Semi-Supervised Machine Learning
A model is developed by using both labeled and unlabeled data in a process which is known as semi-supervised machine learning. While using a collection of labeled data, the algorithms are in conventional supervised learning where one learns how to categorize fresh, unlabeled data. Since there are no labels in unsupervised learning, the algorithm must independently find patterns in the data.
Between these two learning approaches is semi-supervised learning. To train a model, a small quantity of labeled data must be combined with a larger amount of unlabeled data. While the unlabeled data offer extra details on the data's structure, the labeled data offers some information about how to categorize the data.
Methods of Semi-Supervised Learning
There are several methods for semi-supervised learning and they are:
i) Self-training This method involves the initial teaching of an algorithm on labeled data, then applying the model to categorize unlabeled data and adding it to the labeled data for the subsequent training cycle.
ii) Co-training is the process of labeling some of the unlabeled data using one model, which is later utilized to train the other model after several models have been trained on various properties of the data.
iii) Methods that employ a graph representation of the data to propagate labels from labeled to unlabeled data based on the structure of the graph.
When the labeled data is difficult or expensive to collect but unlabeled data is easy to come by, semi-supervised learning which can be very helpful. Semi-supervised learning can help machine learning models perform better by using this unlabeled data, especially when there is a shortage of labeled data.
Semi-Supervised Learning Applications
Some of the uses or applications are:
1. Speech Analysis: Because labeling audio recordings is such a difficult operation, semi-supervised learning is a highly logical solution.
2. Classifying the content of websites: Since labeling every webpage would be impractical and impossible, semi-supervised learning methods are used instead. Even the Google search engine ranks the appropriateness of a webpage for a particular query using a variation of semi-supervised learning.
3. Protein Sequence Classification: The development of semi-supervised learning has been expected in this sector since DNA strands are frequently quite big in size.
4. Large-scale text data categorization is possible using semi-supervised learning. The algorithm may be trained to classify the data with high accuracy by utilizing a small amount of labeled data and a larger number of unlabeled data.
5. For applications requiring picture identification, semi-supervised learning is an option. Large volumes of picture data must often be labeled, which may be expensive and time-consuming. Semi-supervised learning enables the system to be trained on both more unlabeled data and fewer labeled data samples.
6. Fraud detection: In the financial sector and other businesses, semi-supervised learning may be used to identify fraud. The program can find patterns of fraudulent behavior that might not be immediately visible by using both labeled and unlabeled data.
7. Natural Language Processing: Natural Language Processing (NLP) activities including sentiment analysis, language translation, and speech recognition frequently employ semi-supervised learning. The program can learn the basic structures and patterns of the language by using unlabeled input.
8. Recommender Systems: Recommender systems, which propose goods or services to clients based on their behavior, may be developed using semi-supervised learning. The algorithm may learn about user preferences and enhance the precision of its suggestions by using both labeled and unlabeled data.
Disadvantages of Semi Supervised Learning
Its disadvantages are as follows;
1. Limited increase in accuracy: Semi-supervised learning can raise machine learning model accuracy, but the increase may not be as great as in supervised learning, which uses a bigger labeled dataset.
2. Dependence on unlabeled data quality: Semi-supervised learning techniques are very dependent on unlabeled data quality. The model's accuracy may suffer if the unlabeled data is irregular or pointless.
3. Complexity: The implementation and control of semi-supervised learning algorithms prove to be challenging. It can be difficult to choose the suitable method, adjust the algorithm's parameters, and choose the appropriate ratio of labeled to unlabeled data.
4. Limited applicability: Not all machine learning issues lead to semi-supervised learning. It might not be effective, for example, when there is little to no connection between the labeled and unlabeled data.
Importance of Semi-Supervised learning
Semi-supervised machine learning is important as it combines both labeled and unlabeled data for the improvement of machine learning model performances.
Some of its importance are mentioned below;
1. Cost-effectiveness: Labeling data requires hiring human editors or experts in the field, which may be an expensive operation. Semi-supervised learning greatly minimizes the cost of manual annotation by using unlabeled data, hence reducing the dependency on labeled data.
2. Scalability: Obtaining labeled data for every training sample is sometimes impossible or costly in real-world situations. By utilizing the huge amounts of often available unlabeled data, semi-supervised learning allows the construction of scalable models by permitting the training of models on considerably bigger datasets.
3. Using unlabeled data: Unlabeled data is typically plentiful and simple to create. This unlabeled data can be used in the training phase to enhance generalization and model performance. Unlabeled data offer important details about the distribution and underlying structure of the data, which may be used to improve the model's capacity to generalize to new, unobserved samples.
4. Increased precision: Semi-supervised learning can increase the precision and durability of machine learning models by making use of the extra information offered by unlabeled data. Utilizing unlabeled input enables models to develop more meaningful and unfair representations, improving prediction accuracy and decision boundaries.
5. Domain adaptation: Often, labeled data from a domain other than the one in which the model will be used may be accessible. By utilizing unlabeled data from the target domain, semi-supervised learning can assist close the domain gap by enabling the model to more effectively generalize and adapt to the chosen area of interest.
6. Active learning: To choose the most informative data points for labeling, active learning strategies can be paired with semi-supervised learning. The model can attain improved accuracy with fewer labeled instances by repeatedly choosing the most problematic or typical unlabeled samples and adding them to the labeled set.
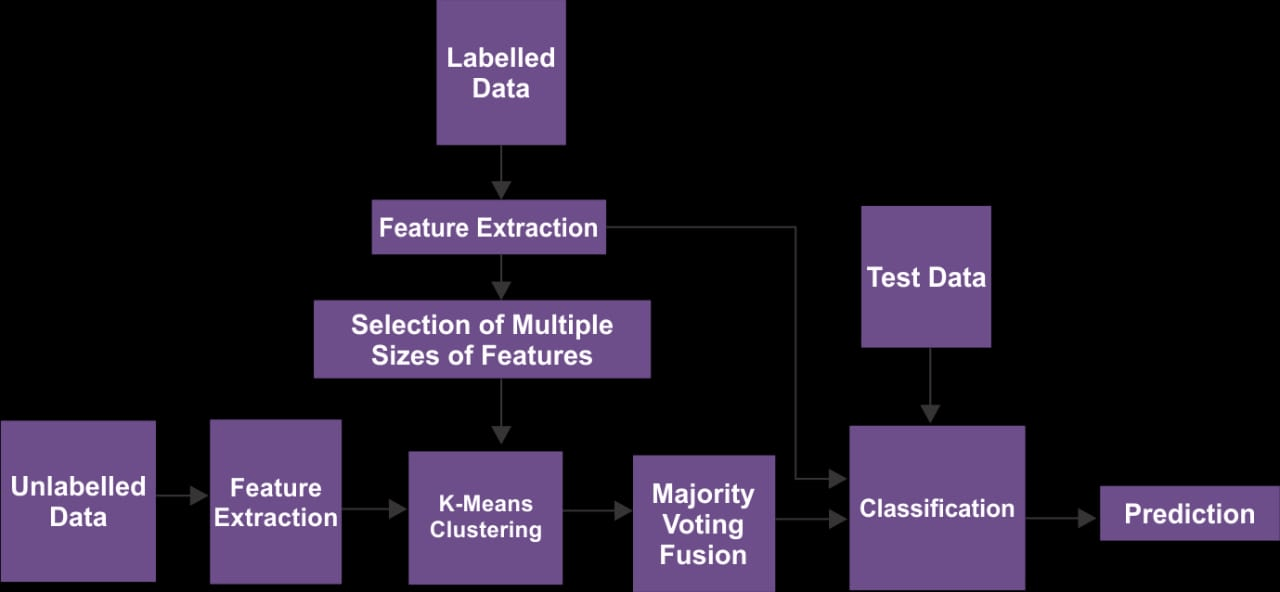
Working on Semi-Supervised Machine Learning
1. Creating the dataset: The first step is to compile a dataset with examples that are both labeled and unlabeled. Unlabeled data simply contains input features, whereas labeled data includes input features and the target labels that correspond to them.
2. Using supervised learning approaches, the model is initially trained using the labeled data that is readily available. In this stage, the model parameters are optimized to reduce the mismatch between the predicted labels and the actual labels.
3. Iterative training: Using both the labeled and unlabeled data, the model is retrained while taking into account the knowledge gained from the unsupervised learning methods. The model steadily improves its performance by using the extra unlabeled data, and this procedure is often done iteratively.
4. Evaluation and forecasting: After the model has been trained using a semi-supervised learning strategy, it may be assessed using labeled data that was not utilized in the training phase. The learnt representations from both labeled and unlabeled samples may then be used by the model to generate predictions on fresh, new data.
5. Using unlabeled data: The model gets access to the unlabeled data after training with labeled data. Their main objective is to gain meaningful information from this data in order to boost the performance of the model.
6. Including unsupervised learning methods: Unsupervised learning methods, such as grouping or reducing dimensionality are frequently used on unlabeled data. These methods serve in finding trends, structures, or connections in the unlabeled data.
Conclusion
Not all supervised learning problems are appropriate for semi-supervised learning. As with handwritten numbers, clustering algorithms should be able to distinguish between classes. As an alternative, one must have a sufficient number of labeled examples that adequately depict the data generation process for the issue area.
Data labeling jobs are unfortunately not going away anytime soon because so many real-world applications belong to that category.
However, semi-supervised learning has a wide range of uses in fields where data labeling may be automated, such as uncomplicated image classification and document classification.
Due to the fact that it uses vast amounts of unlabeled data, improves machine learning capabilities, decreases costs, boosts scalability, and increases model accuracy and generalization, semi-supervised learning is essential. When labeled data is scarce or expensive to collect, it proves to be very helpful. It's crucial to note that depending on the particular algorithm or methodology utilized, the precise approaches and techniques used in semi-supervised learning might change.