Hive Tutorial
Hive tutorial provides basic and advanced Hive concepts.
Hive is a data warehouse solution to be used on top of Hadoop. It allows accessing the files in HDFS, as MapReduce queries them using the SQL-like query language called HiveQL. The queries are transformed into MapReduce jobs and executed in the Hadoop Framework.
Our Hive tutorial involves all the topics of Apache Hive with Hive Installation, Hive Table partitioning, Hive Data Types, Hive DML commands, Hive DDL commands, Hive sort by vs. order by, Hive Joining tables, etc.
What is Hive?
Hive Introduction: Hive is a Data Warehouse and open-source platform. It is present on the top of Hadoop. It is used to analyze the structured and semi-structured data. Initially, Hive was developed by Facebook, before being an open-source project of Apache Hadoop.
Its work is to solve queries and manage large datasets residing in distributed storage. Hive provides a method to project structure on the data and query the data using a language called HiveQL. HiveQL is a language similar to SQL (Structured Query Language).
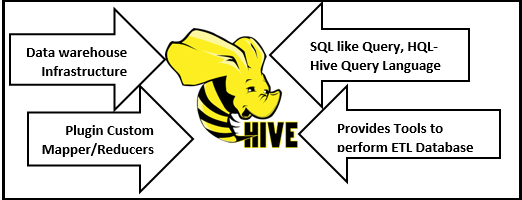
Features of Hive
- Hive is familiar, fast, and Scalable.
- It supports Online Analytical Processing (OLAP).
- It is an efficient ETL (Extract Transform Load) tool.
- The structured data can be quickly processed in Hadoop using Hive.
- Hive can analyze large data sets that are saved in HDFS.
- For Hive-QL, multiple users can query the data at the same time.
Limitations of Hive
- Limited sub-query support.
- It is not suitable for the Online Transaction Processing (OLTP).
- It does not supports delete and update operations.
- It does not offers real-time queries and updates at the row level.
Prerequisite
The requirement to learn Hive is knowledge of Hadoop and Java.
Audience
Our Hive Tutorial is a designed for beginners as well as professionals.
Problem
You will not find any problem in this Hive tutorial. If there is any mistake, please post the problem in the contact form.