Python Pandas Not Null
Pandas is an open-source Python bundle that is broadly utilized for information science, information investigation and AI undertakings. Pandas is a Python open-source toolkit that allows high-performance data manipulation. Pandas get its name from the term Panel Data, which means Econometrics from Multidimensional data.
It was created in 2008 by Wes McKinney and is used for data analysis in Python. It is based on top of another bundle named Numpy, which offers help for multi-layered exhibits.
Pandas simplify it to do a significant number of the tedious, redundant errands related to working with information, including:
- Data cleansing
- Data fill
- Data normalization
- Merges and joins
- Data visualization
- Statistical analysis
- Data inspection
- Loading and saving data
With Pandas, you can do all that makes world-driving information researchers vote Pandas as the best information investigation and control apparatus that anyone could hope to find.
Key Features of Pandas
- It has a quick and effective DataFrame object with the default and tweaked ordering.
- Utilized for reshaping and turning of the informational indexes.
- Bunch by information for accumulations and changes.
- It is utilized for information arrangement and combination of the missing information.
- Give the usefulness of Time Series.
- Process different types of informative collections in distinct organisations, such as lattice information and heterogeneous time series.
- Handle various informative collecting activities such as subsetting, cutting, separating, groupBy, re-requesting, and moulding.
- It collaborates with other libraries like as SciPy and Scikit-learn.
- Provides rapid execution, and if you need to speed it up even more, you may use Cython.
.notnull is a general capability of the pandas library in Python that recognizes in the event that values are not missing for either a solitary worth (scalar) or cluster like items. The capability returns booleans to reflect whether the qualities assessed are invalid (False) or not invalid (True). .notnull is a nom de plume of the pandas .
Python is an amazing language for doing information research, owing to the phenomenal biological system of information-driven python packages. Pandas is one of those packages that makes taking in and breaking down data much easier.
Pandas dataframe.notnull() capability recognizes existing/non-missing qualities in the dataframe. The capability returns a boolean item having the very size as that of the article on which it is applied, demonstrating regardless of whether every individual worth is a na esteem. Each of the non-missing qualities gets planned to valid and missing qualities get planned to misleading.
Pandas DataFrame is a two-layered, size-independent, possibly heterogeneous information structure with indicated tomahawks (lines and sections). A data outline is a two-layered information structure in which information is organised in lines and parts. Pandas DataFrame is made up of three main components: information, lines, and segments.
Syntax
DataFrame.notnull()
Returns: Mask of bool values for every component in DataFrame that demonstrates whether a component isn't a NA esteem.
Example
import numpy as np
import pandas as pd
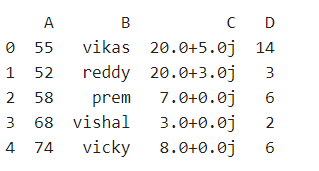
df = pd.DataFrame({"A":[55,52,58,68,74],
"B":["vikas", "reddy", "prem", "vishal", "vicky"],
"C":[20 + 5j, 20 + 3j, 7, 3, 8],
"D":[14, 3, 6, 2, 6]})
# Print the dataframe
print(df)
Output
How about the utilization of dataframe.notnull() capability to track down every one of the non-missing qualities in the dataframe.
Example
import numpy as np
import pandas as pd
df = pd.DataFrame({"A":[55,52,58,68,74],
"B":["vikas", "reddy", "prem", "vishal", "vicky"],
"C":[20 + 5j, 20 + 3j, 7, 3, 8],
"D":[14, 3, 6, 2, 6]})
print(df.notnull())
Output

Example
import numpy as np
import pandas as pd
df = pd.DataFrame({"A":[55,52,None,68,74],
"B":["vikas", "reddy", "prem", "vishal", "vicky"],
"C":[20 + 5j,None , 7, 3, 8],
"D":[14,None , 6, None, 6]})
print(df)
Output

Example
import numpy as np
import pandas as pd
df = pd.DataFrame({"A":[55,52,None,68,74],
"B":["vikas", "reddy", "prem", "vishal", "vicky"],
"C":[20 + 5j,None , 7, 3, 8],
"D":[14,None , 6, None, 6]})
print(df.notnull())
Output

The following code sample demonstrates how to utilise Pandas' notnull function:
import pandas as pd
import numpy as np
# notnull function on Series
ser = pd.Series([5, 6, np.NaN])
print("Original series")
print(ser)
print('\n')
print("Non-null Values")
print(ser.notnull())
print('\n')
# notnull function on Dataframe
df = pd.DataFrame(dict(age=[5, 6, np.NaN],
born=[pd.NaT, pd.Timestamp('1939-05-27'),
pd.Timestamp('1940-04-25')],
name=['Alfred', 'Batman', ''],
toy=[None, 'Batmobile', 'Joker']))
print("Original dataframe")
print(df)
print('\n')
print("Non-null Values")
print(df.notnull())
print('\n')
Output:
