Apache Hive Architecture
Architecture of Apache Hive
The following diagram shows the architecture of the Hive. We will look at each component in detail:
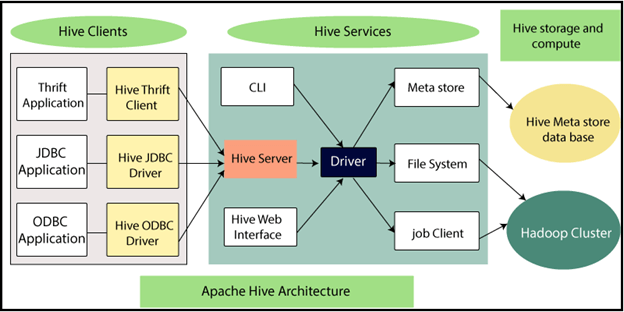
There are three core parts of Hive Architecture:-
- Hive Client
- Hive Services
- Hive Storage and Computer
Hive Client
Hive provides multiple drivers with multiple types of applications for communication. Hive supports all apps written in programming languages like Python, C++, Java, etc.
There are three categorized this client-
- Hive Thrift Clients
- Hive JDBC Driver
- Hive ODBC Driver
Hive Thrift Client
As the Thrift-based Apache Hive server will handle the application from all those languages that support Thrift.
Hive JDBC Driver
Apache Hive provides Java applications with a JDBC driver to connect to it. The class- apache, Hadoop, Hive. JDBC, HiveDriver, is described.
Hive ODBC Driver
ODBC Driver enables ODBC protocol-supporting applications to connect to Hive. For Example, ODBC, JDBCuses Thrift to communicate with the Hive server.
Hive Services
Hive client integration can be performed through Hive Services. If a customer wishes to perform any operation related to Hive operations, they must contact Hive Services.
There are three categorized this Hive Services:-
- Hive CLI (Command Line Interface)
- Apache Hive Web Interfaces
- Hive Server
- Apache Hive Driver
Hive CLI (Command Line Interface)
This is a standard shell provided by Hive, where you can execute Hive queries and enter commands directly.
Apache Hive Web Interfaces
Hive also offers a web-based GUI to execute Hive queries and commands in addition to the command line GUI.
Hive Server
Its server is created on apache Thrift and therefore is also referred to as Thrift Server that allows the different clients to submit a request to Hive and retrieve the final result.
Apache Hive Driver
The current Hive service driver mirrors the master driver and passes all types of ODBC, JDBC, and other client-specific requests. Wade will process these programs in various Meta stores and wildlife systems to keep things going.
Hive Storage and Computer
Hive services, such as the Meta Store, the file system, and work clients, are also involved in and do the following for the Hive repository.
- Metadata tables created in Hive are stored in the "Meta storage database" in Hive.
- The results of the query and data loaded in the tables will be stored on HDFS in the Hadoop cluster.