Apache Arrow Introduction
Arrow is a framework of Apache. It is a cross-language platform. Apache Arrow is an in-memory data structure mainly for use by engineers for building data systems. It also has a variety of standard programming language
. C, C++, C#, Go, Java, JavaScript, Ruby are in progress and also support in Apache Arrow. Apache Arrow was introduced as top-level Apache project on 17 Feb 2016. The latest version of Apache Arrow is
0.13.0 and released on
1 Apr 2019.
The Arrow is grown very rapidly, and it also has a better career in the future. It has efficient and fast data interchange between systems without the serialization costs, which have been associated with other systems like
thrift, Avro, and Protocol Buffers.
Arrow is not a standalone piece of software but rather a component used to accelerate analytics within a particular network and to allow Arrow-enabled systems to exchange data with low overhead. It is flexible to support the most complex data models.
Basic Concept of Apache Arrow
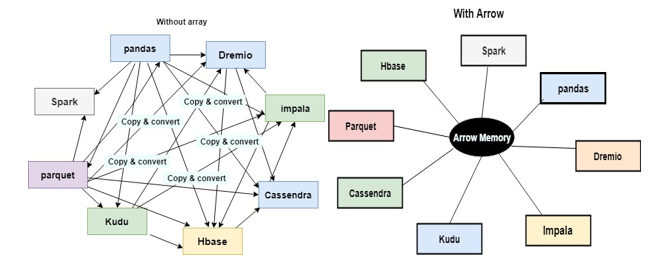
Apache Arrow comes with bindings to C / C++ based interface to the Hadoop file system. It means that we can read and download all files from HDFS and interpret ultimately with Python.
We can say that it facilitates communication between many components. For example, reading a complex file with
Python (pandas) and transforming to a Spark data frame.
Accurate and fast data interchange between systems without the serialization costs associated with other systems like Thrift and Protocol Buffers.
- Each method has its internal memory format
- 70-80% computation wasted on serialization and deserialization
- Similar functionality implemented in multiple projects.
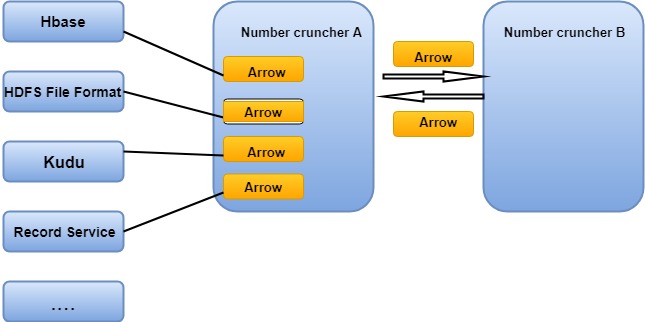 Apache Arrow improves the performance for data movement with a cluster in these ways:
Apache Arrow improves the performance for data movement with a cluster in these ways:
- Two processes utilizing Arrow as in-memory data representation can "relocate" the data from one method to the other without serialization or deserialization. For example, a Spark can send Arrow data using a Python process for evaluating a user-defined function.
- Arrow can be received from Arrow-enabled database-Like systems without costly deserialization mode. For example, Kudu can send Arrow data to Impala for analytics purposes.
- Arrow's design is optimized for analytical performance on nested structured data, such as it found in Impala or Spark Data frames. Let's see the example to see what the Arrow array will look.
people =
{
name: ‘ Swati ’, age: 24,
Place_live: [
{
city: ‘Delhi’, state: ‘UP’
},
{
city: ‘Mumbai’, state: ‘UP’
}
]
},
{
name: ‘suman’, age: 30,
Place_live: [
{
city: ‘Delhi’, state: ‘up’
},
{
city: ‘Ghaziabad’, state: ‘OH’
},
{
city: ‘goa’, state: ‘Panji’
}
]
}
]
How to install Apache Arrow in Windows
Following are the steps below to install Apache HTTP Server:
Step 1:
- Handle to Apache Website - (httpd.apache.org)
- Click on "Download" link for the latest version
- After redirecting to the download page, click on "Files for Microsoft Windows" link.
- Select any one of the websites that provide binary distribution (we have to choose Apache Lounge)
- After redirecting to "Apache Lounge" website (https://www.apachelounge.com/download/), click on Apache Win64 link
- After downloaded the library, unzip the file httpd-x.x.xx-Win64-VC15.zip into c:/
Step 2:
- Open a command prompt. Run as Administrator
- Navigate to directory c:/Apache24/bin
- Run the command httpd.exe -k install -n "Apache HTTP Server" to add Apache like a Windows Service.
- If any error happens while running the program then: "The program can't start because VCRUNTIME140.dll is missing from your computer. Then try to reinstall the program to fix this problem again" follow Step 3 otherwise jump to Step 4
Step 3:
- Check the section "Apache 2.4 VC15 Windows Binaries and Modules" on the main page at Apache Lounge website.
- Download the file vc_redist_x64 (i.e., https://aka.ms/vs/15/release/VC_redist.x64.exe) .
- Install Visual C++ 2017 files& libraries.
- Repeat Step 2.
Step 4:
- Open Windows Services and start the Apache HTTP Server.
- Open a Web browser then types the machine IP in the address bar and hit enter.
The message
"It works!" should appear.
How Apache Arrow overcomes drawbacks of Pandas
There are some drawbacks of pandas, which are defeated by Apache Arrow below:
- No support for memory-mapped data items.
- Poor performance in database and file ingest / export.
- Warty missing data support and internally so much far from 'the metal.'
- Lack of understanding into memory use, RAM management.
- Weak support for categorical data.
- Complex group by operations awkward and slow.
- Appending data to a Data frame complex and very costly.
- Limited, non-extensible type metadata.
- Eager evaluation model, no query planning.
Apache Arrow overcome the drawbacks of pandas
Getting closer to the metal:
All memory in Arrow is on a per column basis, although strings, numbers, or nested types, are arranged in contiguous memory buffers optimized for random access (single values) and scan (multiple benefits next to each other) performance. The idea is that you want to minimize CPU or GPU cache misses when looping over the data in a table column, even with strings or other non-numeric types.
Memory mapping big data sets:
Although the single biggest memory management problem with pandas is the requirement that data must be loaded entirely into RAM to be processed. Pandas internal Block Manager is far too complicated to be usable in any practical memory-mapping setting, so you are performing an unavoidable conversion-and-copy anytime you create a pandas.dataframe.
High-speed data ingest and export (databases and files formats):
Arrow's efficient memory layout and costly type metadata make it an ideal container for inbound data from databases and columnar storage formats like Apache Parquet.
Doing missing data right:
All missing data in Arrow is represented as a packed bit array, separate from the remaining of data. This makes missing data handling simple and accurate among all data types.
Keeping memory allocations in check:
In pandas, all memory is owned by
NumPy or by Python interpreter, and it can be difficult to measure precisely how much memory is used by a given pandas.dataframe.
Appending to data frames:
In pandas, all data in a column in a Data Frame must be calculated in the same NumPy array. It is a restrictive requirement.
Table columns in Arrow C++ can be chunked easily, so that appending a table is a zero copy operation, requiring no non-trivial computation or memory allocation. It is designing for streaming, chunked meals, attaching to the existing in-memory table is computationally expensive according to pandas now.
Adding new data types in Apache arrow
Here are various layers of complexity to adding new data types:
- Adding new metadata.
- You are creating dynamic dispatch rules to operator implementations in analytics.
- We are preserving metadata through operations.
The Architecture of Apache Arrow
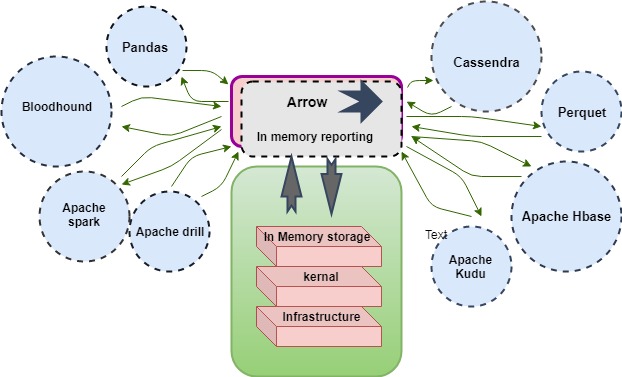
Arrow consists of several technologies designed to be integrated into execution engines.
The components of Arrow include
Defined Data Type Sets: It includes both SQL and JSON types, like Int, Big-Int, Decimal, VarChar, Map, Struct, and Array.
Canonical Representations: Columnar in-memory representations of data to support an arbitrarily complex record structure built on top of the data types.
Common Data Structures: Arrow-aware mainly the data structures, including pick-lists, hash tables, and queues.
Inter-Process Communication: Achieved under shared memory, like
TCP/IP, and RDMA.
Data Libraries: It is used for reading and writing columnar data in various languages, Such as Java, C++, Python, Ruby, Rust, Go, and
JavaScript.
Pipeline and SIMD Algorithms: It also used in multiple operations including bitmap selection, hashing, filtering, bucketing, sorting, and matching.
Columnar In-Memory Compression: it is a technique to increase memory efficiency.
Memory Persistence Tools: persistence through non-volatile memory, SSD, or HDD.
Use Case of Apache Arrow
- SQL execution engines (like Drill and Impala)
- Data analysis systems (as such Pandas and Spark)
- Streaming and queuing systems (like as Kafka and Storm)
- Storage systems (like Parquet, Kudu, Cassandra, and HBase).
Benefits of Apache Arrow
- No copy to any ecosystem like Java/R language.
- Provide a universal data access layer to all applications.
- Low loading while streaming messaging.
- It supports flat and nested schemas.
- Support GPU.
Binding Between Arrow and New languages
In addition to
Java, C++, Python, new styles are also binding with Apache Arrow platform.
C: One day, a new member shows and quickly opened ARROW-631 with a request of the 18k line of code. Kouhei Sutou had hand-built C bindings for Arrow based on GLib!!
Ruby: In Ruby, Kouhei also contributed Red Arrow. Kouhei also works hard to support Arrow in Japan.
JavaScript: JavaScript also two different project bindings developed in parallel before the team joins forces to produce a single high-quality library.
Rust: Andy Grove has been working on a Rust oriented data processing platform same as Spacks that uses Arrow as its internal memory formats.
Arrow and spark
Arrow aims different word of processing. One place the need for such a span is most clearly declared is between JVM and non-JVM processing environments, such as Python. Individually, these two worlds don't play very well together. And so one of the things that we have focused on is trying to make sure that exchanging data between something like pandas and the JVM is very more accessible and more efficient.
One way to disperse Python-based processing across many machines is through Spark and PySpark project. In the past user has had to decide between more efficient processing through Scala, which is native to the JVM, vs. use of Python which has much larger use among data scientists but was far less valuable to run on the JVM. With Arrow Python-based processing on the JVM can be striking faster.
Arrow and Dramio
In Dremio, we make ample use of Arrow. As Dremio reads data from different file formats (Parquet, JSON, CSV, Excel, etc.) and various sources (RDBMS, Elastic search,
MongoDB, HDFS, S3, etc.), data is read into native Arrow buffers directly for all processing system. Our vectorized Parquet reader makes learning into Arrow faster, and so we use Parquet to persist our Data Reflections for extending queries, then perusal them into memory as Arrow for processing.
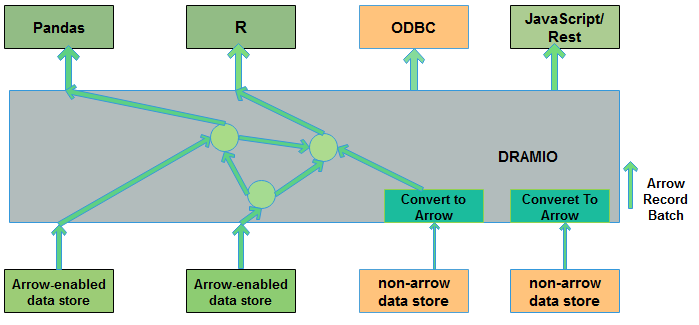
Why we use Arrow?
One best example is pandas, an open source library that provides excellent features for data analytics and visualization.
Second is Apache Spark, a scalable data processing engine. We can generate these and many other open source projects, and commercial software offerings, are acquiring Apache Arrow to address the summons of sharing columnar data efficiently.
The Apache Arrow goal statement simplifies several goals that resounded with the team at Influx Data;
Arrow is a cross-language development platform used for in-memory data. It specifies a particular language-independent columnar memory format for labeled and hierarchical data, organized for efficient, precise operation on modern hardware. It also generates computational libraries and zero-copy streaming messages and interprocess communication. Languages supported in Arrow are C, C++, Java, JavaScript, Python, and Ruby.
Standardized: Many projects like data science and analytics space have to acquire Arrow as it addresses a standard set of design problems, including how to effectively exchange large data sets.
Performance: The performance is the reason d 'être. Arrow data structures are designed to work independently on modern processors, with the use of features like single-instruction, multiple data (SIMD).
Language-Independent: Developed libraries exist for C/C++, Python, Java, and JavaScript with libraries for Ruby and Go in swamped development. More libraries did more ways to work with your data. That is beneficial and less time-consuming.
We also identify Apache Arrow as an opportunity to participate and contribute to a community that will face similar challenges.
Conclusion
It is an In-Memory columnar data format that houses legal In-memory representations for both flat and nested data structures. It uses as a Run-Time In-Memory format for analytical query engines. It includes Zero-copy interchange via shared memory.
It sends a large number of data-sets over the network using Arrow Flight. Memory efficiency is better in Arrow. Arrow is designed to work even if the data does not entirely or partially fit into the memory.
Arrow is mainly designed to minimize the cost of moving data in the N/w. With many significant data clusters range from 100's to 1000's of servers, systems can be able to take advantage of the whole in memory. Many projects are including Arrow are used to improve performance and take positions of the latest optimization.