How to remove duplicates in SQL
Introduction
- There are some specific rules that needs to be followed while creating the database objects. To improve the performance of a database, a primary key, clustered and non-clustered indexes, and constraints should be assigned to a table. Though we follow all these rules, duplicate rows may still occur in a table.
- It is always a good practice to make use of the database keys. Using the database keys will reduce the chances of getting duplicate records in a table. But if duplicate records are already present in a table, there are specific ways that are used to remove these duplicate records.
Ways to remove Duplicate Rows
- Use of DELETE JOIN statement to remove duplicate rows
DELETE JOIN statement is provided in MySQL that helps to remove duplicate rows from a table.
Consider a database with the name "studentdb”. We will create a table student into it.
mysql> USE studentdb;
Database changed
mysql> CREATE TABLE student (Stud_ID INT, Stud_Name VARCHAR(20), Stud_City VARCHAR(20), Stud_email VARCHAR(255), Stud_Age INT);
Query OK, 0 rows affected (0.15 sec)
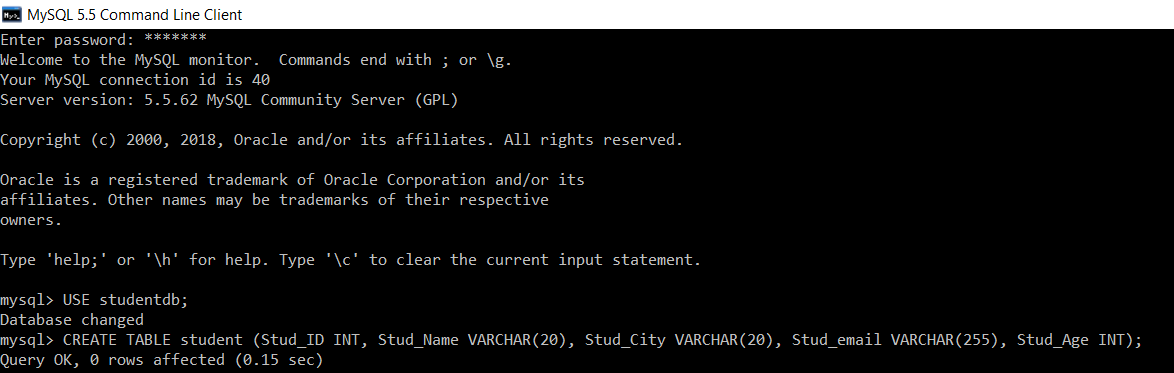
We have successfully created a 'student' table in the 'studentdb' database.
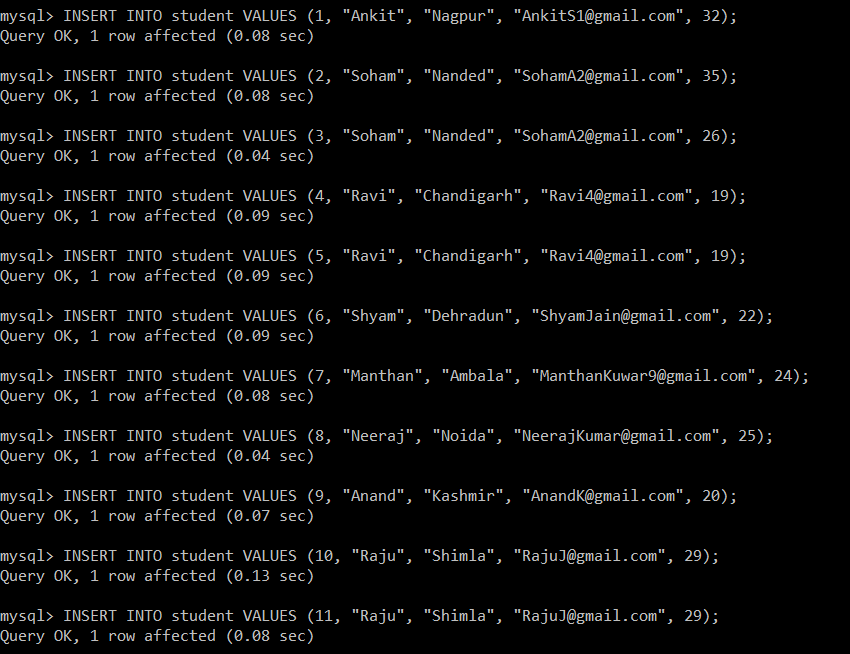
Now, we will write the following queries to insert data in the student table.
mysql> INSERT INTO student VALUES (1, "Ankit", "Nagpur", "[email protected]", 32);
Query OK, 1 row affected (0.08 sec)
mysql> INSERT INTO student VALUES (2, "Soham", "Nanded", "[email protected]", 35);
Query OK, 1 row affected (0.08 sec)
mysql> INSERT INTO student VALUES (3, "Soham", "Nanded", "[email protected]", 26);
Query OK, 1 row affected (0.04 sec)
mysql> INSERT INTO student VALUES (4, "Ravi", "Chandigarh", "[email protected]", 19);
Query OK, 1 row affected (0.09 sec)
mysql> INSERT INTO student VALUES (5, "Ravi", "Chandigarh", "[email protected]", 19);
Query OK, 1 row affected (0.09 sec)
mysql> INSERT INTO student VALUES (6, "Shyam", "Dehradun", "[email protected]", 22);
Query OK, 1 row affected (0.09 sec)
mysql> INSERT INTO student VALUES (7, "Manthan", "Ambala", "[email protected]", 24);
Query OK, 1 row affected (0.08 sec)
mysql> INSERT INTO student VALUES (8, "Neeraj", "Noida", "[email protected]", 25);
Query OK, 1 row affected (0.04 sec)
mysql> INSERT INTO student VALUES (9, "Anand", "Kashmir", "[email protected]", 20);
Query OK, 1 row affected (0.07 sec)
mysql> INSERT INTO student VALUES (10, "Raju", "Shimla", "[email protected]", 29);
Query OK, 1 row affected (0.13 sec)
mysql> INSERT INTO student VALUES (11, "Raju", "Shimla", "[email protected]", 29);
Query OK, 1 row affected (0.08 sec)
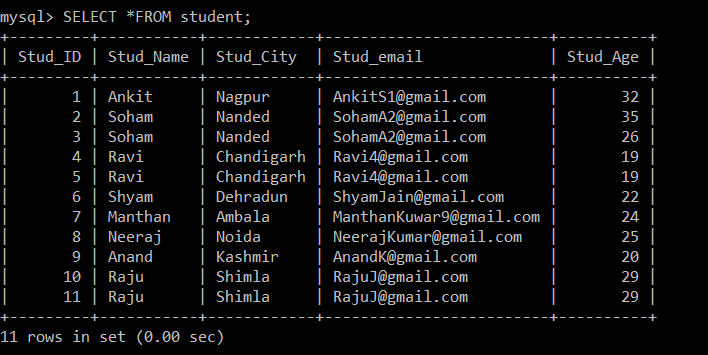
Now, we will retrieve all the records from the student table. We will consider this table and database for all the following examples.
mysql> SELECT *FROM student;
+---------+-----------+------------+-------------------------+----------+
| Stud_ID | Stud_Name | Stud_City | Stud_email | Stud_Age |
+---------+-----------+------------+-------------------------+----------+
| 1 | Ankit | Nagpur | [email protected] | 32 |
| 2 | Soham | Nanded | [email protected] | 35 |
| 3 | Soham | Nanded | [email protected] | 26 |
| 4 | Ravi | Chandigarh | [email protected] | 19 |
| 5 | Ravi | Chandigarh | [email protected] | 19 |
| 6 | Shyam | Dehradun | [email protected] | 22 |
| 7 | Manthan | Ambala | [email protected] | 24 |
| 8 | Neeraj | Noida | [email protected] | 25 |
| 9 | Anand | Kashmir | [email protected] | 20 |
| 10 | Raju | Shimla | [email protected] | 29 |
| 11 | Raju | Shimla | [email protected] | 29 |
+---------+-----------+------------+-------------------------+----------+
11 rows in set (0.00 sec)
Example 1:
Write a query to delete duplicate rows from the student table using the DELETE JOIN statement.
mysql> DELETE s1 FROM student s1 INNER JOIN student s2 WHERE s1.Stud_ID < s2.Stud_ID AND s1.Stud_email = s2.Stud_email;We have used the DELETE query with INNER JOIN. To implement the INNER JOIN on a single table, we have created two instances s1 and s2. Then, with the help of WHERE clause, we have checked two conditions to find out the duplicate rows in the student table. If the email id in two different records is the same and the student id is different, it will be treated as a duplicate record according to the WHERE clause condition.
Output:
Query OK, 3 rows affected (0.20 sec)The results of the above query show that there are three duplicate records present in the student table.

We will use the SELECT query to find the duplicate records which were deleted.
mysql> SELECT *FROM student;
+---------+-----------+------------+-------------------------+----------+
| Stud_ID | Stud_Name | Stud_City | Stud_email | Stud_Age |
+---------+-----------+------------+-------------------------+----------+
| 1 | Ankit | Nagpur | [email protected] | 32 |
| 3 | Soham | Nanded | [email protected] | 26 |
| 5 | Ravi | Chandigarh | [email protected] | 19 |
| 6 | Shyam | Dehradun | [email protected] | 22 |
| 7 | Manthan | Ambala | [email protected] | 24 |
| 8 | Neeraj | Noida | [email protected] | 25 |
| 9 | Anand | Kashmir | [email protected] | 20 |
| 11 | Raju | Shimla | [email protected] | 29 |
+---------+-----------+------------+-------------------------+----------+
8 rows in set (0.00 sec)
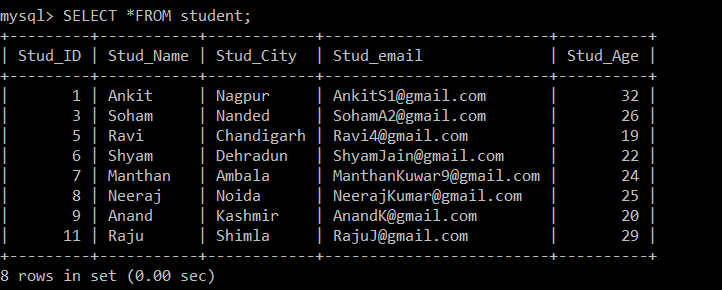
Now, there are only 8 records that are present in the student table as the three duplicate records are deleted from the currently selected table. According to the following condition:
s1.Stud_ID < s2.Stud_ID AND s1.Stud_email = s2.Stud_email;If the email ids of any two records are the same, then since the less than sign is used between the student id, only the record with greater employee IDs will be kept, and the other duplicate record will be deleted between the two records.
Example 2:
Write a query to delete duplicate rows from the student table using the delete join statement while keeping the duplicate record with a lesser employee id and deleting the other one.
mysql> DELETE s1 FROM student s1 INNER JOIN student s2 WHERE s1.Stud_ID > s2.Stud_ID AND s1.Stud_email = s2.Stud_email;We have used the DELETE query with INNER JOIN. To implement the INNER JOIN on a single table, we have created two instances s1 and s2. Then, with the help of the WHERE clause, we have checked two conditions to find out the duplicates rows in the student table. If the email id present in two different records is the same and the student id is different, it will be treated as a duplicate record according to the WHERE clause condition.
Output:
Query OK, 3 rows affected (0.09 sec)The results of the above query show that there are three duplicate records present in the student table.
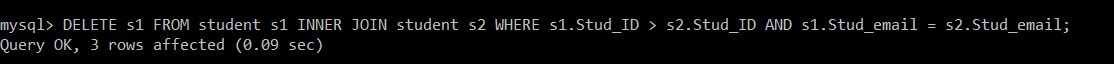
We will use the SELECT query to find the duplicate records which were deleted.
mysql> SELECT *FROM student;
+---------+-----------+------------+-------------------------+----------+
| Stud_ID | Stud_Name | Stud_City | Stud_email | Stud_Age |
+---------+-----------+------------+-------------------------+----------+
| 1 | Ankit | Nagpur | [email protected] | 32 |
| 2 | Soham | Nanded | [email protected] | 35 |
| 4 | Ravi | Chandigarh | [email protected] | 19 |
| 6 | Shyam | Dehradun | [email protected] | 22 |
| 7 | Manthan | Ambala | [email protected] | 24 |
| 8 | Neeraj | Noida | [email protected] | 25 |
| 9 | Anand | Kashmir | [email protected] | 20 |
| 10 | Raju | Shimla | [email protected] | 29 |
+---------+-----------+------------+-------------------------+----------+
8 rows in set (0.00 sec)
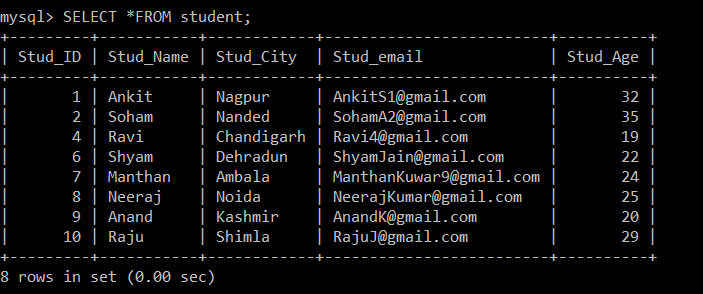
Now, there are only 8 records that are present in the student table as the three duplicate records are deleted from the currently selected table. According to the following condition:
s1.Stud_ID > s2.Stud_ID AND s1.Stud_email = s2.Stud_email;If the email ids of any two records are the same since the greater than sign is used between the student id, only the record with the lesser employee id will be kept, and the other duplicate record will be deleted among the two records.
- Use of an intermediate table to remove duplicate rows
The following steps should be followed while removing the duplicate rows with the help of an intermediate table.
- A new table should be created, which will be the same as the actual table.
- Add distinct rows from the actual table to the newly created table.
- Drop the actual table and rename the new table with the same name as an actual table.
Example:
Write a query to delete the duplicate records from the student table by using an intermediate table.
Step 1:
Firstly, we will create an intermediate table that will be the same as the employee table.
mysql> CREATE TABLE temp_student LIKE student;
Query OK, 0 rows affected (0.14 sec)

Here, ‘employee’ is the original table and ‘temp_student’ is the intermediate table.
Step 2:
Now, we will fetch only the unique records from the student table and insert all the fetched records into the temp_student table.
mysql> INSERT INTO temp_student SELECT *FROM student GROUP BY Stud_email;
Query OK, 8 rows affected (0.12 sec)
Records: 8 Duplicates: 0 Warnings: 0

Here, before inserting the distinct records from the student table into temp_student, all the duplicate records are filtered by Stud_email. Then, only the records with unique email id have inserted into temp_student.
Step 3:
Then, we will remove the student table and rename the table temp_student to the student table.
mysql> DROP TABLE student;
Query OK, 0 rows affected (0.08 sec)
mysql> ALTER TABLE temp_student RENAME TO student;
Query OK, 0 rows affected (0.08 sec)
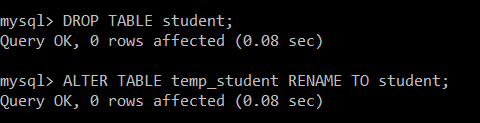
The student table is removed successfully, and temp_student is renamed to the student table, which contains only the unique records.
Then, we need to verify that the student table now contains only the unique records. To verify this, we have used the SELECT query to see the data contained in the student table.
mysql> SELECT *FROM student;Output:
+---------+-----------+------------+-------------------------+----------+
| Stud_ID | Stud_Name | Stud_City | Stud_email | Stud_Age |
+---------+-----------+------------+-------------------------+----------+
| 9 | Anand | Kashmir | [email protected] | 20 |
| 1 | Ankit | Nagpur | [email protected] | 32 |
| 7 | Manthan | Ambala | [email protected] | 24 |
| 8 | Neeraj | Noida | [email protected] | 25 |
| 10 | Raju | Shimla | [email protected] | 29 |
| 4 | Ravi | Chandigarh | [email protected] | 19 |
| 6 | Shyam | Dehradun | [email protected] | 22 |
| 2 | Soham | Nanded | [email protected] | 35 |
+---------+-----------+------------+-------------------------+----------+
8 rows in set (0.00 sec)
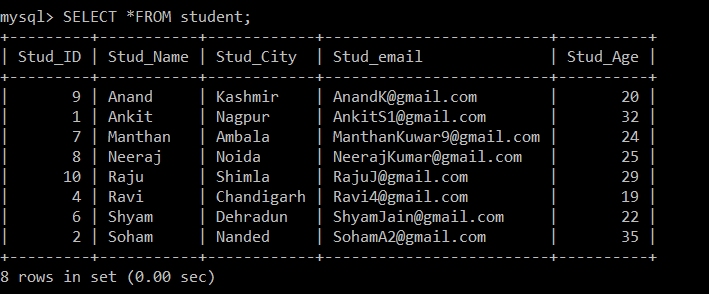
Now, there are only 8 records that are present in the student table as the three duplicate records are deleted from the currently selected table. In step 2, while fetching the distinct records from the original table and inserting them into an intermediate table, a GROUP BY clause was used on Stud_email, so all the records were inserted based on the email ids of students. Here, only the record with a lower employee id is kept among the duplicate records by default, and the other one is deleted.