YARN: Hadoop Module
What is Yarn?
YARN stands for "Yet Another Resource Negotiator." It is a large-scale, distributed operating system for big data applications. The designed technology for cluster management is one of the key features in the second generation of Hadoop. Yarn is a software rewrite that is capable of decoupling MapReduce resource management and scheduling the capabilities from the data processing component.
Features of Yarn
YARN has gained popularity due to the following features.
Scalability
The processing power of the data center has improved significantly. YARN's Resource manager focuses exclusively on scheduling and keeps pace as the clusters expand to thousands of data petabyte management nodes.
Compatibility
MapReduce applications developed for Hadoop are running on YARN without interrupting existing processes. YARN maintains compatibility with the API and Hadoop's previous stable release.
Cluster Utilization
Since YARN supports Hadoop cluster dynamic utilization, it enables optimized cluster usage.
Multi-Tenancy
For batch, interactive, and real-time access to the same dataset, we can use multiple open-source and proprietary data access engines. The processing of multi-tenant data improves the return of a company on its Hadoop investments.
Multiple Resource types
Multiple types of resources, such as CPU, GPU, and memory, can be used.
Hadoop Yarn Architecture
Apache Hadoop Yarn Architecture consists of the following components:
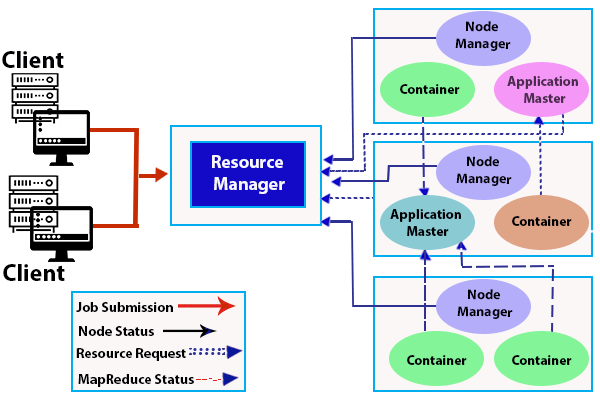
Client
It submits map-reduce jobs.
Resource Manager
- It is the ultimate resource allocation authority.
- It passes parts of the requests to the corresponding node managers while receiving the requests for processing, where the actual processing takes place.
- It is the cluster resource arbitrator and decides to allocate the resources available for competing applications.
- It optimizes the use of clusters. For example, to keep all resources in use all the time against various constraints such as guarantees of capacity, fairness, and SLAs.
It has two major components: - a) Schedule b) Application Manager.
a) Schedule
- The scheduler must allocate the resources to different running applications, subject to space constraints, queues, etc.
- In Resource Manager, it is called as a mere scheduler, which means it does not control or track the status of the application.
- The scheduler does not guarantee the restart of failed tasks if there is an application failure or hardware failure.
- It performs scheduling based on the application's resource requirements.
- It has a pluggable rule plug-in that is responsible for partitioning the resources of the cluster between different applications. There are two such plug-ins: Capacity Scheduler and Fair Scheduler, used in Resource Manager as Schedulers.
b) Application Manager
- It is responsible for accepting job applications.
- It negotiates the Resource Manager's first container to execute the Application Specific Master application.
- It manages the Application Masters running in a cluster and provides service in case of failure to restart the Application Master tank.
Node Manager
- In a Hadoop cluster, it takes care of individual nodes and manages user jobs and workflow on the given node.
- It registers with the Resource Manager and sends the node's health status heartbeats.
- The primary objective is to handle the resource manager's allocated database containers, which keeps the Resource Manager up-to-date.
- The Application Master requests the Node Manager's assigned container by sending it a Container Launch Context (CLC), which includes everything we need to run an application. The node manager thus creates and starts the process of the requested container.
- It monitors the use of the resources of each container (memory, CPU).
- The Log performs control.
- It also kills the resource manager's container as directed.
Application Master
- A request is a single job that is submitted to the framework. Each application is associated with a unique Application Master, which is an entity-specific to the framework.
- It is a mechanism that controls the cluster execution of a request and handles the errors.
- Its role is to negotiate the resources of the Resource Manager and collaborate with the Node Manager to perform and track the tasks of the node.
- It is responsible for negotiating the Resource Manager's appropriate resource containers and to monitor their status and progress.
Container
- It is a set of physical resources on a single node, including RAM, CPU cores, and disks.
- YARN containers are managed through a context of container launch, which is the life cycle of the container (CLC). The record thus includes a map of environment variables, node manager service payload, security tokens, dependencies stored in remotely accessible storage, and the command needed to create the process.
- It gives the right to an application to use a specific amount of resources in a particular host (memory, CPU, etc.)
Advantages of YARN
- Resource utilizationhas improved with proper usage of map and reduce slots.
- Scalabilityissues have been resolved.
- Non-Map Reduce Jobscan be submitted.
- All elements are readily usable — no single point of failure.
Application workflow in Hadoop Yarn
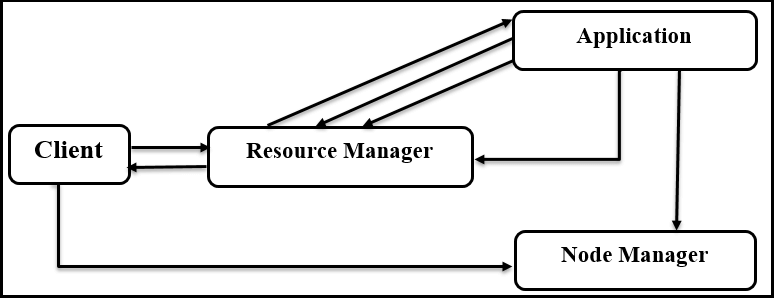
- The client applies.
- The Resource Manager allocated a container to start the Application Manager.
- The Application Manager registers them with the Resource Manager.
- The Application Manager negotiates containers from the Resource Manager.
- The Application Manager in the above diagram, notifies the Node Manager to launch containers.
- The application code is executed in the container.
- The Application Manager registers itself with the Resource Manager.