Hands-on Machine Learning with Scikit-Learn, TensorFlow, and Keras
"Hands-On Machine Learning with Scikit-Learn and TensorFlow Keras" by Aurélien Géron is the best for you if you're comfortable with Python coding and want a fast introduction to both traditional and deep learning techniques in Python from an experienced practitioner.
Nearly little prior knowledge of machine learning is assumed throughout the book. It employs Python frameworks prepared for usage in production, including Tensorflow, Keras, and Scikit Learn.

Through several working examples and a small amount of theory, the author emphasizes a practical approach. Although for using this book you need to have a little bit of a premise of certain topics like Python programming, knowledge and understanding of Pandas, Matplotlib, and NumPy, and certain levels of mathematics that include statistics, linear algebra, probability, and calculus.
Content of the book
- The Machine Learning Landscape
- End-to-End Machine Learning Project
- Classification
- Training Models
- Support Vector Machines
- Decision Trees
- Ensemble Learning and Random Forests
- Dimensionality Reduction
- Unsupervised Learning Techniques
1. The Machine Learning Landscape
In this chapter of the book you will learn about the following things:
- What is Machine Learning?
- Why do we use Machine Learning?
- Application of Machine Learning
- Machine Learning algorithm types like instance-based versus model-based learning and Supervised versus Unsupervised Learning
- Practical Examples, so that you will enhance your practical skill
- Challenges of using machine learning.
2. End-to-End Machine Learning Project
As we move forward to the next chapter we will focus on working on real-life projects, where we will pretend that we have the data of a real estate company.
Roughly you will follow these steps:
- Defining the issue & taking a broad view
- Getting the Data
- Exploring the Data
- Preparing the Data
- Shortlisting the models
- Tuning your model
- Presentation of the solution
- Launch of the model
- Maintenance of the solution
3. Classification
MNIST will be used for categorization in this chapter. 70,000 tiny pictures, or "MNIST" data, represent handwritten digits by students and staff of the US Census Bureau. The digit each image represents is written next to it (ranging from 0 to 9).
Scikit-learn offers a number of assistance tools for downloading well-liked datasets.
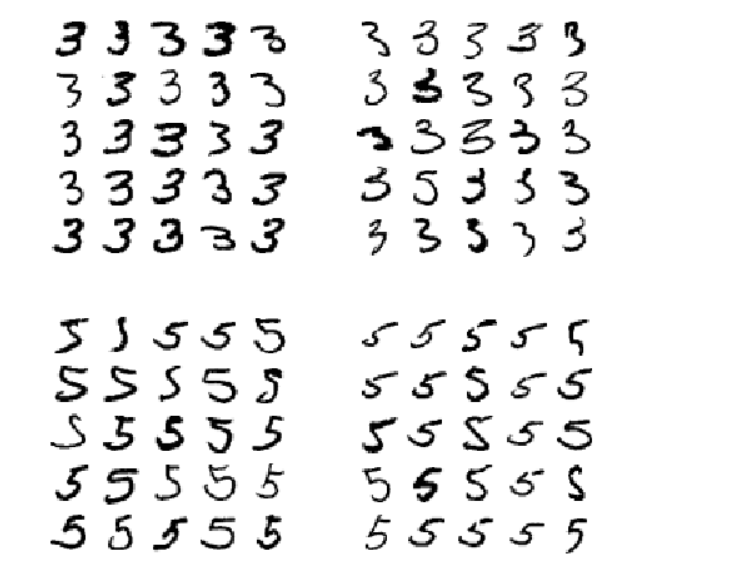
4. Training Models
Beginning in this chapter, we will examine linear regression training from two alternative perspectives:
- obtaining the ideal parameters for the linear model using a straightforward, "closed-form," analytical technique.
- utilizing the gradient descent method of interactive optimization.
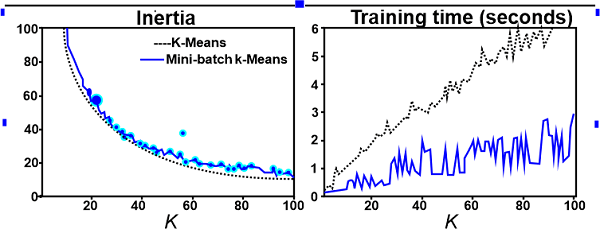
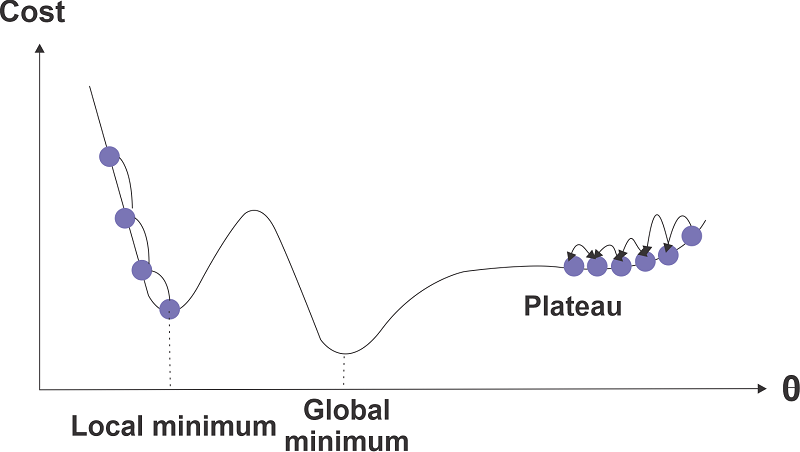
Model parameters are gradually adjusted by GD until they match those discovered by Technique 1's method. We will examine several variations of gradient descent, including stochastic, batch, and mini-batch GD.
In the next section, we'll examine polynomial regression models, which may be used to fit non-linear datasets. Then, we'll take a look at a few regularisation strategies that may be used to lessen the overfitting that is frequently observed in polynomial models.
We will now examine two prominent methods for classification tasks: softmax regression and logistic regression.
5. Support Vector Machines
A strong and versatile machine learning model, SVM may be used for classification, regression, and even outlier identification.
Complex small-to-medium-sized datasets are very well suited for SVMs. The fundamental ideas of SVMs, as well as how they function and are used, are covered in this chapter.
6. Decision Trees
We will first go through decision tree training, validation, and prediction in this chapter.
The Scikit-Learn CART training algorithm will next be covered. We'll go through regularising trees and applying them to regression challenges. Finally, we will talk about some decision tree constraints.
7. Ensemble Learning and Random Forests
Imagine that we survey thousands of people with a random question, then compile their responses. We frequently discover that this collective response is superior to an answer from a subject matter expert (really). The wisdom of the multitude refers to this.
Similarly to this, we frequently obtain better predictions than the best individual predictor if we combine the predictions of several models (such as classifiers or regressors).
An ensemble of predictors is a collection of them. As a result, this method is referred to as ensemble learning, and an algorithm for ensemble learning is referred to as an ensemble method.
We may train several decision tree classifiers as an illustration of an ensemble technique, with each classifier using a random portion of the training data. The term "random forest" refers to this collection of decision trees.
The most well-known ensemble learning techniques, including bagging, boosting, and stacking, will be covered in this chapter.
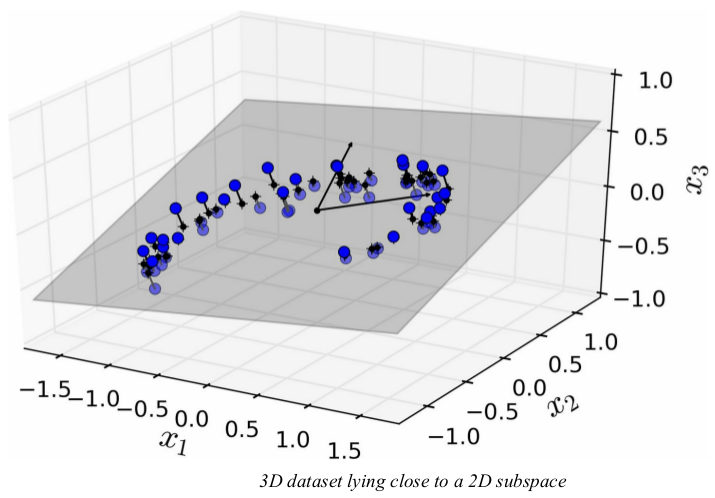
8. Dimensionality Reduction
This chapter will cover the following topics:
- Curse of dimensionality
- Understanding of high-dimensional space
- Dimensionality reduction approaches: Projection and Manifold Learning
- Dimensionality reduction techniques: LLE, PCA, and Kernel PCA.
9. Unsupervised Learning Techniques
We will examine two unsupervised learning tasks in this chapter:
- Clustering
- Anomaly Detection