Information Retrieval
Information Retrieval: In order to analyze and categorize the text, we'd like to be able to figure out information about the text, some meaning about the text as well. And, to be able to take data in the text form and retrieve information from it, this task is known as the Information Retrieval system.
Then, we need to be able to take documents and figure out what are topics of the particular document so that information can be retrieved more effectively from those set of documents. This is known as Topic Modeling.
Then, the AI system should be able to tell how many times a particular term is used in the document. So, for this one instinctive idea that makes sense is Term Frequency. For example, if in a document of 100 words, a particular word is repeated 10 times, then its term frequency is 10, and maybe it's an important word. So, this idea is really helpful in Information Retrieval.
Let’s see the program to find out the most frequent words in the different documents in the "Sherlock Holmes" corpus.
Python code:
import math
import nltk
import os
import sys
def main():
"""Calculate top term frequencies for a corpus of documents."""
if len(sys.argv) != 2:
sys.exit("Usage: python tfidf.py corpus")
print("Loading data...")
corpus = load_data(sys.argv[1])
# Get all words in corpus
print("Extracting words from corpus...")
words = set()
for filename in corpus:
words.update(corpus[filename])
# Calculate Term Frequencies
print("Calculating term frequencies...")
tfidfs = dict()
for filename in corpus:
tfidfs[filename] = []
for word in corpus[filename]:
tf = corpus[filename][word]
tfidfs[filename].append((word, tf))
# Sort and get top 5 term frequencies for each file
print("Computing top terms...")
for filename in corpus:
tfidfs[filename].sort(key=lambda tfidf: tfidf[1], reverse=True)
tfidfs[filename] = tfidfs[filename][:5]
# Print results
print()
for filename in corpus:
print(filename)
for term, score in tfidfs[filename]:
print(f" {term}: {score:.4f}")
def load_data(directory):
files = dict()
for filename in os.listdir(directory):
with open(os.path.join(directory, filename)) as f:
# Extract words
contents = [ word.lower() for word in nltk.word_tokenize(f.read())
if word.isalpha() ]
# Count frequencies
frequencies = dict()
for word in contents:
if word not in frequencies:
frequencies[word] = 1
else:
frequencies[word] += 1
files[filename] = frequencies
return files
if __name__ == "__main__":
main()
Output
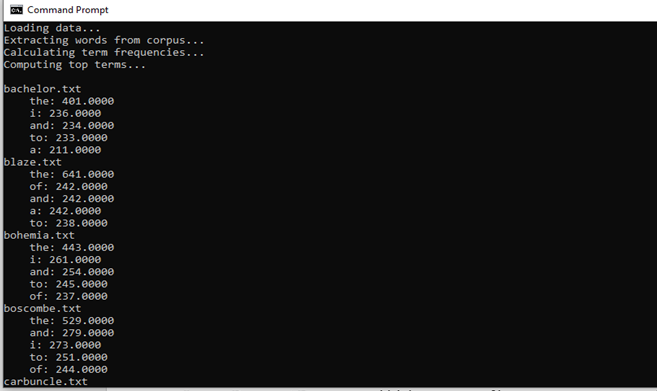
In the above output, we can see that the most frequent words are the function words like 'the,' 'by,' 'and.'
This result is not useful to us as we have used term frequencies, which shows the most frequent words used in the document, and English language function words are used most frequently as they are part of the grammatical structure of a language.
So, to solve this problem, we can categorize the words into different categories like:
Function Words: Words that are used to make the sentence grammatically correct. They don't have their proper meaning. But they become meaningful when combined with other words in a sentence. Example- am, by, is, do, etc.
Content Words: Words that have their meaning. Example: Algorithm, Category, computer, etc.
And, we need the most frequent content words instead of function words in our result to be able to draw some conclusion.
One approach we can use is that we can ignore all the function words, and for that, we will first load the function word text file in our code, which will contain the list of all the function words and define the condition to skip all the function words. Below is the Python Code for this:
def load_data(directory):
# Loaded the function text file
with open("function_words.txt") as f:
function_words = set(f.read().splitlines())
files = dict()
for filename in os.listdir(directory):
with open(os.path.join(directory, filename)) as f:
# Extract words
contents = [
word.lower() for word in
nltk.word_tokenize(f.read())
if word.isalpha()
]
# Count frequencies
frequencies = dict()
for word in contents:
# Added one more condition to skip any function word
if word in function_words:
continue
elif word not in frequencies:
frequencies[word] = 1
else:
frequencies[word] += 1
files[filename] = frequencies
return files
Changes are made in only load data function where function words text file is read and saved in the variable named as function_words, and while counting the frequencies, one more condition to skip the function words is added, and rest program remains same as before.
Now the output of the above code is:
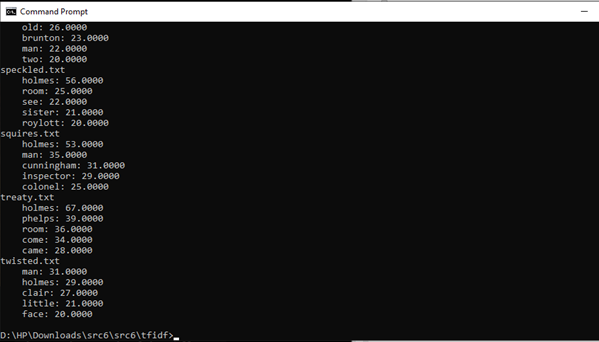
Now in the above output, we can see words except function words in the documents which are most frequent are shown in this document. We can see 'Holmes' in the most frequent words, and it is not meant to say that this story is about Sherlock Holmes, as we already know this. So, we need to extract more meaningful words.
Inverse Document Frequency
Inverse Document Frequency is the approach to find the rarest Word in the document. It is the measure of the rarest Word in the entire corpus of words. And, mathematically it is represented as:

For Example: If we take the word "Holmes."
And we can see in the above example that 'Holmes' appears in all the documents so, the total documents and Number of documents containing the Word are the same so, it will be
Log (1) =0
We will obtain the Inverse Document Frequency of 0. And if any word doesn't show up in any other documents, the Log value is going to much higher.
tf-idf
It is the approach to find out the important words in the document by multiplying Inverse Document Frequency and Term Frequency together. So, the importance of any word in the document depends on two things, which are first how frequently the Word is used in a document and second how rare the Word is in a document.
Now let us apply this algorithm to the 'Sherlock Holmes' corpus.
Python Code:
import nltk
import os
import sys
def main():
"""Calculate top TF-IDF for a corpus of documents."""
if len(sys.argv) != 2:
sys.exit("Usage: python tfidf.py corpus")
print("Loading data...")
# Get all words in corpus
print("Extracting words from corpus...")
words = set()
for filename in corpus:
words.update(corpus[filename])
# Calculate IDFs
print("Calculating inverse document frequencies...")
idfs = dict()
for word in words:
f = sum(word in corpus[filename] for filename in corpus)
idf = math.log(len(corpus) / f)
idfs[word] = idf
# Calculate TF-IDFs
print("Calculating frequencies...")
tfidfs = dict()
for filename in corpus:
tfidfs[filename] = []
for word in corpus[filename]:
tf = corpus[filename][word]
tfidfs[filename].append((word, tf * idfs[word]))
#tf and tfids are multiplied in the above line.
# Sort and get top 5 TF-IDFs for each file
print("Computing top terms...")
for filename in corpus:
tfidfs[filename].sort(key=lambda tfidf: tfidf[1], reverse=True)
tfidfs[filename] = tfidfs[filename][:5]
# Print results
print()
for filename in corpus:
print(filename)
for term, score in tfidfs[filename]:
print(f" {term}: {score:.4f}")
def load_data(directory):
files = dict()
for filename in os.listdir(directory):
with open(os.path.join(directory, filename)) as f:
# Extract words
contents = [
word.lower() for word in
nltk.word_tokenize(f.read())
if word.isalpha()
]
# Count frequencies
frequencies = dict()
for word in contents:
if word not in frequencies:
frequencies[word] = 1
else:
frequencies[word] += 1
files[filename] = frequencies
return files
if __name__ == "__main__":
main()
We calculated the idf (inverse document frequency) first and then multiplied it with tf (term frequency) and repeated all the steps like in the above programs.
Output:
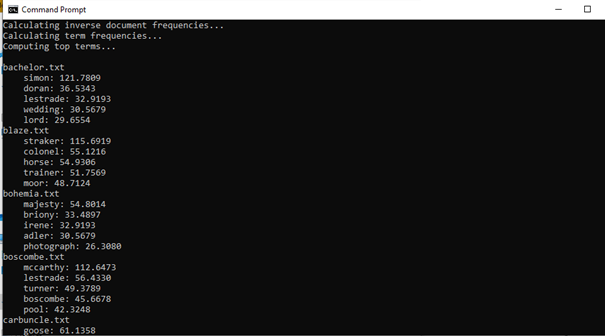
In the above output, we can see the most frequent words in all the documents are different, and now we can see all the important words in every document, which somehow gives the information. This approach is better for any analysis.
Information Extraction
When we get into the world of semantics, we focus on the meaning of the words instead of the order and how these words relate to each other, in particular how we can extract information out of that text, which is called Information Extraction.
Here, we need our AI to look at the text document and figure out and extract the useful information from the text
For example, we have two paragraphs from different articles:
“When Facebook was founded in 2004, it began with a seemingly innocuous mission: to connect friends. Some seven years and 800 million users later the social network has taken over most aspects of our personal and professional lives, and is fast becoming the dominant communication platform of the future."
“Remember, back when Amazon was founded in 1994, most people thought, his idea to sell books over this thing called the internet was crazy. A lot of people had never even heard of the internet."
These two paragraphs are from different articles, and we might want our AI system capable of extracting information from these paragraphs like our system should know When Facebook was founded? When was Amazon founded?
WordNet
If we want our AI system to be able to communicate properly, then it should have definitions and meaning of all the words, or say it should understand everything, then only it would be able to perform efficiently.
So, nltk has a famous dataset called WordNet, which contains the definitions of all the words. Researchers have curated this dataset together, which contains the meaning of all the words and also different senses of the words as different words can have different meanings and also how those words are related to one another.
WordNet comes built into nltk. It can be downloaded using the following commands:
import nltk
nltk.download('wordnet')
Python Code:
from nltk.corpus import wordnet
word = input("Word: ")
synsets = wordnet.synsets(word)
for synset in synsets:
print()
print(f"{synset.name()}: {synset.definition()}")
for hypernym in synset.hypernyms():
print(f" {hypernym.name()}")
Output:
For Example, Word entered is "India."

Here, in the above output, we can see the country has five different senses according to the WordNet. And it is a kind of dictionary where each sense is associated with its definition provided by a human.
And, also it contains the categories, for example, "the country is the type of administrative district," and Country is a type of geographical area," so these categories allow the system to related one Word to the other words. One of the powers of WordNet is to take one Word and connect it to other related words.
This type of approach is efficient in the case of relating one Word to another. But, it's not efficient when different languages are involved and all the various relationships that words might have to one another.
Word Representation
Word representation is a way to represent the meaning of a word so that and AI can understand and extract meaningful information and perform different functions. And every time an AI system is required to represent something; it is done using numbers.
For example, we can represent the results in a game like winning, losing, or draw, as a number (1, negative 1, or a zero). And, we can take data and turn it into the vectors of features, where a bunch of numbers represents some particular data. For instance, we have to give any sentence as an input to any neural network to translate it into another form. So for that, we will need to represent those words in terms of vectors, which is a way to represent the Word by some individual numbers to define the meaning of the Word.
One way to do that is, for example: "He wrote a book."
[1, 0, 0, 0] (he)
[0, 1, 0, 0] (wrote)
[0, 0, 1, 0] (a)
[0, 0, 0, 1] (book)
This is known as One-Hot Representation or One-Hot Encoding, and the location of the 1 tells the meaning of the Word. Like in the above example, 1 in the first position means 'he' 1 in the second position means 'wrote,' and so on. And every word in the dictionary is assigned similarly i.e., 1 at a particular position in the vector and 0 on the other position. Like this, we can have different representations for different words.
The drawback of One-Hot-Encoding techniques are:
- Not suitable for large dictionaries.
- As the number of words increases in the dictionary, vectors get enormously long, which is not a practical way to represent numbers.
- Suppose we have two sentences:
"He wrote a book."
"He authored a novel."
According to the One-Hot Representation, vector representations of all the words will be completely different.
wrote [0, 1, 0, 0, 0, 0]
authored [0, 0, 0, 0, 1, 0]
book [1, 0, 0, 0, 0, 0]
novel [0, 0, 0, 0, 0, 1]
But, the meaning of the sentences wrote and authored should have slightly similar vector representations as they have a similar meaning.
To overcome this limitation of One-Hot Representation, Distributed Representation is used in which the meaning of the Word is represented by different values, not by just 1's and 0's. For example
“He wrote a book”
[-0.34, -0.08, 0.02, -0.18, …] (he)
[-0.27, 0.40, 0.00, -0.65, …] (wrote)
[-0.12, -0.25, 0.29, -0.09, …] (a)
[-0.23, -0.16, -0.05, -0.57, …] (book)
So, after using distributed representation, two similar words can have vector representations that are pretty close to each other. The goal of statistical machine learning is going to be using these vector representations of words.
Now, the question arises of how we can figure out these values of vector representation. This can be done by using the algorithm called word2vec
word2vec
The basic idea of this algorithm is to define a word in terms of the words that are around it. Suppose we have,
| For | he | ate |
Now we have to figure out what goes in the blank. So, breakfast, lunch, dinner are the kinds of words that can be filled in the blank. So if we have to define what does lunch or dinner means, we can define it according to the words that are around it. So, if two words have a similar context or say similar words around it, then it may mean that both the words have a similar meaning. So, this is the foundational idea of this Algorithm.
When we give word2vec a corpus of documents, then it will produce vectors for each Word. And there are various ways to do this, like skip-gram architecture, which uses a neural network to predict the context words given a target word.
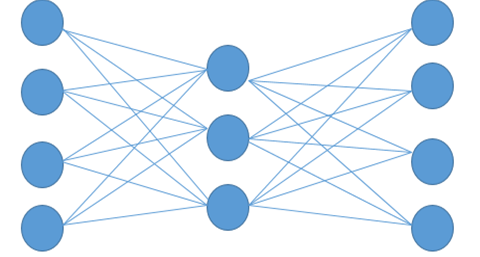
By using the neural network, we can predict what words might show up around any particular word. Suppose we have a big neural network like the one shown below, where one input word represents one Word, and the neural network predicts the context word for a particular target word.
If we give AI the data of what words show up in context, then we can train a neural network to perform all the calculations and to predict a context word for a given target word.
For example,
City: [-0.226776 -0.155999 -0.048995 -0.569774 0.053220 0.124401 -0.091108 -0.606255 -0.114630 0.473384 0.061061 0.551323 -0.245151 -0.014248 -0.210003 0.316162 0.340426 0.232053 0.386477 -0.025104 -0.024492 0.342590 0.205586 -0.554390 -0.037832 -0.212766 -0.048781 -0.088652 0.042722 0.000270 0.356324 0.212374 -0.188433 0.196112 -0.223294 -0.014591 0.067874 -0.448922 -0.290960 -0.036474 -0.148416 0.448422 0.016454 0.071613 -0.078306 0.035400 0.330418 0.293890 0.202701 0.555509 0.447660 -0.361554 -0.266283 -0.134947 0.105315 0.131263 0.548085 -0.195238 0.062958 -0.011117 -0.226676 0.050336 -0.295650 -0.201271 0.014450 0.026845 0.403077 -0.221277 -0.236224 0.213415 -0.163396 -0.218948 -0.242459 -0.346984 0.282615 0.014165 -0.342011 0.370489 -0.372362 0.102479 0.547047 0.020831 -0.202521 -0.180814 0.035923 -0.296322 -0.062603 0.232734 0.191323 0.251916 0.150993 -0.024009 0.129037 -0.033097 0.029713 0.125488 -0.018356 -0.226277 0.437586 0.004913]
This is the vector representation of a word city and for us these numbers are not meaningful but with the help of these values algorithm can figure out the different words with similar meanings , as words having similar meaning will have closest vector values. And also with the help of this approach an AI system can figure out the difference between two words.