MapReduce Tutorial
MapReduce Tutorial
MapReduce tutorial provides important and advanced MapReduce concept.
Our MapReduce tutorial involves all MapReduce topics such as MapReduce API, MapReduce Data Flow, Word Count Example, Character Count Example, etc.
What is MapReduce?
MapReduce is a Hadoop processing layer. It is a programming model built to handle a large volume of data. Hadoop can run the MapReduce programs written in different languages-Java, Python, Ruby, and C++. MapReduce programs are parallel and therefore very useful for large-scale data analysis using multiple cluster machines.
Why MapReduce?
Usually, traditional enterprise system used centralized data storage and processing server. This system was unsuitable for processing large data volumes. When we try to process multiple files at the same time, then too much of a bottleneck was generated by the centralized system. By using an algorithm known as MapReduce, Google provided the solution to this bottleneck problem.
How does the Hadoop Mapreduce work?
MapReduce Model contains two main tasks, i.e., Map and Reduce
- The Map task takes a data set and converts it to another data set, where Individual elements are divided into groups (key-value pairs).
- Reduce takes the Map output as input and transforms the data tuples (key-value pairs) to a smaller collection of tuples.
Data Flow in MapReduce

Input Reader
The input reader reads the future data and splits the data blocks to the size (64 MB to 128 MB).Every data block has a Map feature associated with it.
Once the input reads the data, the corresponding key-value pairs are generated. The input data are processed as HDFS data.
Map Function
The map feature calculates the arriving key value pairs and produces the corresponding output pairs for the key value. The form of a map's input and output that vary from one another.
Combiner
A combiner is a local Reducer category grouping similar data into recognizable sets from the mapping process. It takes the intermediate keys from the mapper as input and uses the user-defined code to sum the values in the limited range of one mapper. It is not part of the main algorithm of MapReduce; it is optional.
Shuffle and Sort
It Reducer task starts with the shuffle and sort step. Where the reducer is running, it downloads key-value pairs in the local machine. The key sorts the extensive data list in the individual key-value pairs. It takes the intermediate keys from the mapper as input and uses the user-defined code to sum up values within one mapper's limited range.
Reducer Phase
The Reducer takes the grouped key-value paired information as an input and runs a Reducer function on each of them. The data can be aggregated, analyzed, and combined in various ways, which require a wide range of processing. Once the execution is complete, zero or more key-value pairs will be given to the final step.
Output Phase
In the output step, we have an output format that uses a record writer to translate the final key-value pairs from the Reducer function to a register.
MapReduce works by breaking the process into 3 phases.
- Map Phases
- Sort & Shuffle Phases
- Reduce Phases
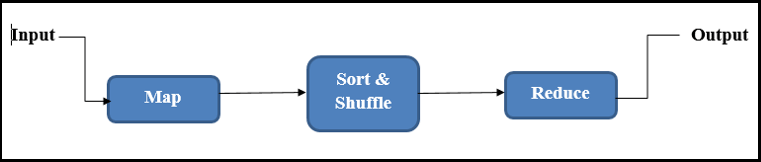
Map Phase
The map phase takes the input as key-value pairs (K, V) and generates the output as (K, V).
Sort & Shuffle
The Sort and Shuffle phase takes the input as (K, V) and generates the output in the Key and Value List pair form (K, List (v)).
Reduce
The input is taken as (K, List (v)), and the output is generated as (K, V). The reducer phase output is the final output.
Features of the MapReduce
The crucial elements of MapReduce follow:-
- There are built-in redundancy and tolerance for faults available.
- The programming template for MapReduce is language independent.
- Allows local data processing.
- There are automatic parallelization and distribution.
- Abstracts developers from the complexity of the programming languages distributed.
- Manages distributed servers running through different tasks at the same time.
- Manages all communication and transfer of data between different parts of the system module
- The overall management of the entire process is provided with redundancy and failures.
MapReduce Architecture
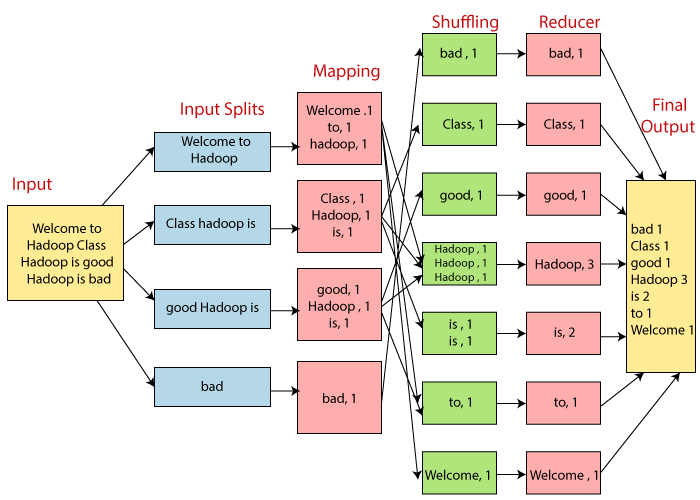
Some data goes through the following Phases
This programming model or framework is used in Hadoop. Hadoop
For writing applications that process and analyze large data sets in parallel on large
multinode clusters of commodity hardware in a reliable, scalable, and fault-tolerant manner, MapReduce is used. Data analysis and
processing uses two different steps. They are Map phase and Reduce phase
1
It is a software framework used in Apache Hadoop. Hadoop
MapReduce is provided for writing applications that process and analyze large data sets in
a scalable, reliable, and fault-tolerant manner
on large multinode clusters of commodity hardware.
1
It is a pr model or a software framework used in Apache Hadoop. Hadoop
MapReduce is provided for writing applications that process and analyze large data sets in parallel on large
multinode clusters of commodity hardware in a scalable, reliable, and fault-tolerant manner. Data analysis and
processing uses two different steps namely, Map phase and Reduce phase
1?
- InputSplit
- Mapping
- Shuffling and sorting
- Reducer
InputSplit
The input to a MapReduce job is divided into pieces of fixed size called input splits Input split is one part of the output collected by a single map.
Mapping
It is the first step of map-reduce execution. In this step, data is passed to a mapping function for the creation of output values in each split. In our example, a mapping task consists of counting several occurrences of each word from input splits (more details on input-split are given below) and preparing a list in the form of < word, frequency >
Shuffling and Sorting
This process utilizes the output of the Mapping process. His job is to compile records of the related process outputs. In our example, together with their frequency, the same words are clubbed.
Reducer
In this phase, the shuffling phase output values are aggregated. This process combines the values of the Shuffling step and returns one output value. In short, the entire data set is summarized in this phase.
MapReduce Life Cycle
The Mapreduce Life Cycle consists of the following four units
- The client of the job who submits the job.
- The job tracker that takes care of the overall performance of the job runs a Java programming language with the main class jobtrack here.
- The job tracker who sells the position as a whole. It is a java program with JobTracker in the key class
- The shared file system, provided by HDFS.
Below is the list of tasks plays the key role in MapReduce lifecycle –
- Client Program
- Job Tracker
- Task Tracker
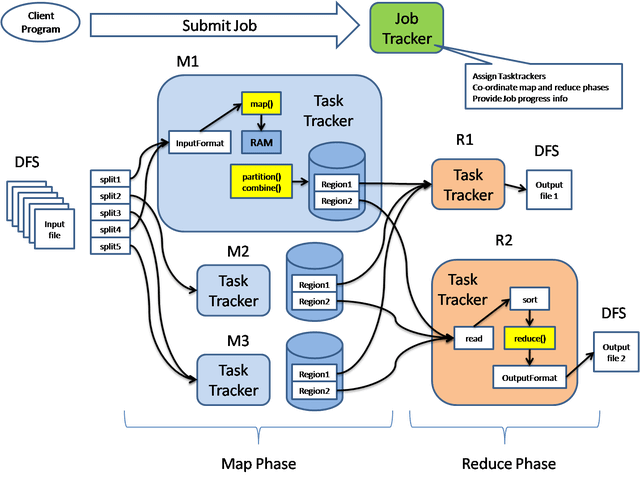
Job Client
The Job Client prepares the work for execution.
The Local Job Buyer performs below If the Software is implemented in Hadoop:
- Configuration to the job validates.
- The input splits generate.
- Track service resources in a shared environment (HDFS directory) available for Job Tracker and Task Trackers.
- It then submits the job to the Job Tracker.
Job Tracker
The tasks below are the responsibility of the Job Tracker-
- Job scheduling.
- Splitting a job into parts, which are a map-reduce & task.
- Distribution of Map and reduce tasks among worker nodes.
- Recovery of vision loss.
- Tracking job status.
It performs as below while trying to run a job-
- Fetches input splits from the location where the Job User placed the data.
- For each break, it generates a map mission.
- Assigns a task to a task tracker for each Map.
The Job Tracker tracks the Project Trackers ' safety and work performance.
Once the mapping results are visible, the Job Tracker performs the following steps
- Creates tasks that are minimized to the extent that the work specification requires.
- Assigns a reduced function to each partition of the map result.
Task Tracker
A Project Tracker tracks the assigned tasks and records the Work Tracker status.
The Task Tracker runs on the associated node.
It may not allow the related node to be on the same host.
Task tracker performs below if the Job Tracker allocates a map or a Work Tracker is reduced-
- Fetches job resources locally.
- Reports status to the Job Tracker.
- To execute the Map or reduce task, it issues a child JVM on the node.
MapReduce-API
The involvement of the Mapreduce Programming Operation is in classes and methods.
Below is the concept in MapReduce API-
- JobContext interface
- Job Class
- Mapper Class
- Reduce Class
JobContext interface
- The job class is the main class to execute the JobContext interface.
- It is the main platform for all levels of jobs.
- It explains and defines jobs in MapReduce.
- The read-only view of the job while this interface gives it while it is running.
The JobContext sub-interfaces are-
| S.No. | Sub-Interface Description |
| 1. | MapContext<KEYIN, VALUEIN, KEYOUT, VALUEOUT> The mapper defines the context. |
| 2. | ReduceContext<KEYIN, VALUEIN, KEYOUT, VALUEOUT> It determines the context for which the reducer is allocated. |
Job class
- Job class is an integral MapReduce class.
- Allows the user to set up the job, to apply it, to monitor the execution of the job and to ask it in its state.
- Typically the applicant creates an application, describes different facets of the job through a resume, then submits the application and monitors the progress of the task.
E.g.:- submit to the job-
// create a new Job
| Job job = new Job (new Configuration ()); job.setJarByClass (MyJob.class); |
// specify various job-specific parameters
| job. SetJobName ("myjob"); job.setInputPath (new Path ("in")); job.setOutputPath (new Path ("out")); job.setMapperClass (MyJob.MyMapper.class); job.setReducerClass (MyJob.MyReducer.class); |
// submit the job, poll for progress until the job is complete
| job.waitForCompletion (true); |
Constructors
Below is the constructor summary of the Job class.
| S.No. | Constructors summary |
| Job() | |
| Job (Configuration conf) | |
| Job (Configuration conf, String jobName) |
Some Methods of Job class –
Some of the essential methods of Job class are as follows ?
- cleanupProgress (): It helps in gathering the information about the progress of the cleanup-tasks of job.
- getCounters (): It helps in gathering the information about the counters for this job
- getFinishTime (): It helps in gathering the information about the finish time or ending time of the job.
- getJobFile (): It helps in gathering the information about the path of the submitted job configuration.
- getJobName (): job name specified by the user
- getJobState (): Returns the job's current state
- getPriority (): Get scheduling info of the job
- getStartTime(): Get start time of the job
- isComplete(): Checks whether the job is finished or not
- isSuccessful(): Check if the job is completed successfully
- setInputFormatClass(): Sets the input format for the job
- setJobName(String name): Sets the job name specified by the user
- setOutputFormatClass(): Sets the output format for the job
- setMapperClass(Class): Sets the mapper for the job
- setReducerClass(Class): Sets the reducer for the job
- setPartitionerClass(Class): Sets the practitioner for the job
- SetCombinerClass (Class): Sets the combiner for the job.
Mapper Class
- Maps input key or value to a group of intermediate key or value pairs.
- Maps are separate activities for the conversion to intermediate records of input information.
- Input records need not be of the same kind as the transformed intermediate records.
- According to the input pair, zero and several output pairs may be mapped.
Methods of Mapper class
- Void setup (org.apache.hadoop.mapreduce.Mapper.Context context) - In order to perform the function of this method, only call is made.
- Void map (KEYIN key, VALUEIN value, Context context) - The input division of this method is called only once for each different key value.
- Void run (org.apache.hadoop.mapreduce.Mapper.Context context) - This method can override the mapper's execution to run correctly.
- Void cleanup (org.apache.hadoop.mapreduce.Mapper.Context context) - This method is used only once at the end of the task.
Reduce Class
- This determines the function of the mapreduce reducer.
- Reduces is an intermediate set of exchanging primary values with a smaller set of values.
- Reducer implementations can use the JobContext.getConfiguration) (method to access the job configuration.
There are 3 phases of reducer Class -
- Shuffle: The Reducer uses HTTP to copy the sorted data from each Mapper over the network.
- Sort: Sort: Framework by key merges Reducer input separately (whereas mappers here can have only one key output).
- The phases of shuffle and sorting occur simultaneously i.e. they are combined while the outputs are being fetched.
- Reduce: Syntax is- reduce (Context, Iterable, object).
Method of Reduce Class-
- Setup (org.apache.hadoop.mapreduce.Reducer.Context context) - In order to perform the function of this method, only call is made
- Void map (KEYIN key, Iterable<VALUEIN> values, Context context) - This method calls only once for different keys
- Void run (org.apache.hadoop.mapreduce.Reducer.Context context) - To do this method controls the functions of the reducer.
- Void cleanup (Context context) - This method is called only once while working.
Prerequisite
The requirement to learn Hive is knowledge of Big Data.
Audience
Our MapReduce Tutorial is designed for beginners as well as professionals.
Problem
With this MapReduce tutorial, we are sure you won't find any issues. But if an error message, please post the issue to the contact form.