Disadvantages of K-Means Clustering
K-Means Clustering
K-means clustering is one of the most popular machine learning algorithms. It is a type of unsupervised machine learning algorithm, and this approach is used for partitioning a dataset into K clusters. Here, variable K is a predefined number of clusters. The main goal of this algorithm is to make a group of similar data points together and minimize the distance between data points within each cluster.
K-means clustering is a robust algorithm for grouping data points into a K cluster and is also used to detect an unusual pattern in data. It also has several applications, such as Image segmentation, customer segmentation, and other detection.
.K- Means Algorithm :
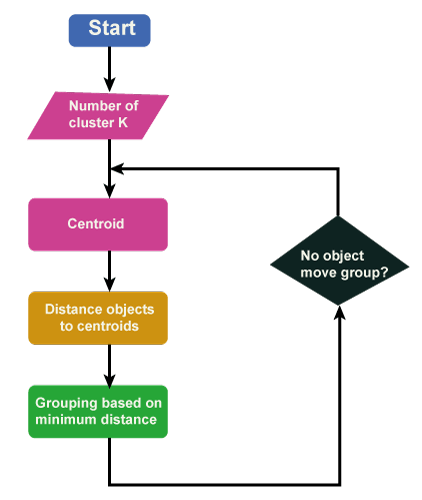
K-means clustering is an unsupervised machine learning algorithm that partitions a given dataset into k clusters based on the similarity of the data points. The algorithm works as follows:
- Choose the number of clusters (k) to create.
- Initialize k random centroids (centre points) for the clusters.
- Assign each data point to the closest centroid based on the Euclidean distance between the data point and the centroid.
- Update the centroids by calculating the mean of all the data points in each cluster.
- Repeat steps 3 and 4 until the centroids no longer move or reach a maximum number of iterations.
This algorithm tries to minimize the within-cluster sum of squares (WCSS) or the sum of the squared distances between each data point and its assigned centroid. The optimal value of k is often determined by using the elbow method, which involves plotting the WCSS for different values of k and selecting the k that causes the greatest reduction in WCSS.
Disadvantage of K-Means Clustering
The K-means clustering algorithm is a widely used method for partitioning data into clusters. However, there are several disadvantages to these Algorithms:
1- Non-Linear Boundaries: K-means clustering is used in the algorithm where clusters are spherical and have a linear boundary. And those cases where clusters have non-linear boundaries, k-means clustering may not be able to capture the underlying structure of the data.
2- High-DimensionalData: High Dimensional data make it difficult to identify meaningful clusters. In such cases, others clustering algorithm may be more appropriate.
3- Clusters: It is a significant problem to detect clusters with similar behaviour because clustered data clusters are of different sizes and densities.
4- Robustness: It assumes that data is usually distributed and each cluster has an equal variance. And this assumption can only be enforced if the data is usually distributed. Therefore, K-means clustering may produce poor results.
5- Sensitivity: K-means clustering can be sensitive to the initial of the centroids, which may lead to different results for different initializations. And if the initials centroids are not representative of the data, K-means clustering may converge to a suboptimal solution.
6- Healthcare: K-means clustering may not consider individual patient characteristics or medical history, which may result in inappropriate treatment decisions.
7- Natural Language Processing: this clustering may not capture all features of the semantics of the language. Examples: It may not be effective for unstructured data such as social review posts.
8- Marketing: K-means Clustering is not suitable for unstructured Data like customer reviews or social media posts.
9- Handling Outliers: Data is distributed in a spherical manner around the centroid of each cluster. Outliers can significantly affect the placement of cluster centres and lead to inaccurate clustering results.
10-Scalability: K-means may not scale well to extensive or high-dimensional data, as it involves computing distances between all data points and cluster centres.
Overall, the K-means algorithm is a powerful tool for clustering analysis that can be applied to various data types and problem domains. However, it is also essential to be aware of its limitations and potential drawbacks.