":"No",
"1":"No",
"2":"No",
"3":"No",
"4":"No",
"5":"No",
...
}
...