KNN vs K-Means
KNN stands for K-nearest neighbour’s algorithm. It can be defined as the non-parametric classifier that is used for the classification and prediction of individual data points. It uses data and helps in classifying new data points on the basis of its similarity. These types of methods are mostly used in solving problems based on classifications and regressions. KNN is also referred to as the Lazy Learner Algorithm as it stores the new data during the time of the classification process rather than learning through the training.
KNN refers to the oldest method of an algorithm, it is also the most accurate one where both the classification and regression pattern was used. It stores data according to the categories present. The main reason why we need of a KNN algorithm is that it helps in identifying categories and classes of datasets or data points.
There are various ways for choosing the best value of k in KNN, which are listed below:
- Firstly, divide the data into train and tuning (validation) sets. Test sets are not used for this kind of purpose. Now the validation set is used in order to tune the k and find the one that works for the type of problem.
- Another method to be used is the Schwarz Criterion.
The Schwarz Criterion picks k by minimizing: distortion + λDk log N.
D = problems of dimension, k = clusters number, N = the number of data points, λ = parameter to be specified.
It is kept in mind that, whenever λ tends to be 0; we are neither penalizing nor having a large number of cluster centers. A trivial clustering achieves zero distortion by the method of putting a cluster center at each data point. When λ tends to infinity, the penalty of one extra cluster will dominate the distortion and we will have to do with the least amount of clusters possible (k = 1)
- An Elbow method is also used to find the value of k in k means algorithms.
Features of KNN
Some of the features are:
1. It does not focus on learning new data models.
2. It helps in storing training datasets.
3. It makes an accurate prediction.
Advantages of the KNN Algorithm
The advantages of the KNN algorithm are:
- It can be easily implemented.
- It does not consist of any machine learning algorithm.
- It proves to be more effective in large data training.
- KNN leads to high accuracy of predictions.
- It does not require the tuning parameters.
Disadvantages of KNN
Some of the disadvantages of KNN are:
- it does not perform well when large datasets are included.
- it needs to find the value of k.
-it requires higher memory storage.
-it has a high cost.
-its accuracy is highly dependent on the quality of the data.
KNN Algorithm
The algorithm for KNN:
1. First, assign a value to k.
2. Second, we calculate the Euclidean distance of the data points, this distance is referred to as the distance between two points.
3. On calculation we get the nearest neighbor.
4. Now count the number of data points of each category in the neighbor.
5. Lastly, new data points are assigned to the particular category for the maximum number.
Where to use KNN Algorithm?
Some of the areas where KNN algorithms is being used are:
1. For loan approval
The KNN algorithm helps in the identification of individuals who default on loans by the comparison made between the individuals on the bases of their traits.
2. In pattern recognition
KNN helps in categorizing data such that it is identified by its pattern. The data is arranged in different categories which makes identification simple and easy.
3. In data preprocessing
The KNN algorithm helps in the process of finding the missing values as the dataset consists of missing values therefore it comprises a process known as Missing Data Imputation.
4. Credit rating
By using the KNN algorithm we can compare similar characteristics for the rating of an individual’s credit.
5. In stock price prediction
As mentioned earlier KNN is mostly used in prediction, so it is used in predicting future stocks value by keeping a check on the historical data.
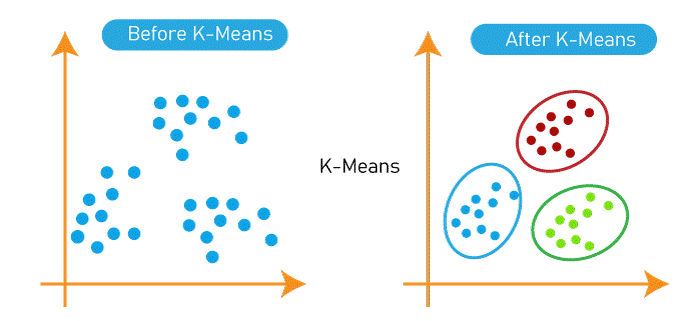
K-mean
K-mean which is also referred to as K-mean clustering it is defined as a process of learning algorithm which clusters similar types of data. It is one of the simplest machine learning algorithms. In k-means the k number is first identified and then the data points are allocated to the nearest cluster such that the centroids are kept as small as possible.
The main purpose of the k-means algorithm is that it is used for creating and analyzing cluster processes. Clustering is generally referred to the organizing of data in classes such that it comprises high and low inter-classes. The data points are clustered on the bases of similarity. K-means clustering algorithms are a very effective way of grouping data. It is an algorithm that is used for partitioning n points to k clusters in such a way that each point belongs to the cluster which comprises the nearest mean or the nearest center. K-means has been used for many years and it's still being widely used today. However, it is not always the best choice for all problems. It can be difficult to use if we are using smaller datasets or if we have more complex data.
K-means Algorithm
The algorithm used for k-mean are:
Step 1: First we select the number for clusters.
Step 2: Now we can select any random dataset for the k point.
Step 3: In order to predefine the k-clusters we assign data to the closest centroid.
Step 4: Now the variance is calculated and placed on the centroids of each cluster.
Step 5: the third step is repeated where we reassigned each datapoint.
Step 6: if the reassignment occurs, then step 4 is repeated or the process is ended.
Uses of K-Means
Some of its basic applications are:
- It is used in document classification or clustering such that the documents are easily identified and grouped on a particular basis.
- It helps in the identification of crime scenes and areas.
- It helps in analyzing call records, or messages of an individual.
- It can detect fraud insurance.
- It is used for customer segmentation such that it helps in fulfilling the company's target.
Advantages of K-mean
Some of the advantages of k-means are:
- It proves to be effective in large data collection.
- It is easy to implement.
- It can be easily used in large sets of data.
- It does not lead to overloading.
-It runs quickly because of its linear nature.
Disadvantage of K-mean
Some of the disadvantages of k-mean are:
- It is sensitive to initialization.
- It has a limited number of fixed data.
- The specification is required for the clusters in advance.
- It finds difficulty in handling outliers.
- It leads to a random selection of the centroid.
- It can be inconsistent.
Difference between KNN and K-mean
| KNN | K-Mean |
| KNN is supervised machine learning algorithm. - | K-means is unsupervised machine learning. |
| ‘K’ in KNN stands for the nearest neighboring numbers. | “K” in K-means stands for the number of classes. |
| It is based on classifications and regression. | K-means is based on the clustering. |
| It is also referred to as lazy learning. | k-means is referred to as eager learners. |
| It is better in performance when k-mean. | its performance is lower than compared to KNN. |
| Classes are in-built. | Classes are needed to create. |
| it is mainly used for classification and regression of data where the targeted value is already known. | It is used for demographics of populations, in social media, in market segmentation, and many more. |
| KNN has the benefit if it performs on data that are having the same scale. | K-means does not prove to be beneficial in such a case. |
Conclusion
Both KNN and K-Mean are machine learning algorithms. KNN and K-mean are both very useful for machine learning, but each has its own strengths and weaknesses. K-mean is good at predicting future datapoints, but it doesn't work well when the data points are similar to those in the training set. KNN can handle a wide variety of data types, but it doesn't work well when there are many different types of features or if there's not enough data in each feature dimension. In general, K-means is better in comparison to KNN have a small amount of training data and a large number of features; however, if one has more training data or fewer features, then KNN turns out to perform better. It also makes the process fast, easier, and simple. It groups and labels the data in such a way that no complexity is being formed. K-means is also used for business purposes and banking.