Apache Pig Architecture
Apache Pig Architecture and Components
Pig Latin is a language used in Hadoop for the analysis of data in Apache Pig. Pig is a high-level data processing language that provides a rich set of data types and operators to perform multiple data operations.
Programmers need to write a Pig script using the Pig Latin language and execute it using any of the execution mechanisms (Grunt Shell, UDFs, and Embedded) to perform a specific task. To produce the desired output after execution, these scripts will go through a series of transformations applied by the Pig Framework.
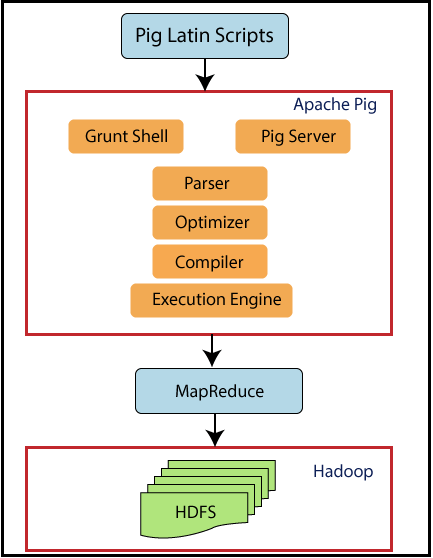
Apache Pig Components
There are multiple components in the Apache Pig framework.
- Parser
- Optimizer
- Compiler
- Execution engine
Parser
The parser handles all the pig Scripts. The parser checks the syntax of the Script and checks for various other types and verifications. The parser output will be a DAG (directed acyclic graph), which represents Pig Latin's statements and logical operators.
Optimizer
The logical plan (DAG) is passing to the logical optimizer, which performs the logical optimizations like projection and pushdown.
Compiler
The compiler compiles the improved logical plan into a series of MapReduce jobs.
Execution Engine
The MapReduce jobs are submitted in sorted order to Hadoop. It produces the desired results by performing these MapReduce jobs on Hadoop.