Spark Tutorial
Spark tutorial provides important and advanced Spark concepts. Spark is a single analytics platform for large scale data processing. It includes SQL, streaming, machine learning, and graph processing modules.
Our Spark tutorial covers all of Apache Spark’s topics, including Spark Introduction, Spark Architecture, Spark modules, Spark installation, RDD, Spark real-time example, etc.
Requirement
Before learning Spark, you are required to have basic knowledge of Hadoop.
Audience
Our Spark tutorial is designed for beginners as well as professionals alike.
Problem
With this Spark tutorial, we are sure you won’t find any issues. But if an error message, please post the issue to the contact form.
What is Spark?
Apache Spark is an open-source cluster computing framework, developed for real-time processing by the Apache Software Foundation. Spark provides an all-cluster programming interface with clear parallelism and fault tolerance data.
The data is processed by Spark in real-time, which produces quick results in addition to the MapReduce. The MapReduce processes the stored data.
Features of Apache Spark
The main features of Apache Spark are:
- Fast Processing
- Real-Time Stream Processing
- Flexibility
- Improved Analytics
- In-Memory calculating
- Compatibility with Hadoop
Fast Processing
Apache Spark’s essential feature is speed that makes it unique from other platforms. Big data is defined by its, veracity, volume, value, velocity, and variety meaning it must be processed at high speed. Spark includes RDD (Resilient Distributed Datasets), which saves time in writing and reading operations. Due to such operations, it runs about 10–100 times faster than Hadoop.
Real-Time Stream Processing
Spark can process data streaming in real-time. Except MapReduce, whoever processes the stored data becomes successful in processing the data in real-time with Spark. It thus produces immediate results.
Flexibility
Apache Spark supports several languages such as Java, Python, Scala, and R. It allows developers to build applications in any language. This method, which is fitted with over 80 high-level operators, is quite rich from this aspect.
Better Analytics
Spark has much more in stock compared to MapReduce, which comprises of Map and Reduce functions. Apache Spark is a rich collection of SQL queries, in-depth analysis, machine learning algorithms, etc. Big Data Analysis can be done faster with all these Spark functionalities.
In-Memory calculating
Spark stores data in server RAM, so that data can be quickly accessed, which in-turn accelerates analytics speed.
Compatibility with Hadoop
The capability of Spark is to work independently and on the top of the Hadoop. It is also compatible with both of the Hadoop architecture models.
Uses of Spark
There are following main uses of Apache Spark:-
- Data integration
- Interactive analytics
- Machine Learning
- Stream processing
Data integration
The data provided by different business systems is hardly enough to be pure or to be connected to simple analysis or report. The processes of extracting, transforming, and loading (ETL) are often used to take, clean, and standardize data from different systems and then load it into a separate processing system. Apache Spark is important for the ETL process, which serves at the required cost and time.
Interactive analytics
Spark will generate a quick response. So, we can manage the data interactively, instead of running predefined queries.
Machine Learning
When data volumes increases, approaches to machine learning become more feasible and even more accurate. This triggers the software to identify and to be correct.
The ability of Spark is to store the data in memory. It is considered as a good option for training and machine learning algorithms, which can run repeated queries quickly. Running roughly similar issues over and over again on the scale significantly reduces the time it takes to go through a series of solutions to find the most effective algorithms.
Stream Processing
It is difficult to handle the data generated in real-time, for example, log files. Spark is sufficiently capable of running data streams and refuses potentially fraudulent operations.
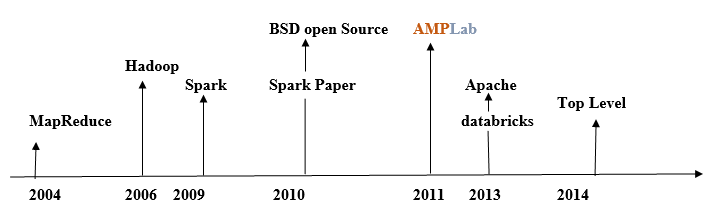
History of Apache Spark
Apache Spark was introduced by Matei Zaharia at UC Berkeley R&D Lab, which is also known as AMPLab in 2009. It became open-sourced in 2010 under a BSD license.
The Apache spark was acquired to Apache software foundation, in 2013. The Spark became the Highest Apache Project in 2014.